[논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ilseyar Alimova, Bogdan Monogov, Artyom Mazur, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Text Detoxification: 텍스트 내의 모욕, 비속어, 공격적인 표현을 의미를 보존하면서 중립적인 형태로 재작성(rewriting)하는 기술적 과정입니다.
- Low-Resource Language: 대규모 학습 데이터나 언어별 특화 자원이 부족한 언어로, 본 논문에서는 Tatar 언어를 사례로 다룹니다.
- NMT (Neural Machine Translation): 두 언어 간의 번역을 수행하는 모델로, 본 연구에서는 NLLB-200을 Tatar 언어 데이터로 fine-tuning하여 합성 데이터 생성에 활용합니다.
- LoRA (Low-Rank Adaptation): 사전 학습된 대규모 언어 모델의 가중치를 고정하고 일부 파라미터만 학습하여 연산 효율을 높이는 Parameter-Efficient Fine-Tuning 기법입니다.
- STA (Style Transfer Accuracy): 생성된 텍스트가 비독성(non-toxic) 상태인지를 판별하는 지표로, xlm-roberta-large 기반의 분류기를 통해 측정됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Tatar와 같이 데이터 자원이 부족한 언어에서 발생하는 자동화된 텍스트 정화(detoxification) 성능 저하 문제를 해결합니다. 기존의 다국어 대규모 언어 모델(LLM)은 저자원 언어에 대한 이해도가 낮고, 문화적 맥락이나 언어적 미묘함을 반영하지 못해 정화 성능이 제한적입니다. 특히 CLEF-2025 공유 과제 결과에 따르면, 기존 모델들은 Tatar 언어에서 인간 수준(human baseline)에 미치지 못하는 성능을 보였습니다 [Figure 1]. 따라서 본 연구는 데이터 부족을 극복하고 Tatar 언어에 특화된 고성능 정화 시스템인 Tatoxa를 개발하는 것을 목표로 합니다.
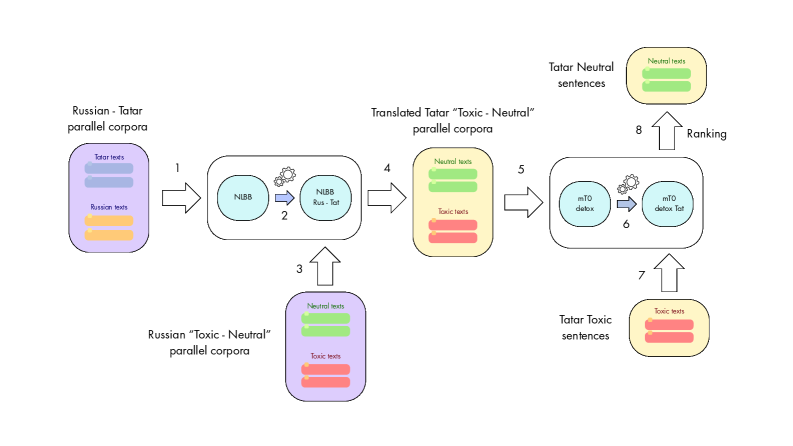
Figure 1 — Tatoxa 텍스트 정화 예시
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 Tatoxa 시스템을 통해 고품질의 합성 데이터를 생성하고, 이를 기반으로 mT0-XL 모델을 학습시키는 4단계 파이프라인을 제안합니다 [Figure 2]. 첫째, NLLB-200을 Tatar-Russian 병렬 코퍼스로 fine-tuning하여 신뢰도 높은 번역 모델을 구축합니다. 둘째, 기존 러시아어 정화 데이터셋을 Tatar어로 번역하고, LaBSE 기반의 코사인 유사도 필터링을 거쳐 38,380개의 병렬 데이터를 확보합니다. 셋째, 3-fold LoRA 앙상블 기법을 사용하여 mT0-XL 모델을 fine-tuning합니다. 마지막으로, 추론 단계에서 180개의 후보군을 생성하고, 중립성과 의미 유사도를 종합 평가하여 최적의 텍스트를 선택합니다. 실험 결과, Tatoxa는 통합 성능 지표인 J-score에서 기존의 모든 자동화된 Baseline 대비 우수한 성능(69.5%)을 달성하였으며, 특히 STA 지표에서 98.2%의 높은 독성 완화율을 기록했습니다 [Table 2]. 또한, 교차 언어(Cross-lingual) 실험을 통해 문화적으로 유사한 러시아어 데이터보다 Tatar 현지 데이터로 학습하는 것이 훨씬 효과적임을 입증했습니다 [Figure 3].

Figure 2 — Tatoxa 파이프라인 워크플로우
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Tatoxa 시스템을 도입하여 저자원 언어인 Tatar에 대한 텍스트 정화 성능을 획기적으로 향상시켰습니다. 연구 결과는 데이터가 부족한 환경에서도 기계 번역을 활용한 합성 데이터 생성과 언어 특화 fine-tuning이 효과적인 대응책이 될 수 있음을 시사합니다. 본 시스템은 향후 유사한 Turkic 계열 언어 또는 저자원 언어 환경의 안전한 온라인 커뮤니티 구축에 중요한 학술적·기술적 기반을 제공할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Hunyuan-MT Technical Report
- [논문리뷰] DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
- [논문리뷰] The Hidden Power of Scaling Factor in LoRA Optimization
- [논문리뷰] LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
- [논문리뷰] SIA: Self Improving AI with Harness & Weight Updates
Review 의 다른글
- 이전글 [논문리뷰] SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
- 현재글 : [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
- 다음글 [논문리뷰] Thinking While Speaking: Inference-Time Knowledge Transfer for Responsive and Intelligent Conversational Voice Agents
댓글