[논문리뷰] LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nianyi Lin, Jiajie Zhang, Lei Hou, Juanzi Li
1. Key Terms & Definitions (핵심 용어 및 정의)
- Rubric Reward: 최종 정답의 정확성뿐만 아니라, 추론 과정에서 활용된 골드 엔티티(Gold entities)의 호출 빈도를 측정하여 세밀한 과정 감독(Process supervision)을 제공하는 보상 체계입니다.
- Tiered Distractors: 탐색 에이전트(Search agent)의 경로를 기반으로 분류한 방해 정보(Distractor)입니다. 에이전트가 읽었으나 인용하지 않은 문서는 Tier-1(High confusability), 검색 결과에 등장했으나 클릭하지 않은 문서는 Tier-2(Low confusability)로 정의하여 데이터의 난이도를 높입니다.
- GRPO (Group Relative Policy Optimization): 다수의 출력 후보군을 생성하고, 이들의 보상을 그룹 내에서 정규화(Normalization)하여 최적화하는 정책 학습 알고리즘입니다.
- Positive-only Strategy: Rubric Reward를 정답을 맞춘 응답에만 부여함으로써, 잘못된 추론 경로로 정답을 맞히는 'reward hacking'을 방지하고 정확한 근거 기반 추론을 유도하는 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 long-context 강화학습이 가진 데이터의 낮은 난이도와 보상 신호의 희소성(Sparsity) 문제를 해결하고자 합니다. 기존 연구들은 주로 랜덤하게 샘플링된 방해 정보를 사용하거나, 최종 정답 여부에만 기반한 outcome-only reward를 사용함으로써 모델이 중간 추론 단계를 건너뛰거나 잘못된 근거를 참조하는 현상을 방지하지 못합니다 [Figure 1]. 이러한 한계는 복잡한 다중 도약(Multi-hop) 추론이 필요한 실제 상황에서 모델의 할루시네이션(Hallucination)과 비효율적인 정보 통합 문제를 야기합니다. 따라서 저자들은 에이전트의 실제 탐색 경로를 활용한 현실적인 데이터 구축 파이프라인과, 추론 과정을 정밀하게 감독하는 새로운 보상 체계의 필요성을 제기합니다.

Figure 1 — 기존 RL 대비 LongTraceRL의 비교
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 탐색 에이전트의 경로를 이용해 Tiered Distractors를 구축하고, Rubric Reward를 통해 과정 감독을 수행하는 LongTraceRL을 제안합니다 [Figure 2]. 데이터 구축 단계에서는 Knowledge Graph Random Walk를 통해 복잡한 다중 도약 문제를 생성하고, 에이전트가 방문한 문서들의 행동 유형을 분석하여 높은 식별력을 요구하는 2단계 방해 정보를 포함시켰습니다. 학습 단계에서는 GRPO를 기반으로, 최종 정답의 정확성과 골드 엔티티 호출 여부를 결합한 복합 보상 함수를 정의하였으며, 이를 통해 모델이 정답 근거를 논리적으로 추적하도록 유도합니다. 실험 결과, LongTraceRL은 Qwen3-4B 모델에서 베이스라인 대비 평균 5.7 포인트 향상된 성능을 보였으며, 가장 강력한 기존 베이스라인인 LongRLVR보다 2.5 포인트 높은 성능을 기록했습니다 [Table 1]. 특히 추론 집약적인 AA-LCR 벤치마크에서 큰 폭의 향상을 보였으며, Rubric Reward와 Positive-only 전략이 각각 모델의 추론 경로 grounding과 reward hacking 방지에 기여함을 입증했습니다 [Table 2, Table 5]. 또한, LongTraceRL은 rollout 과정에서 더 길고 신중한 추론 패턴을 보이며, 이는 모델이 긴 컨텍스트 내에서 증거 기반 추론을 수행하게 함을 시사합니다 [Figure 3].
