[논문리뷰] MAAT: Multi-phase Adapter-Aware Targeted Unlearning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Suryansh Yagnik, Shubham Gaur, Saksham Thakur, Vinija Jain, Aman Chadha, Amitava Das
1. Key Terms & Definitions (핵심 용어 및 정의)
- 5WBench: Who, What, When, Where, Why 5개 카테고리로 구성된 5,000개 샘플 규모의 균형 잡힌 벤치마크로, causal knowledge에 대한 unlearning 성능을 정량적으로 평가하기 위해 제안됨.
- LoRA (Low-Rank Adaptation): 대규모 모델의 파라미터 전체를 업데이트하는 대신, 낮은 랭크의 어댑터를 통해 파라미터를 효율적으로 미세 조정(fine-tuning)하는 기법.
- Gradient Dilution: Why-type 질문과 같이 정답의 길이가 길거나 복잡한 추론 체인을 포함할 때, 그래디언트 업데이트가 넓게 분산되어 특정 정보를 제거하는 신호가 약화되는 현상.
- Task Vector Negation: 모델의 특정 동작이나 지식을 제거하기 위해, fine-tuned 모델과 base 모델 간의 차이인 task vector를 계산하고 이를 가중치에서 감산하여 지식을 억제하는 기법.
- SVD Rank-Dimension Pruning: 어댑터 행렬의 가중치 행렬을 SVD로 분해하여 그래디언트 기여도가 낮은 rank dimension을 식별하고 제거함으로써, 목표 지식만 정밀하게 억제하는 방법론.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 기계 망각(machine unlearning) 연구들이 인과 관계(causal knowledge)를 다루는 'Why-type' 질문에 대한 평가가 전무하다는 결정적인 결함을 해결하고자 한다. 현재의 주요 벤치마크들은 대부분 엔터티 중심의 데이터셋에서 유래하여 Why-type 샘플 비중이 1.3% 미만으로 극히 낮으며, 이로 인해 모델이 인과적 추론 능력을 상실하더라도 통계적으로 높은 점수를 받을 수 있는 측정 공백이 존재한다 [Figure 1]. 저자들은 기존의 그래디언트 기반 망각 방법들이 Why-type 질문의 긴 정답 구간과 다중 홉(multi-hop) 추론 구조에서 발생하는 gradient dilution 문제로 인해 모델의 유용성을 저하시키거나 정작 지식은 제거하지 못하는 한계가 있음을 지적한다. 이를 해결하기 위해 구조화된 지식 망각 프레임워크인 MAAT를 제안한다.
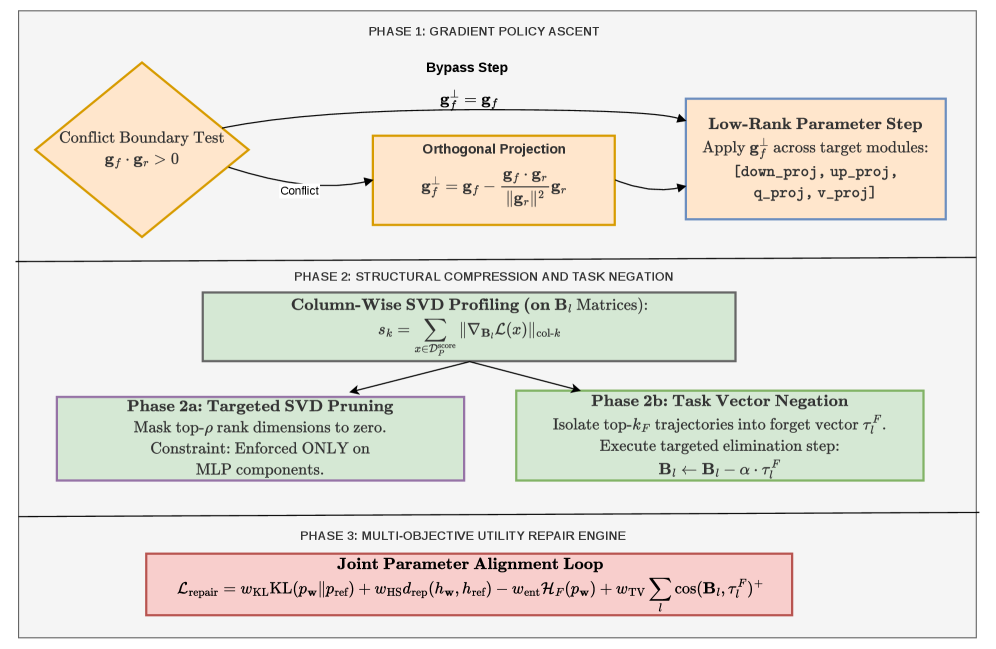
Figure 1 — MAAT 프레임워크 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 어댑터 가중치를 직접 수정하는 3단계 프레임워크인 MAAT를 제안한다 [Figure 1]. Phase 1에서는 보존해야 할 지식과 충돌하는 경우 그래디언트를 조건부로 직교 투영(orthogonal projection)하여 retain 성능을 보호한다. Phase 2에서는 SVD 기반의 MLP 어댑터 차원 가지치기와 함께, 가장 강하게 망각 신호를 발생시키는 상위 k개의 rank dimension을 대상으로 하는 task vector negation을 수행한다. 마지막으로 Phase 3에서는 KL-divergence, hidden-state 거리, 그리고 엔터티 복구 방지를 위한 엔트로피 최대화 항을 결합한 하이브리드 목적 함수를 통해 재학습(retain repair)을 수행한다.
