[논문리뷰] Thinking While Speaking: Inference-Time Knowledge Transfer for Responsive and Intelligent Conversational Voice Agents
링크: 논문 PDF로 바로 열기
메타데이터
저자: Vidya Srinivas, Zachary Englhardt, Shwetak Patel, Vikram Iyer, Maximus Powers
1. Key Terms & Definitions (핵심 용어 및 정의)
- Conversational Infill: 지연 시간이 긴 클라우드 모델의 응답을 기다리는 동안, 경량 온디바이스 모델이 즉각적으로 자연스러운 대화를 생성하여 공백을 메우고 대화 흐름을 유지하는 태스크입니다.
- Backend Model: 클라우드 기반의 대규모 모델로, 높은 추론 능력과 풍부한 지식 정보를 보유하고 있으며, Conversational Infill 모델에 스트리밍 방식으로 지식 청크(knowledge chunks)를 제공합니다.
- TTFT (Time-To-First-Token): 사용자의 발화 시작부터 시스템이 첫 번째 토큰을 생성하기까지 걸리는 시간으로, 실시간 음성 대화 인터페이스의 즉각성을 결정하는 핵심 지표입니다.
- Streaming Knowledge Chunks: 백엔드 모델이 생성한 지식 단위를 ConvFill 모델이 순차적으로 수신하여 응답에 통합하는 데이터 스트림입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 클라우드 기반 LLM의 높은 추론 능력과 온디바이스 모델의 즉각적인 반응성이라는 이중적 요구사항을 동시에 만족하기 위한 새로운 하이브리드 아키텍처를 제안합니다. 기존의 Cascaded 시스템은 ASR, LLM, TTS 단계를 거치며 심각한 Latency 문제를 발생시켜 자연스러운 대화를 저해하며, End-to-End 음성 모델은 백엔드 모델의 지식을 자유롭게 교체하기 어렵다는 한계가 있습니다. 저자들은 이러한 한계를 극복하기 위해 백엔드 모델이 복잡한 지식을 처리하는 동안, 소형 모델이 즉각적인 대화형 응답을 생성하는 모델 간 협업 방식을 고안하였습니다 [Figure 1].
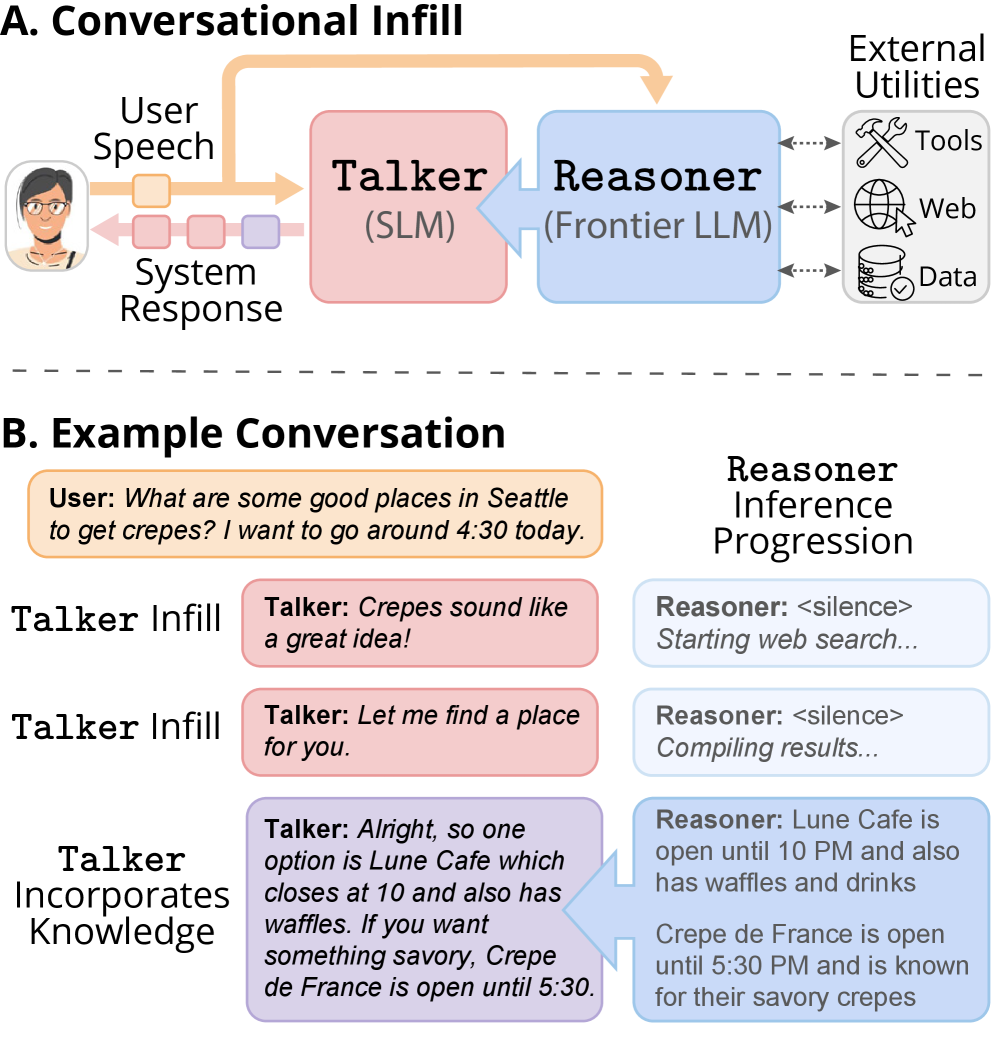
Figure 1 — ConvFill의 대화형 인필 개념
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들이 제안하는 ConvFill은 SmolLM2-360M을 베이스 모델로 활용하여, 사용자 발화와 백엔드 모델로부터 유입되는 스트리밍 지식 데이터를 입력받아 대화를 생성하는 방식으로 학습되었습니다 [Figure 2]. 모델은 매 턴마다 백엔드 모델로부터 지식 청크를 수신하거나, 지식이 없을 경우 <|sil|> 토큰을 활용하여 자연스러운 채움 말(filler)을 생성합니다. 실험 결과, ConvFill은 다양한 백엔드 모델(GPT-5, Claude Sonnet 4.5, Gemini-2.5-Pro)과 결합하여 TTFT를 평균 0.160.17초로 유지하며, 이는 독립형 모델 수준의 즉각성을 보장함을 입증했습니다 [Table 1]. 또한, NaturalQuestions 벤치마크에서 베이스 모델 대비 3642% 향상된 QA Accuracy를 기록하며 백엔드 지식을 성공적으로 통합하고 있음을 정량적으로 증명했습니다 [Table 2]. 다만, 완전한 백엔드 모델의 성능에는 미치지 못하는 격차가 확인되었으며, 이는 향후 개선 과제로 제시되었습니다.
