[논문리뷰] Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models
링크: 논문 PDF로 바로 열기
저자: Jiazheng Xing, Hangjie Yuan, Lingling Cai, et al.
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Unified Progressive Frequency Bridging (UPFB): 학습 시 사용된 소형 생성자와 추론 시 활용되는 대형 고성능 생성자 간의 생성 책임을 주파수 영역에서 점진적으로 전환하는 추론 전략입니다.
- Connector-based Unified Models: 이해 블록(Understanding block)의 시맨틱 출력을 생성 블록(Generation block)의 조건 공간으로 주입하기 위해 전용 커넥터를 사용하는 모델 아키텍처입니다.
- VR-Bench: 비디오 생성 모델의 추론(Reasoning) 능력, 즉 의도된 논리적 시퀀스와 생성된 비디오 간의 정렬 상태를 8가지 차원에서 체계적으로 평가하는 새로운 벤치마크입니다.
- Homogeneous Latent Space: 소형 생성자와 대형 생성자가 동일한 잠재 공간(Latent space)을 공유하도록 설정하여, 주파수 기반의 안정적인 융합을 가능하게 하는 기술적 가정입니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 기존의 커넥터 기반 비디오 생성 모델이 높은 시각적 품질과 복잡한 논리적 추론 능력을 동시에 달성하는 데 겪는 한계를 해결하고자 합니다. 기존 연구(Baseline)들은 이해 블록과 대규모 생성 모델을 통합하는 과정에서 막대한 fine-tuning 비용을 요구하며, 이로 인해 시각적 완성도가 낮은 소형 모델에 의존하거나 학습 효율성이 저하되는 문제를 겪습니다 [Figure 1]. 이러한 문제를 극복하기 위해, 본 연구는 학습 단계에서의 효율성과 추론 단계에서의 고성능 생성을 분리하는 새로운 프레임워크를 제안합니다.

Figure 1 — Lumos-Nexus 생성 예시
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 Lumos-Nexus라 명명된 2단계 학습 및 추론 프레임워크를 제안합니다. 첫 번째 단계인 학습 과정에서는 소형 생성자만을 이해 블록과 정렬하여 시맨틱 제어 능력을 학습시킵니다 [Figure 2]. 두 번째 단계인 추론 과정에서는 UPFB를 도입하여, 학습된 소형 생성자가 초기 레이아웃과 전역 구조를 담당하고, pretrained 대형 생성자가 후반부의 미세 텍스처를 개선하는 coarse-to-fine 프로세스를 수행합니다 [Figure 2]. 특히 주파수 분해(Frequency Decomposition)와 RMS Alignment를 통해 생성자 간의 잠재적 불일치를 제거함으로써, 텍스트 입력과 생성 영상 간의 높은 시맨틱 정렬을 유지하면서도 시각적 realism을 극대화합니다 [Table 1]. 실험 결과, Lumos-Nexus는 VBench에서 84.12의 총점을 기록하며 기존의 Video unified models 대비 압도적인 성능 우위를 보였으며, 새롭게 제안된 VR-Bench에서도 복잡한 물리 추론 및 상식 reasoning 차원에서 최고 수준의 성능을 입증했습니다 [Table 2].
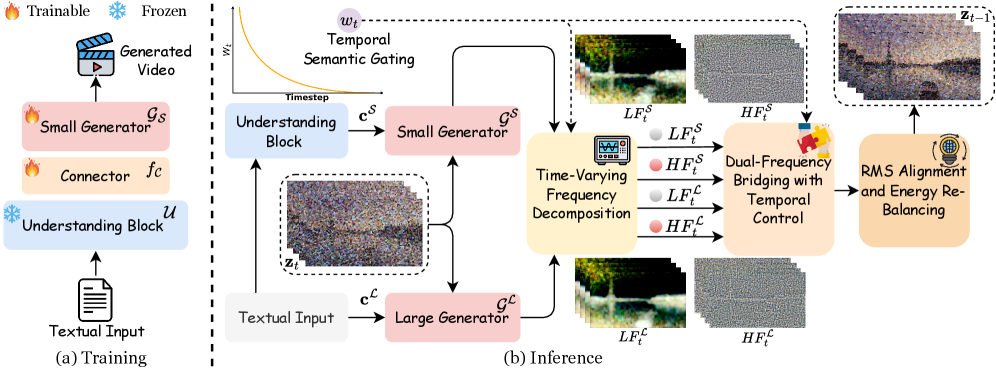
Figure 2 — Lumos-Nexus 전체 아키텍처
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 비디오 생성 분야에서 학습 효율성과 고품질 합성이라는 두 가지 상충하는 목표를 효과적으로 해결한 Lumos-Nexus 프레임워크를 정립하였습니다. 제안된 UPFB는 추가 학습 없이도 기존 대규모 생성 모델의 잠재력을 최대한 활용할 수 있게 하여, 산업계 및 학계에서 비디오 생성 모델의 실제 배포 가능성을 크게 높였습니다. 또한, VR-Bench는 단순히 시각적 품질을 넘어 모델의 인지적 reasoning 능력을 평가하는 새로운 지표를 제시함으로써, 향후 비디오 생성 연구가 단순 영상 모사를 넘어 의도 지향적 생성으로 나아가는 방향성을 제시합니다.