실험 결과, MAAT는 Llama 3.2-3B 모델에서 5WBench 기준 77.4%의 FSR(Forget Success Rate)과 71.6%의 RSR(Retain Success Rate)을 기록하며, 기존 baseline 대비 망각과 유지 성능 사이의 파레토 프런티어(Pareto frontier)를 획기적으로 개선하였다. 특히, Why-type 질문에서 모든 baselines가 44% 이하의 낮은 FSR을 보이거나 극단적인 RSR 저하를 보인 반면, MAAT는 63% 이상의 FSR을 달성하며 인과 지식 망각의 실질적인 솔루션을 제시하였다 [Table 3].
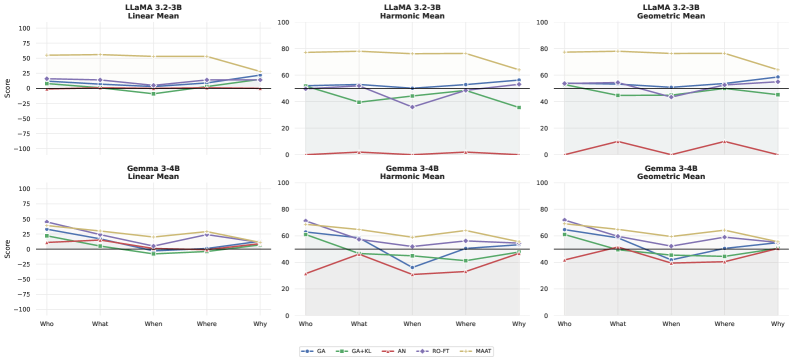
Table 3 — 5WBench 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 인과적 지식 망각이라는 난제를 해결하기 위해 균형 잡힌 5WBench와 정밀한 제어 기법인 MAAT를 성공적으로 도입하였다. MAAT는 LoRA 어댑터 구조 내에서 지식 제거와 보존을 구조적으로 분리함으로써, 모델의 전반적인 유용성을 희생하지 않고도 특정 지식을 효과적으로 삭제할 수 있음을 입증하였다. 이 연구는 대규모 언어 모델의 프라이버시 보호 및 유해 지식 제거 분야에서 더욱 정교하고 타겟팅된 망각 방법론의 토대를 마련하였으며, 향후 모델 편집(model editing) 연구에도 중요한 지표를 제공할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] From RGB Generation to Dense Field Readout: Pixel-Space Dense Prediction with Text-to-Image Models
- [논문리뷰] Program-as-Weights: A Programming Paradigm for Fuzzy Functions
- [논문리뷰] Discrete Diffusion Language Models for Interactive Radiology Report Drafting
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
Review 의 다른글
- 이전글 [논문리뷰] Lumos-Nexus: Efficient Frequency Bridging with Homogeneous Latent Space for Video Unified Models
- 현재글 : [논문리뷰] MAAT: Multi-phase Adapter-Aware Targeted Unlearning
- 다음글 [논문리뷰] Mellum2 Technical Report
댓글