[논문리뷰] LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
링크: 논문 PDF로 바로 열기
메타데이터
저자: Kewei Xu, Xiaoben Lu, Shuofei Qiao, Zihan Ding, Haoming Xu, Lei Liang, Ningyu Zhang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Analytical State: 데이터 분석 과정에서 누적되는 코드 상태, 중간 결과, 정의된 필터, 매트릭 등을 포함하는 지속적인 분석 맥락.
- State-Evolution Patterns: 분석 과정 중 상태가 변화하는 6가지 주요 유형(Initial, Inheritance, Update, Counterfactual, Rollback, Composition).
- Dependency Span: 현재 분석 턴이 의존하고 있는 가장 먼 과거 턴까지의 거리(턴 수).
- Cascade Error: 이전 턴의 오류가 현재 턴으로 전파되어 발생하는 오류.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 실제 데이터 분석은 단일 단계가 아닌, 긴 세션 동안 상태가 지속적으로 축적되고 변화하는 반복적 과정입니다. 그러나 기존 데이터 분석 벤치마크는 주로 독립적이거나 짧은 인터랙티브 작업만을 평가하여, 복잡한 분석 세션 속에서 상태를 추적하고 수정하는 에이전트의 능력을 충분히 테스트하지 못합니다 [Figure 1]. 저자들은 에이전트가 시간이 흐름에 따라 변화하는 analytical state를 유지, 업데이트, 복구하는 능력이 부족하다는 점을 핵심 문제로 정의합니다. 기존 연구들은 환경이 리셋되는 독립적인 작업에 집중하거나, 가이드가 명확한 작업만을 다루어 실제 환경에서의 장기적인 분석 의존성을 반영하지 못한다는 한계가 있습니다.
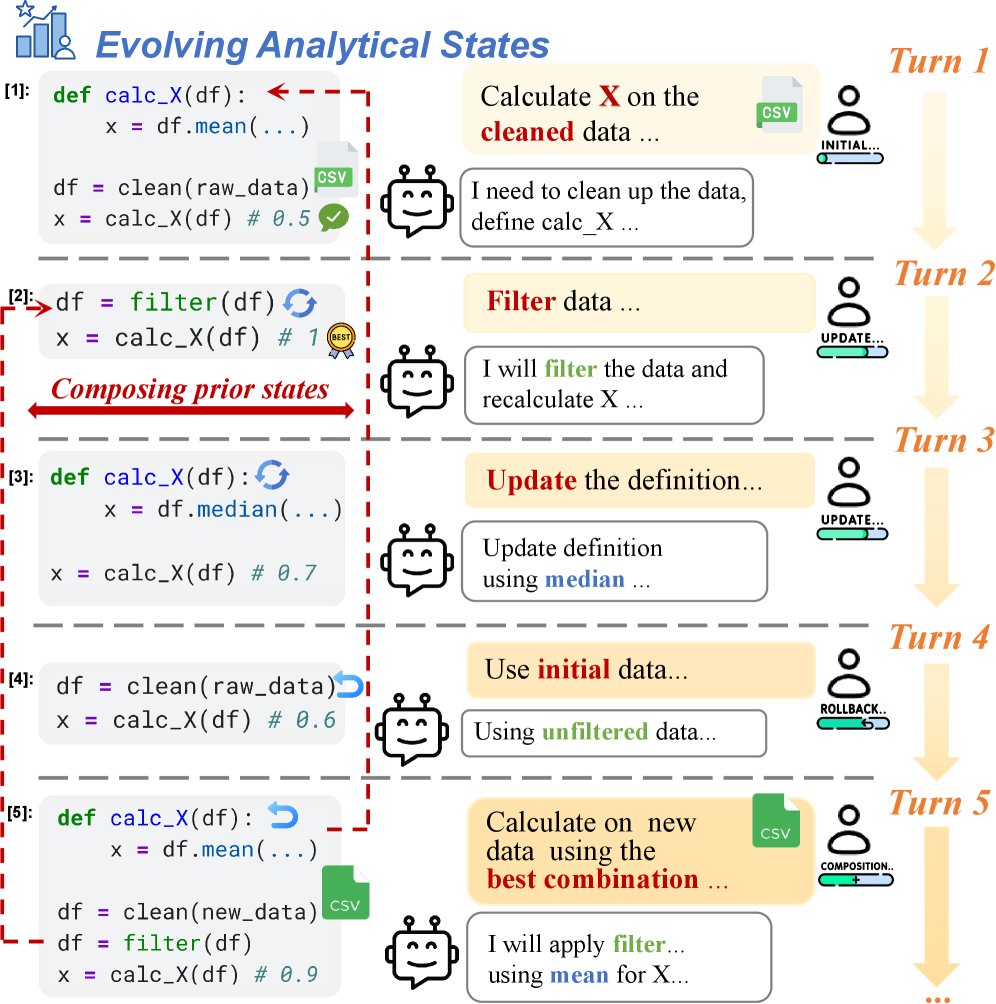
Figure 1 — 분석 상태 관리
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 논문은 실제 Kaggle 데이터 분석 워크플로우에서 추출한 68개 작업과 2,225개의 턴으로 구성된 LongDS 벤치마크를 제안합니다 [Figure 2, Figure 3]. 이 벤치마크는 다양한 도메인(Geoscience, Business, Education 등)을 포괄하며, 상태 변화 패턴(Rollback, Counterfactual 등)을 중심으로 장기 의존성을 설계하였습니다. 실험 결과, 현재의 최첨단 LLM 에이전트들은 평균 48.45%의 정확도에 그쳤으며, 세션이 진행됨에 따라 정확도가 47% 포인트 이상 급격히 하락하는 성능 저하가 관찰되었습니다 [Table 2, Figure 5]. 분석 결과, 전체 실패의 52%~69%가 long-horizon 오류(주로 Cascade Error 및 State Management Error)에 기인하는 것으로 밝혀졌으며, 단순히 에이전트의 작업 단계(Step)를 늘리는 것이 성능 개선을 보장하지 않음이 확인되었습니다 [Figure 6].
