[논문리뷰] MemLearner: Learning to Query Context memory for Video World Models
링크: 논문 PDF로 바로 열기
저자: Jiwen Yu, Jianxiong Gao, Jianhong Bai, Yiran Qin, Kaiyi Huang, Quande Liu, Xintao Wang, Pengfei Wan, Kun Gai, Xihui Liu
Part 1: 요약 본문
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video World Models: 사용자의 행동과 과거 비디오 프레임을 입력받아 미래의 세계 상태를 예측하고 시뮬레이션하는 비디오 생성 모델.
- Query Tokens (Q tokens): 컨텍스트 토큰(C)과 예측 토큰(P) 사이의 정보 브리지 역할을 수행하여, 생성 모델이 컨텍스트 메모리를 적응적으로(adaptively) 추출할 수 있도록 돕는 학습 가능한 토큰.
- Context Tokens (C tokens): 모델이 미래 상태를 예측하기 위해 참조하는 과거 비디오 프레임들의 정보.
- Diffusion Transformer (DiT): 논문에서 비디오 생성의 백본 아키텍처로 사용된 모델로, 3D Attention과 Diffusion 프로세스를 통해 고품질의 비디오를 생성함.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Video World Models가 긴 시간의 생성 과정에서 장면의 일관성을 유지하지 못하는 메모리 부족 문제를 해결하고자 한다. 기존의 Rule-based 컨텍스트 검색 방식(예: FOV 기반 검색)은 복잡한 환경에서의 오클루전(Occlusion)이나 동적 객체(Dynamic objects) 처리에 한계가 존재한다. 저자들은 이러한 수동적인 규칙 기반 접근 방식 대신, 신경망이 end-to-end 학습을 통해 적응적으로 과거 정보를 검색하는 새로운 메모리 메커니즘이 필요하다고 판단하였다. 따라서 본 논문은 학습 가능한 Query Tokens를 도입하여 모델 스스로 유용한 컨텍스트를 추출하는 MemLearner를 제안한다 [Figure 1].
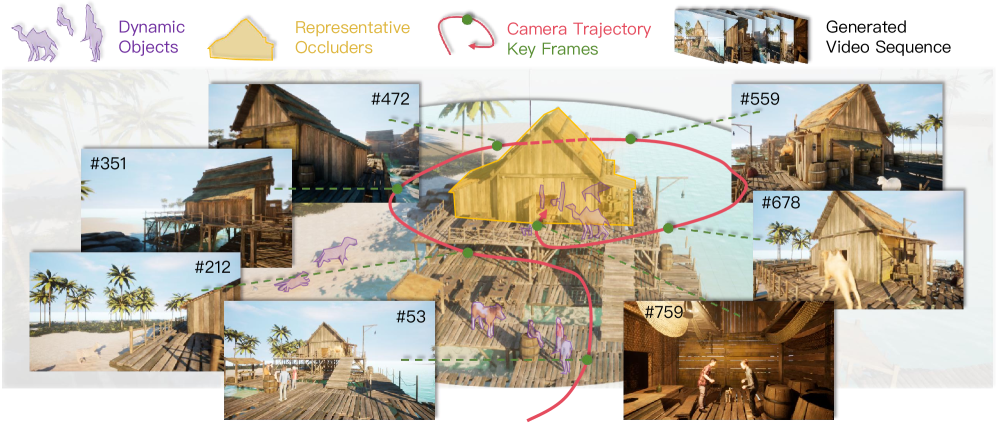
Figure 1 — MemLearner 요약
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 비디오 생성 모델 내부의 사전 학습된 시각적 Prior를 최대한 활용하기 위해, 별도의 모듈을 추가하지 않고 생성 모델 자체를 컨텍스트 쿼리 프로세스에 직접 통합하는 방식을 제안한다 [Figure 2]. MemLearner는 Query Tokens(Q)를 도입하여 C 토큰에서 관련 정보를 추출하고, 이를 P 토큰의 생성 조건으로 활용한다. 또한, 긴 비디오 시퀀스에서의 계산 효율성을 위해 초기 층(Shallow Layers)에서만 컨텍스트를 쿼리하고, 이후 생성 층(Generative Layers)에서는 Q와 P 토큰만을 사용하는 효율적인 전략을 적용하였다 [Figure 4]. 정량적 실험 결과, 제안 모델은 GT Comp. 환경에서 PSNR 21.23, LPIPS 0.2904를 기록하며 기존 방식들(예: CaM, VMem) 대비 우수한 성능을 입증하였다 [Table 2]. 특히 동적 객체와 오클루전이 포함된 환경에서 기존 모델들보다 일관된 장면 생성 성능을 보였으며, 이는 오클루전 상황에서의 메모리 복원 능력이 크게 향상되었음을 시사한다 [Figure 5].
