[논문리뷰] Joint Agent Memory and Exploration Learning via Novelty Signals
링크: 논문 PDF로 바로 열기
메타데이터
저자: Shizuo Tian, Xiaohong Weng, Rui Kong, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- JAMEL (Joint Agent Memory and Exploration Learning): 에이전트의 메모리 모듈과 탐색 정책을 novelty 신호를 기반으로 공동 최적화하는 프레임워크입니다.
- Latent Memory: 긴 상호작용 기록을 고정된 크기의 벡터로 압축하여 저장하는 메모리 구조로, 계산 복잡도를 획기적으로 줄입니다.
- Code Coverage: 소프트웨어 실행 시 거쳐 간 경로, 분기, 문장 등을 측정하는 정량적 지표로, JAMEL에서 탐색의 novelty를 판단하는 신뢰성 있는 지도 신호(supervisory signal)로 사용됩니다.
- Exploration Objective: 에이전트가 이전에 방문하지 않은 새로운 상태나 행동을 발견하여 높은 novelty 보상을 획득하도록 하는 학습 목표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 기반 에이전트가 개방형 환경에서 효율적인 탐색을 수행하지 못하는 문제를 해결하고자 합니다. 기존 에이전트는 환경과의 상호작용 기록이 길어짐에 따라 전체 기록을 유지하는 데 발생하는 막대한 계산 비용과 메모리 저장 공간 문제에 직면해 있습니다. 또한, 기존 연구에서 시도된 latent memory 방식은 명확한 step-level 지도 신호가 부족하여 에이전트가 과거의 경험을 효율적으로 활용하거나 반복적인 행동을 방지하는 데 한계가 있습니다. 결과적으로, 에이전트는 이미 exhausted 된 행동을 반복하거나 새로운 상태를 탐색하지 못하고 정체되는 현상을 보입니다 [Figure 1].
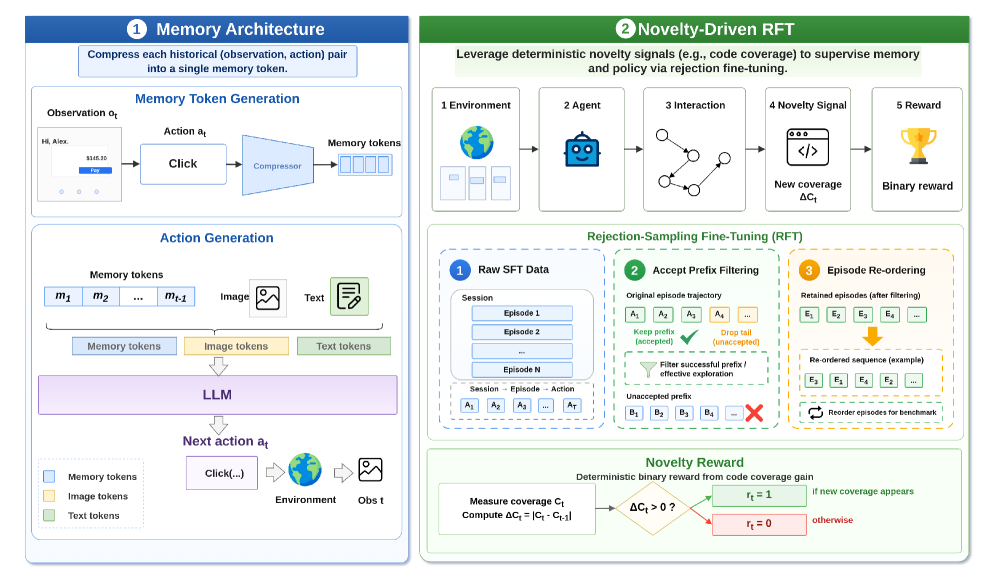
Figure 1 — JAMEL 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 JAMEL을 제안하여 에이전트의 latent memory를 novelty 신호와 결합해 공동으로 학습시킵니다. JAMEL은 frozen vision-language model을 history compressor로 활용하여 각 상호작용 step을 하나의 memory token으로 압축하고, 이를 policy 모델의 soft prefix로 투영하여 긴 맥락을 효율적으로 처리합니다. 이때, GUI 도메인에서 측정 가능한 Code Coverage를 novelty 보상으로 사용하여, 새로운 코드 경로를 실행할 때마다 보상을 부여함으로써 명시적인 annotation 없이도 학습이 가능하도록 설계했습니다. 실험 결과, JAMEL-9B는 10개의 테스트 앱에서 20.7의 평균 reward를 기록하며 MAI-UI-8B(8.4) 및 Mobile-Agent-v3.5(5.9)와 같은 오픈소스 베이스라인 모델들을 큰 폭으로 앞섰습니다 [Table 1]. 또한, JAMEL은 완전한 상호작용 기록을 사용하는 closed-source 모델들과 대등한 탐색 깊이를 보여주면서도, 기존 베이스라인 모델 대비 약 2.7배 이상 적은 토큰을 소비하여 우수한 효율성을 입증했습니다 [Table 2], [Figure 2].
