[논문리뷰] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
링크: 논문 PDF로 바로 열기
메타데이터
저자: Pengcheng Jiang, Zhiyi Shi, Kelly Hong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Harness-1: 복잡한 검색 상태를 에이전트 외부의 stateful harness에서 관리하고, 정책(Policy)은 오직 검색 전략 및 판단에만 집중하도록 설계된 20B 파라미터 기반의 검색 에이전트입니다.
- Stateful Cognitive Offloading: 에이전트의 내부 컨텍스트에 의존하던 루틴한 bookkeeping 작업을 외부 harness가 처리하게 하여, 모델의 context window와 연산 자원을 효율적으로 관리하는 원칙입니다.
- WORKINGMEMORY: Harness-1에서 유지하는 per-episode 상태 저장소로, candidate pool, importance-tagged curated set, evidence graph, verification records 등을 포함합니다.
- CISPO (Context-aware Iterative Search Policy Optimization): Harness-1의 RL 학습에 사용된 on-policy 알고리즘으로, 전체 검색 에피소드에 대해 terminal reward를 최적화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 연구는 기존 검색 에이전트들이 semantic 검색 결정과 복잡한 상태 관리(bookkeeping)를 동시에 수행함에 따라 발생하는 학습의 비효율성과 성능 저하 문제를 해결하고자 합니다. 기존 에이전트들은 늘어나는 transcript 전체를 기억하고 스스로 상태를 재구성해야 하므로, 검색 결과가 누적될수록 문맥 파악이 어려워지고 reward가 희소해지는 경향이 있습니다. 저자들은 이러한 상태 관리 부담을 에이전트 내부가 아닌 환경 측의 harness로 이관(offloading)함으로써, 에이전트 정책이 오직 검색의 핵심 의사결정에만 집중할 수 있는 환경을 구축했습니다. 이를 통해 복잡한 multi-hop 검색 환경에서도 안정적인 성능을 확보하고자 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 검색 상태를 외부화하고 최적화된 인터페이스를 제공하는 Harness-1 프레임워크를 제안합니다. 에이전트는 WORKINGMEMORY 내의 구조화된 상태를 바탕으로 검색, 큐레이션, 검증(verify), 삭제 등의 액션을 수행하며, harness는 이를 동적으로 처리하여 연산 및 컨텍스트 효율성을 극대화합니다 [Figure 2]. 주요 성과로, Harness-1은 8개 검색 벤치마크에서 평균 0.730의 Curated Set Recall을 기록하며 가장 강력한 오픈 소스 검색 에이전트로 자리매김했습니다 [Table 2]. 