[논문리뷰] SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wai-Chung Kwan, Aryo Pradipta Gema, Joshua Ong Jun Leang, Pasquale Minervini
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- SCOPE: 본 논문에서 제안하는 데이터(curated prompts) 없이 오픈형 과제(open-ended tasks)를 학습하기 위한 Self-play 프레임워크입니다.
- Rubric-based Reward: 오픈형 과제의 모호한 정답을 다루기 위해, 과제별 평가 기준(criterion)을 자연어로 생성하고 이를 바탕으로 정량적 점수를 산출하는 보상 시스템입니다.
- Co-evolving Policies: 과제 생성 역할을 맡은 Challenger와 이를 해결하는 Solver가 서로의 성능을 고려하며 함께 학습하여, Solver의 역량 향상에 따라 Challenger가 점진적으로 더 어려운 과제를 제시하는 상호 진화 구조입니다.
- Self-judge: 모델의 초기 버전(frozen copy)을 사용하여 데이터 외부로부터 과제별 Rubric을 생성하고 Solver의 결과물을 채점하는 고정된 평가자입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 연구는 기존 LLM의 Self-play가 수학, 코드 등 규칙 검증이 가능한 도메인에 한정되어 있으며, 오픈형 과제에서는 외부 데이터나 Frontier Model에 대한 의존성을 벗어나지 못한다는 문제점을 해결하고자 합니다. 기존 방식은 인간이 큐레이팅한 Prompt나 더 강력한 모델의 평가(Judge)에 의존하므로, 인간 지능의 한계 내에서만 학습이 가능하다는 제약이 있습니다. 따라서 모델이 스스로 과제를 생성하고, 스스로 평가하며, 그 과정에서 지속적으로 역량을 향상할 수 있는 범용적인 데이터 독립적 Self-play 방식이 필요합니다 [Table 1].
## 3. Method & Key Results (제안 방법론 및 핵심 결과) SCOPE는 문서 기반(document-grounded) 오픈형 과제를 생성하는 Challenger, 이를 Multi-turn retrieval로 해결하는 Solver, 그리고 이를 채점하는 고정된 Judge로 구성된 Co-evolution 프레임워크입니다 [Figure 1]. 학습 루프는 Challenger가 Solver의 역량에 맞춰 과제를 생성하고, Judge가 작성한 Rubric에 따라 Solver가 Retrieval-Augmented Generation(RAG)을 수행하여 보상을 최대화하는 방식으로 진행됩니다. 특히, Quality gate와 Cosine length penalty를 도입하여 Reward hacking을 방지하고 안정적인 학습을 보장합니다 [Figure 2].
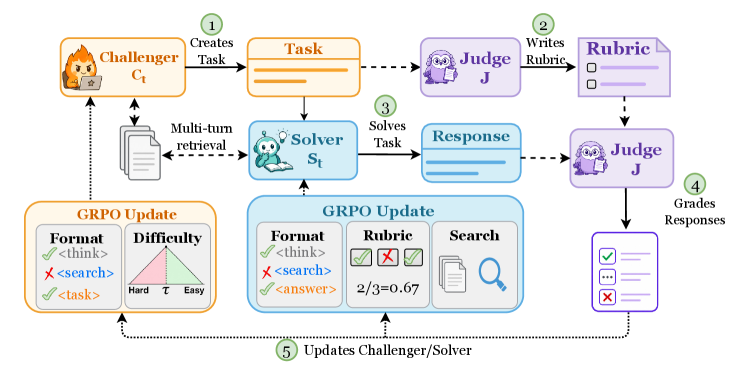
Figure 1 — SCOPE 프레임워크 개요
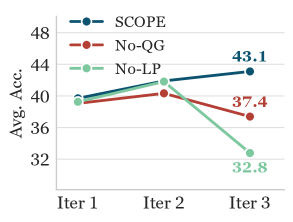
Figure 2 — Reward 설계 Ablation
실험 결과, SCOPE는 Qwen2.5-7B, Qwen3-8B, OLMo-3-7B 모델에서 외부 데이터 없이도 약 9,000개의 큐레이팅된 프롬프트로 학습된 GRPOdata 모델과 동등하거나 우수한 성능을 보였습니다. 8개 오픈형 과제 벤치마크에서 기존 대비 최대 +10.4점 향상되었으며, 특히 학습하지 않은 Short-form QA에서도 최대 +13.8점의 성능 향상을 기록하여 광범위한 일반화 능력을 입증했습니다 [Table 2, Table 3]. 이는 기존 연구들보다 더 균형 잡힌 성능을 보이며, 대규모 데이터 의존성을 탈피할 수 있는 가능성을 제시합니다 [Table 8].
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 데이터 독립적인 Self-play를 오픈형 과제로 성공적으로 확장하여, 외부 감독 없이도 모델이 지속적인 자가 개선을 이룰 수 있음을 입증했습니다. 특히 Challenger와 Solver의 공동 진화 과정에서 Retrieval과 Synthesis 능력이 동시에 향상됨을 확인하였으며, Rubric 생성이 평가의 병목 현상임을 규명했습니다. 이 연구는 AI 학습 생태계에서 인간 감독 의존도를 줄이고 모델이 스스로 고차원적인 지적 역량을 개발하게 하는 새로운 방향성을 제시하여, 산업계와 학계 모두에서 데이터 효율적인 자가 학습 모델 개발에 크게 기여할 것입니다.
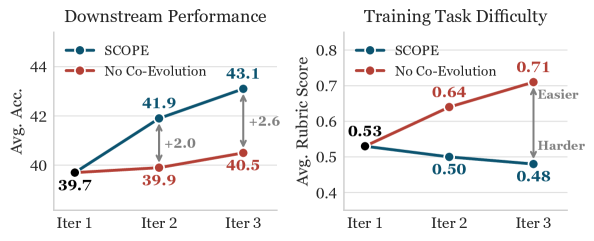
Figure 3 — Co-evolution 효과 분석
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
- [논문리뷰] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
- [논문리뷰] LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
- [논문리뷰] Co-Evolving LLM Decision and Skill Bank Agents for Long-Horizon Tasks
Review 의 다른글
- 이전글 [논문리뷰] SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
- 현재글 : [논문리뷰] SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks
- 다음글 [논문리뷰] Seeing Isn't Knowing: Do VLMs Know When Not to Answer Spatial Questions (and Why)?
댓글