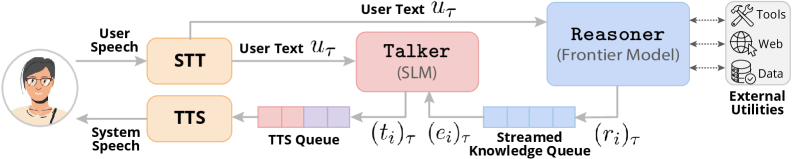
Figure 2 — 인필 생성 학습 포맷
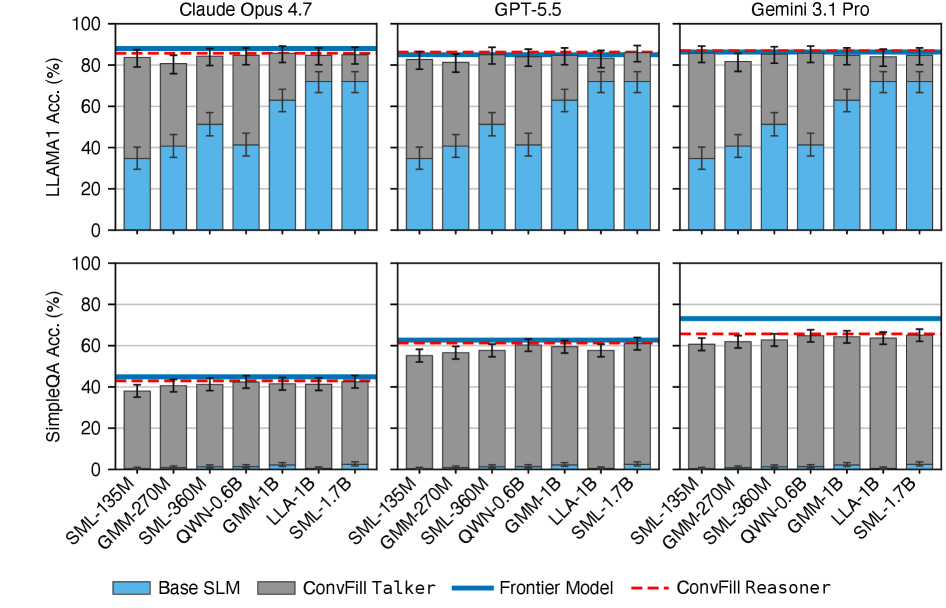
Table 1 — 모델별 TTFT 비교
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Conversational Infill 태스크를 통해 경량 온디바이스 모델과 대규모 클라우드 모델을 효과적으로 협업시키는 새로운 패러다임을 제시합니다. 이 시스템은 실시간 대화 환경에서 사용자가 체감하는 반응 속도를 극대화하면서도 고차원적인 지식 접근성을 유지할 수 있음을 입증했습니다. 해당 기술은 향후 모바일 및 엣지 디바이스에서 지연 시간 없이 지능적인 음성 에이전트를 구축하는 데 중요한 기술적 토대를 마련할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Executing as You Generate: Hiding Execution Latency in LLM Code Generation
- [논문리뷰] Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
- [논문리뷰] Unlocking the Visual Record of Materials Science: A Large-Scale Multimodal Dataset from Scientific Literature
- [논문리뷰] Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs
- [논문리뷰] Little Brains, Big Feats: Exploring Compact Language Models
Review 의 다른글
- 이전글 [논문리뷰] The Tatoxa System for Text Detoxification in Low-Resource Languages: The Case of Tatar
- 현재글 : [논문리뷰] Thinking While Speaking: Inference-Time Knowledge Transfer for Responsive and Intelligent Conversational Voice Agents
- 다음글 [논문리뷰] Towards Automating Scientific Review with Google's Paper Assistant Tool
댓글