특히, 학습 데이터에 포함되지 않은 4개의 transfer 벤치마크(LongSealQA, Seal0QA, FRAMES, HotpotQA)에서도 평균 17.0 포인트의 성능 향상을 보여, 일반적인 검색 전략으로의 범용성을 입증했습니다 [Figure 3]. 또한, harness의 각 기구적 요소(Importance tags, Evidence graph 등)를 비활성화했을 때 성능이 유의미하게 하락하는 것을 확인하여, 제안 구조의 실질적인 유효성을 검증했습니다 [Table 3].
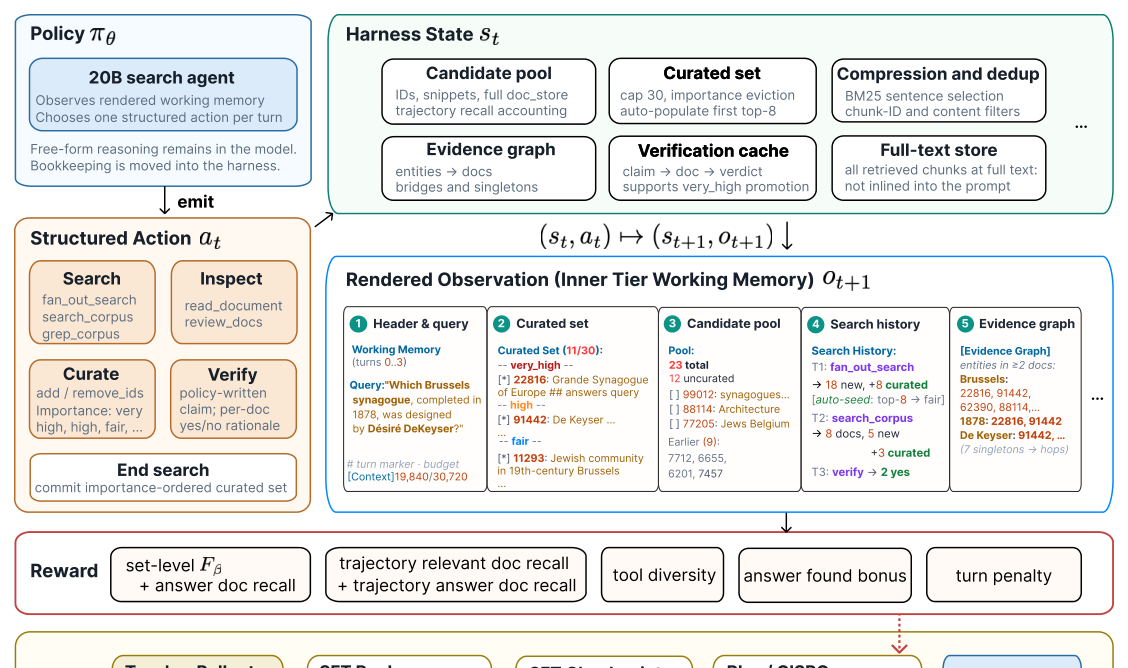
Figure 2 — Harness-1의 전체 프레임워크와 에이전트-환경 간의 인터페이스 구조를 설명하는 핵심 다이어그램
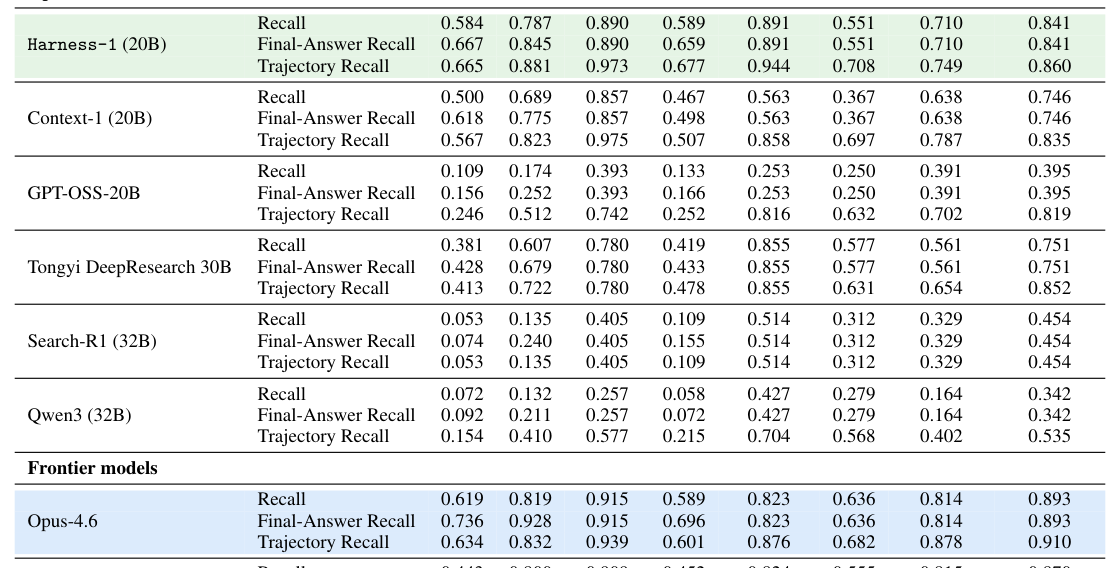
Table 2 — 다양한 벤치마크에서 Harness-1과 타 모델들의 성능을 비교한 핵심 결과 테이블
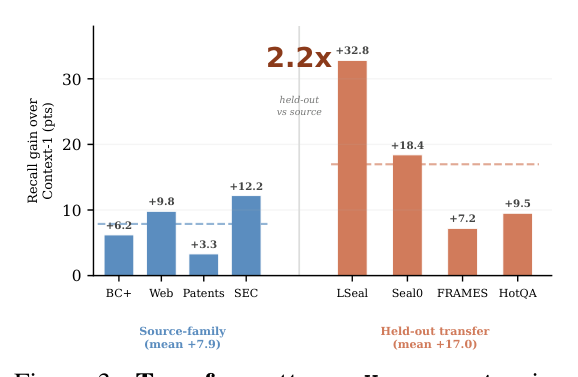
Figure 3 — 학습되지 않은 벤치마크에서의 성능 향상을 보여주어 일반화 능력을 증명하는 그래프
4. Conclusion & Impact (결론 및 시사점)
본 연구는 검색 에이전트 개발에 있어 'stateful harness'라는 구조적 설계를 도입함으로써 정보 검색의 품질과 에이전트의 학습 효율을 획기적으로 개선하였습니다. 단순한 모델 크기 확대(scaling)를 넘어, 환경과 에이전트 간의 상호작용 인터페이스를 최적화하는 것이 에이전틱 검색(agentic search)의 핵심임을 보여줍니다. 본 연구의 결과는 향후 복잡한 문서 기반의 자동화 도구 및 전문 분야 정보 검색 시스템 구축에 있어 중요한 방법론적 기준을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] The Hitchhiker's Guide to Agentic AI: From Foundations to Systems
- [논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
- [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- [논문리뷰] SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks
- [논문리뷰] PaperSearchQA: Learning to Search and Reason over Scientific Papers with RLVR
Review 의 다른글
- 이전글 [논문리뷰] HakushoBench: A Japanese Chart and Table VQA Benchmark from Governmental White Papers
- 현재글 : [논문리뷰] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
- 다음글 [논문리뷰] Joint Agent Memory and Exploration Learning via Novelty Signals
댓글