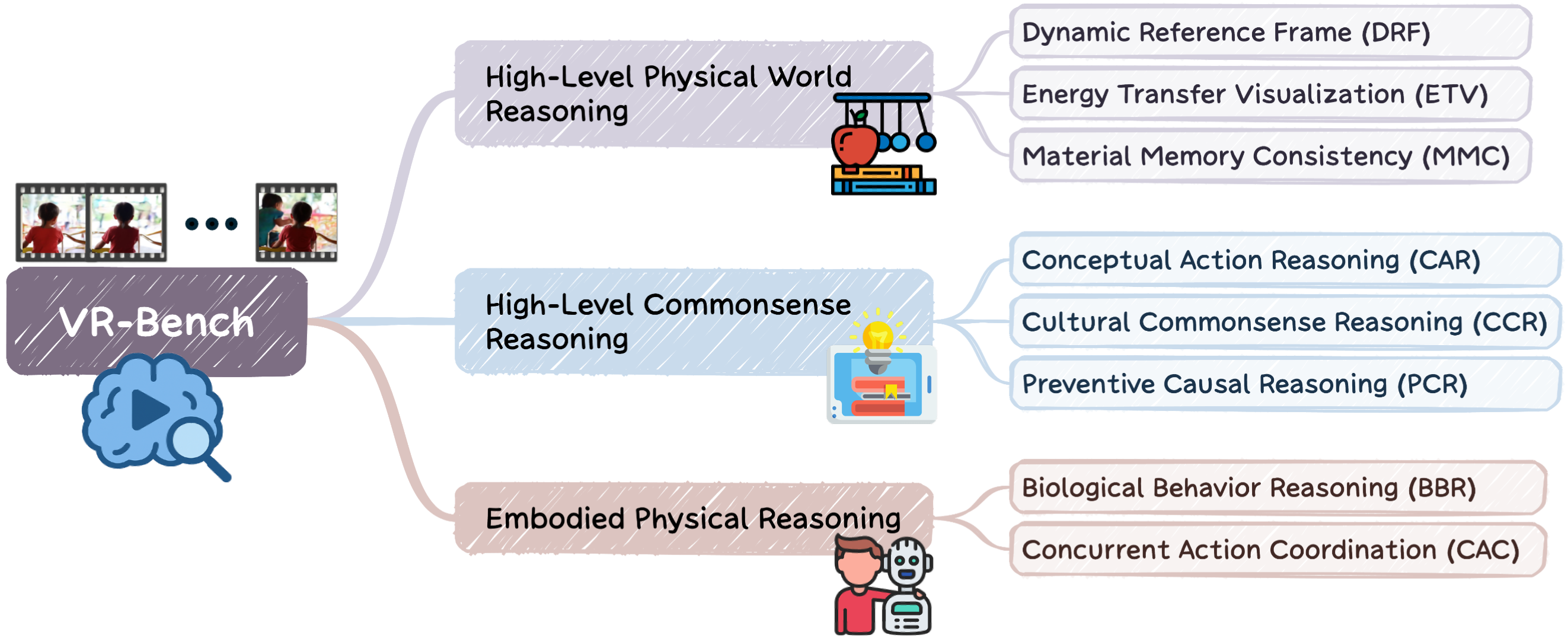
Figure 3 — VR-Bench 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Wan-Streamer v0.2: Higher Resolution, Same Latency
- [논문리뷰] FlowR2A: Learning Reward-to-Action Distribution for Multimodal Driving Planning
- [논문리뷰] Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments
- [논문리뷰] OmniRefiner: Reinforcement-Guided Local Diffusion Refinement
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
Review 의 다른글
- 이전글 [논문리뷰] LongTraceRL: Learning Long-Context Reasoning from Search Agent Trajectories with Rubric Rewards
- 현재글 : [논문리뷰] Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models
- 다음글 [논문리뷰] MAAT: Multi-phase Adapter-Aware Targeted Unlearning
댓글