[논문리뷰] Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
링크: 논문 PDF로 바로 열기
메타데이터
저자: Julia Belikova, Rauf Parchiev, Evgeny Egorov, Grigorii Davydenko, Gleb Gusev, Andrey Savchenko, Maksim Makarenko
1. Key Terms & Definitions (핵심 용어 및 정의)
- Procedural Memory: LLM 에이전트가 반복적인 업무를 수행하기 위해 활용하는 재사용 가능한 지침, 절차 및 전략을 담은 메모리 구조.
- AFTER (Agentic Framework for Transfer & Evolution of Reasoning): 본 논문에서 제안하는 벤치마크로, 382개의 현실적 업무 과제와 22개의 절차적 스킬을 포함하여 모델의 스킬 전이 성능을 측정함.
- Evolution: 스킬의 수집, 진단, 개정, 승격 과정을 표준화하여 procedural memory의 성능을 최적화하고 평가하는 경량 인터페이스 프레임워크.
- Specialization vs. Generalization: 스킬이 특정 워크플로우에 최적화되는 정도(Specialization)와 다양한 태스크, 역할, 모델 간에 범용적으로 활용되는 정도(Generalization) 사이의 균형을 의미함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 LLM 기반 에이전트가 현실 업무에서 반복적인 절차를 수행할 때 발생하는 Procedural Memory의 재사용성 문제를 해결하고자 한다. 기존 연구들은 로컬 환경에서의 단기 성능 향상에 집중하여, 서로 다른 태스크, 역할(Role), 모델 Backbone 간의 실질적인 전이 성능을 충분히 평가하지 못했다. 특히, 좁은 경험으로부터 학습된 스킬이 오히려 특정 환경에 overfit(과적합)되어 범용성을 상실하는 문제가 발생하며, 이를 평가할 제어된 실험 환경이 부재하다는 한계가 있다. 본 논문은 이러한 procedural memory의 specialization과 generalization 사이의 trade-off를 분석하고 체계적으로 평가할 수 있는 프레임워크를 제안한다 [Figure 1].
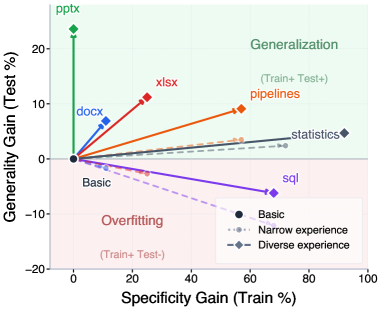
Figure 1 — 스킬 진화 및 범용성 trade-off
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 AFTER 벤치마크를 통해 에이전트의 Procedural Memory 전이 성능을 정량적으로 평가하고, Evolution 인터페이스를 활용하여 스킬을 최적화하는 방법론을 제안한다. 연구진은 6개의 전문 역할과 22개의 스킬을 기반으로 구성된 태스크 환경에서 스킬의 static performance와 진화된 스킬의 성능을 비교 분석하였다 [Figure 2]. 실험 결과, procedural skills를 도입했을 때 평균 full-pass accuracy가 +2.8 포인트 향상되었으며, 단 한 번의 LLM-guided refinement round만으로도 추가적으로 +3.7~6.7 포인트의 성능 향상을 기록하였다 [Figure 3]. 특히, 다양한 모델의 실행 트레이스(Execution Traces)로부터 진화된 스킬은 cross-model test accuracy에서 73.1%를 달성하여, 단일 모델 소스 대비 13.7 포인트 이상 뛰어난 성능 우위를 보였다 [Figure 4]. 또한, evolved skills를 사용함으로써 실제 에이전트의 토큰 사용량을 최대 62%까지 절감하는 효율성을 입증하였다 [Figure 6].

Figure 2 — AFTER 벤치마크 개요 및 구조
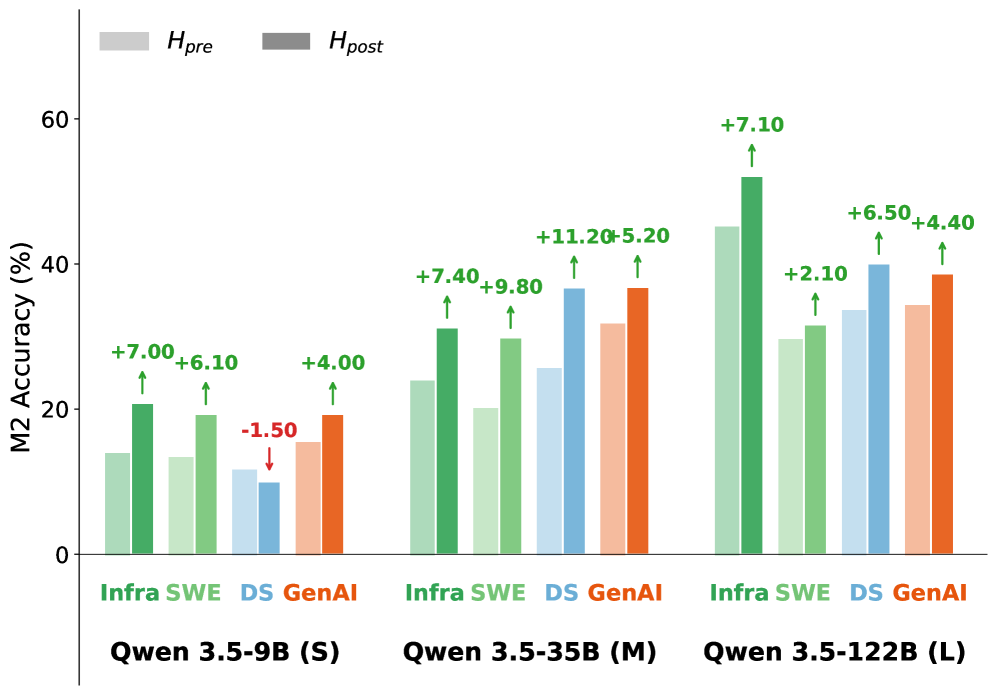
Figure 3 — 단일 라운드 스킬 개선 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 procedural memory가 단순한 정적 아티팩트가 아니라, 현실적인 업무 환경에서 학습하고 진화할 수 있는 동적 에이전트 역량임을 입증하였다. 연구 결과는 범용적인 스킬 전이를 달성하기 위해서는 좁은 범위의 경험보다 다양한 환경에서의 다각적 경험이 필수적임을 시사한다. 본 연구에서 제시한 AFTER 벤치마크와 스킬 최적화 프레임워크는 향후 산업용 에이전트 플랫폼을 설계하고 효율적인 procedural memory 시스템을 구축하는 데 중요한 실무적 가이드라인을 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ImplicitMemBench: Measuring Unconscious Behavioral Adaptation in Large Language Models
- [논문리뷰] CoffeeBench: Benchmarking Long-Horizon LLM Agents in Heterogeneous Multi-Agent Economies
- [논문리뷰] Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
- [논문리뷰] When Tools Fail: Benchmarking Dynamic Replanning and Anomaly Recovery in LLM Agents
- [논문리뷰] ForeSci: Evaluating LLM Agents for Forward-Looking AI Research Judgment
Review 의 다른글
- 이전글 [논문리뷰] Little Brains, Big Feats: Exploring Compact Language Models
- 현재글 : [논문리뷰] Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
- 다음글 [논문리뷰] MemLearner: Learning to Query Context memory for Video World Models
댓글