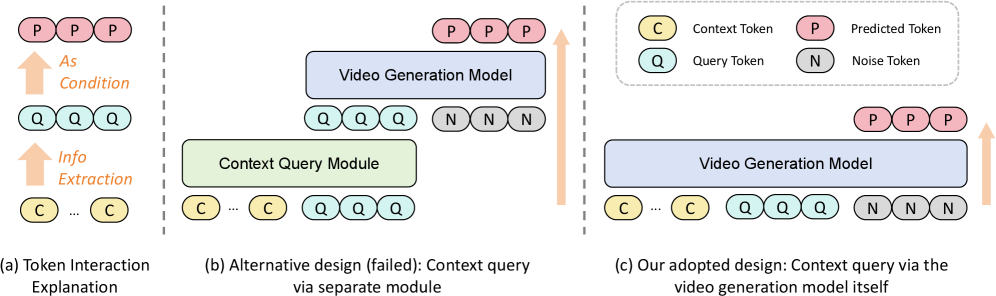
Figure 2 — 아키텍처 및 쿼리 설계
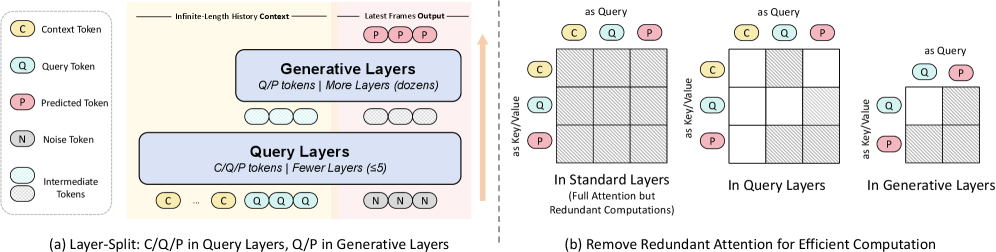
Figure 4 — 효율성 전략 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 학습 기반의 적응형 컨텍스트 쿼리 기법인 MemLearner를 통해 Video World Models의 고질적인 일관성 부족 문제를 성공적으로 완화하였다. 저자들은 다양한 데이터셋을 효율적으로 활용하기 위한 Multi-dataset training strategy를 제안하여 모델의 범용성을 확보하였다. 이 연구는 비디오 생성 및 World Models 분야에서 명시적인 규칙 없이도 모델이 자체적으로 효율적인 메모리 관리 기법을 학습할 수 있음을 입증하며, 향후 더 긴 시간의 실감 나는 비디오 시뮬레이션을 가능하게 하는 중요한 기술적 이정표를 제시한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TerraDiT-Ω: Unified Spatial Control for Satellite Image Synthesis with Any Geospatial Primitive
- [논문리뷰] Walking in the Implicit: Interactive World Exploration via Neural Scene Representation
- [논문리뷰] PhysiFormer: Learning to Simulate Mechanics in World Space
- [논문리뷰] UnityShots: Memory-Driven Multi-Shot Audio-Video Generation with Boundary-Aware Gating
- [논문리뷰] TryOnCrafter: Unleashing Camera Trajectories for Realistic Video Virtual Try-on via a Renderable 4D Try-on Proxy
Review 의 다른글
- 이전글 [논문리뷰] Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
- 현재글 : [논문리뷰] MemLearner: Learning to Query Context memory for Video World Models
- 다음글 [논문리뷰] MuSViT: A Foundation Vision Model for Sheet Music Representation
댓글