[논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yongjia Lei, Nedim Lipka, Zhisheng Qi, Utkarsh Sahu, Koustava Goswami, Franck Dernoncourt, Ryan A. Rossi, Yu Wang
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- RL-Index: 추론(reasoning) 기반의 문서 검색을 위해 제안된 agentic indexing 프레임워크로, 추론 과정을 온라인 검색 단계가 아닌 오프라인 인덱싱 단계로 이전함.
- Agentic Indexing: LLM을 활용하여 문서의 잠재적 의미를 명시적인 rationale로 변환하고 인덱스에 추가하는 전략.
- GRPO (Group Relative Policy Optimization): 문서 증강(document augmentation) 에이전트를 최적화하기 위해 사용되는 강화학습 알고리즘으로, 검색 정확도 향상을 위한 보상 신호(reward signal)를 활용함.
- nDCG@10 (Normalized Discounted Cumulative Gain): 검색 성능을 평가하는 주요 지표로, 상위 10개 검색 결과의 순위 적합도를 측정함.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 복잡한 논리적 추론이 필요한 검색 과제에서 기존 모델들이 겪는 한계를 극복하기 위해 제안되었다. 기존의 Query Rewriting 기반 접근 방식은 실시간으로 LLM을 호출해야 하므로 상당한 Online Latency를 유발하는 문제가 있다 [Figure 1]. 또한, 단순히 표면적인 의미 유사성에만 의존하는 기존 dense retriever는 수학적 증명이나 암묵적 논리 관계가 포함된 질문에 취약하다는 단점이 있다. 저자들은 이러한 추론 과정을 오프라인 인덱싱 단계로 옮겨 실시간 성능을 최적화하고, 검색의 논리적 정확도를 높이고자 한다.
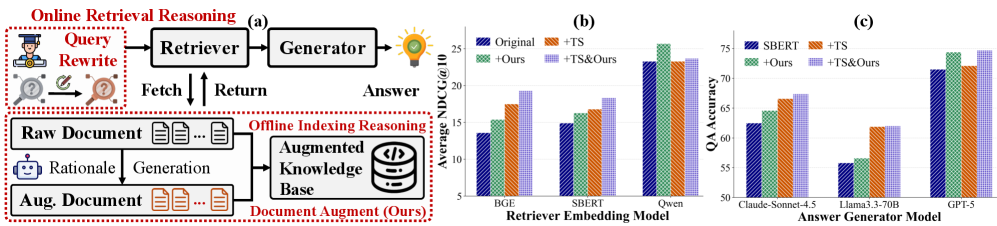
Figure 1 — 온라인/오프라인 추론 비교
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 저자들은 RL-Index를 통해 문서를 잠재적 사용자 의도를 포함하는 rationale로 증강하고, 이를 GRPO를 사용해 검색 효율성 기반의 보상으로 최적화한다 [Figure 2]. 이 방법론은 검색 시 원본 문서와 증강된 rationale를 결합하여 relevance를 계산함으로써, 추가적인 추론 비용 없이 정확도를 높이는 것이 핵심이다. 실험 결과, RL-Index는 BGE, SBERT, Qwen 등 다양한 retriever 환경에서 기존 baseline 대비 우수한 성능을 입증했다. 특히 BGE 기반 환경에서 nDCG@10을 13.6에서 15.4로 +13.2% 향상시켰으며, TongSearch와 같은 온라인 추론 방식보다 약 68배 낮은 Latency를 기록하였다 [Table 5]. 이러한 성능 향상은 Question-Answering 성능 지표에서도 일관되게 나타나며, 모델 간 전이 가능성(transferability) 또한 검증되었다 [Table 3, Table 4]. 마지막으로 실제 사례를 통해 복잡한 코드나 자연어 질의에서 모델이 생성한 rationale가 검색 정확도를 어떻게 향상시키는지 확인하였다 [Figure 3].
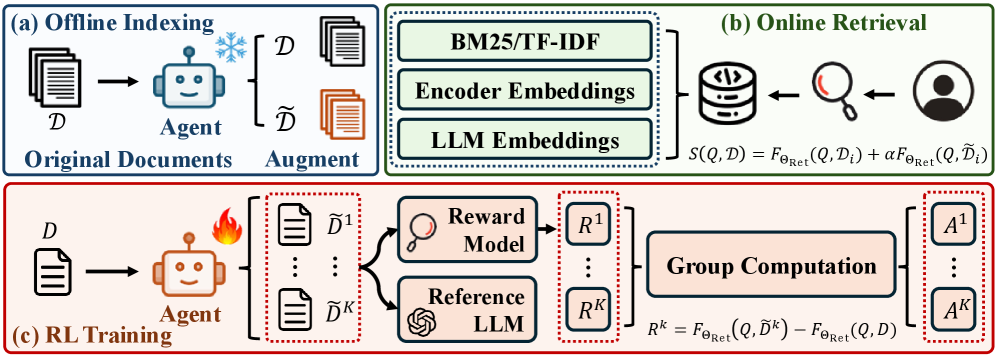
Figure 2 — RL-Index 전체 프레임워크

Figure 3 — 문서 증강 검색 사례
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 추론 중심의 문서 검색 문제를 오프라인 인덱싱 단계의 강화학습 과제로 재정의하여 해결하였다. RL-Index 프레임워크는 실시간 성능 저하 없이 검색 정확도를 유의미하게 향상시켰으며, 이는 대규모 지식 검색 시스템의 실무적 적용 가능성을 높이는 성과이다. 향후 연구에서는 더욱 다각화된 rationale 생성을 통해 포괄적인 추론 커버리지를 제공하는 방향으로 발전할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
- [논문리뷰] SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks
- [논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
- [논문리뷰] VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
Review 의 다른글
- 이전글 [논문리뷰] MVTrack4Gen: Multi-View Point Tracking as Geometric Supervision for 4D Video Generation
- 현재글 : [논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
- 다음글 [논문리뷰] ReNIO: Reweighting Negative Trajectory Importance for LLM On-Policy Distillation
댓글