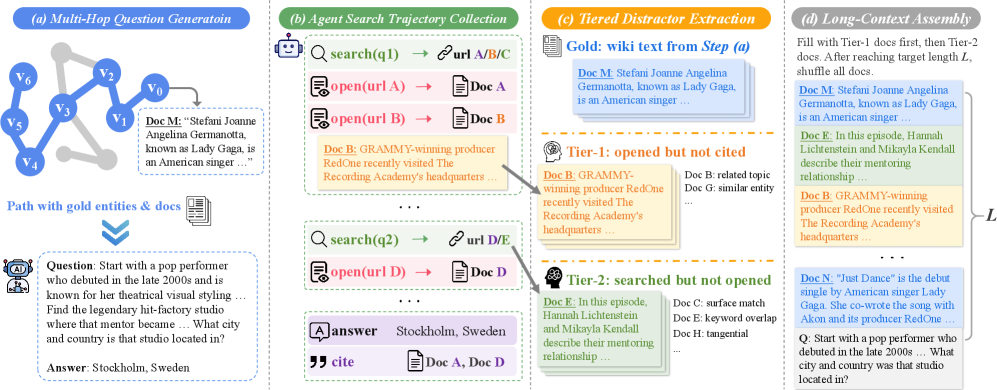
Figure 2 — 데이터 구축 파이프라인 개요
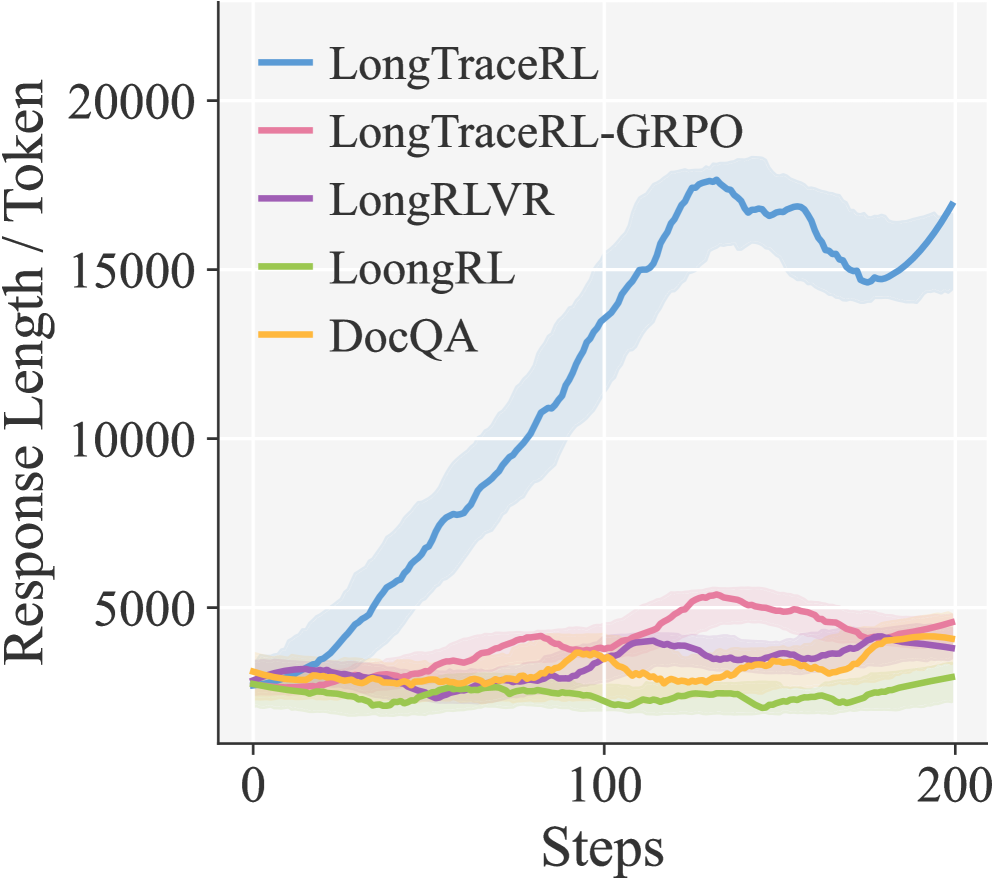
Figure 3 — 학습 중 응답 길이 및 보상 역학
4. Conclusion & Impact (결론 및 시사점)
본 논문은 에이전트 탐색 궤적을 활용한 데이터 구축과 엔티티 수준의 Rubric Reward를 결합한 LongTraceRL이 long-context 추론 성능을 크게 향상시킬 수 있음을 보여줍니다. 이 연구는 보상 신호가 희소한 상황에서 과정 감독(Process supervision)의 중요성을 학계에 시사하며, 특히 엔티티 기반의 미세 조정이 모델의 논리적 완결성을 어떻게 강화하는지 명확히 제시합니다. 향후 다양한 도메인의 문서나 더 고도화된 에이전트 모델에 적용함으로써, 더욱 복잡하고 긴 호흡의 정보 통합 및 추론 능력을 갖춘 LLM 개발에 기여할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GRASP: GRanularity-Aware Search Policy for Agentic RAG
- [논문리뷰] SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks
- [논문리뷰] Dynamic Long Context Reasoning over Compressed Memory via End-to-End Reinforcement Learning
- [논문리뷰] Step-DeepResearch Technical Report
- [논문리뷰] Understanding Reasoning from Pretraining to Post-Training
Review 의 다른글
- 이전글 [논문리뷰] LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
- 현재글 : [논문리뷰] LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
- 다음글 [논문리뷰] Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models
댓글