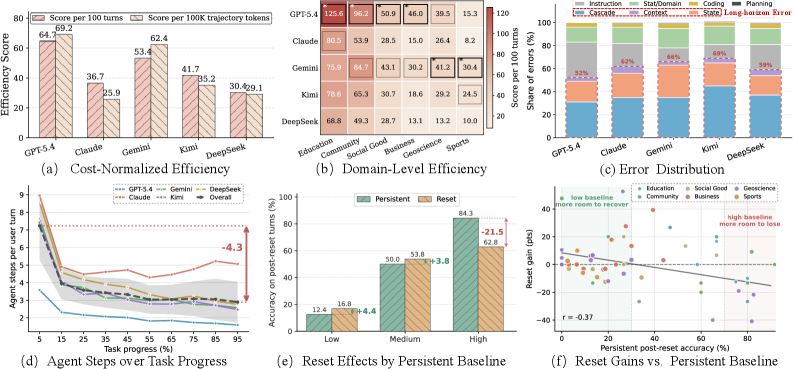
Figure 6 — 병목 진단 분석
## 4. Conclusion & Impact (결론 및 시사점) 본 연구는 LongDS 벤치마크를 통해 데이터 분석 에이전트가 긴 시간 동안 analytical state를 유지하는 데 심각한 어려움을 겪고 있음을 입증했습니다. 연구진은 에이전트 성능의 병목 현상이 단순히 컴퓨팅 자원 부족이 아니라, 상태 유지 및 오류 전파 관리의 취약성에 있음을 지적합니다. 이 벤치마크는 향후 더욱 신뢰할 수 있는 에이전트 개발을 위한 중요한 가이드라인을 제공하며, 학계와 산업계에서 장기적인 분석 작업이 가능한 에이전트 설계를 가속화하는 기점이 될 것입니다.
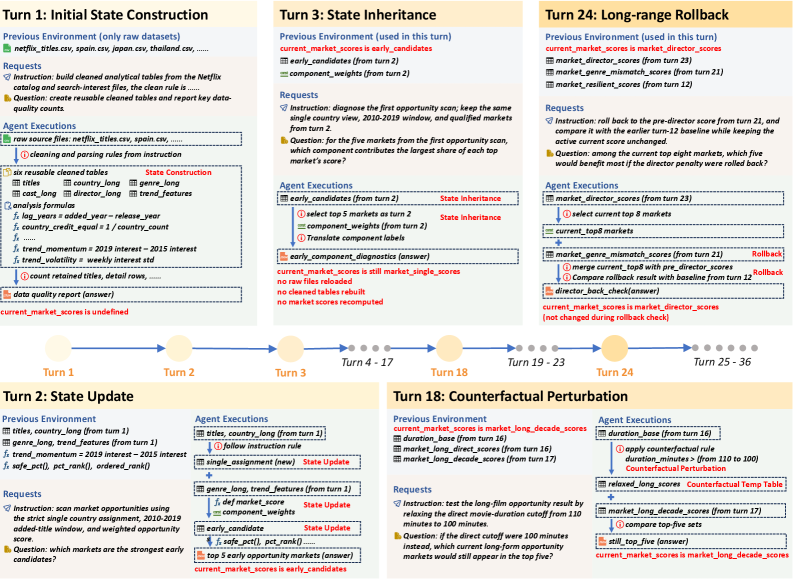
Figure 2 — 상태 변화 예시
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- [논문리뷰] QVal: Cheaply Evaluating Dense Supervision Signals for Long-Horizon LLM Agents
- [논문리뷰] Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
Review 의 다른글
- 이전글 [논문리뷰] Linear Scaling Video VLMs for Long Video Understanding
- 현재글 : [논문리뷰] LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
- 다음글 [논문리뷰] LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
댓글