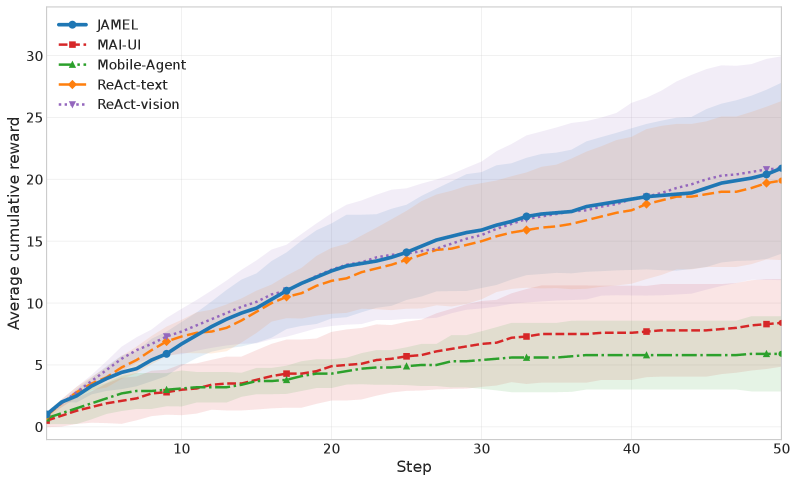
Figure 2 — 테스트 앱별 보상 누적
4. Conclusion & Impact (결론 및 시사점)
본 논문은 novelty 신호를 통해 에이전트의 메모리 학습과 탐색 전략을 통합하는 새로운 패러다임인 JAMEL을 성공적으로 제시하였습니다. 이 연구는 메모리와 탐색이 상호 보완적인 루프를 형성하여 자율적인 에이전트 학습을 가속화할 수 있음을 입증했습니다. 특히, 도메인 특화된 정량적 신호를 활용하여 annotation 비용 없이 에이전트의 일반화 성능을 높인 점은 향후 GUI 자동화 및 다양한 개방형 환경 에이전트 연구에 큰 시사점을 줍니다. 결과적으로 JAMEL은 복잡한 환경에서 에이전트의 자율적 진화와 continual learning을 위한 기초적인 토대를 마련했습니다.
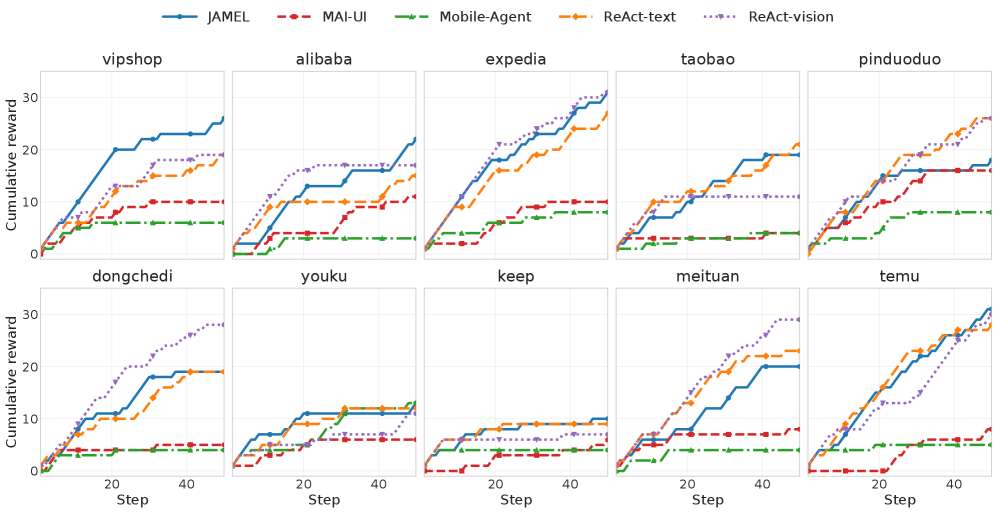
Figure 3 — 개별 앱별 보상 궤적
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Token per Multimodal Evidence: Latent Memory for Resource-Constrained QA
- [논문리뷰] KnowAct-GUIClaw: Know Deeply, Act Perfectly, Personal GUI Assistant with Self-Evolving Memory and Skill
- [논문리뷰] Dual Latent Memory in Vision-Language-Action Models for Robotic Manipulation
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
Review 의 다른글
- 이전글 [논문리뷰] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
- 현재글 : [논문리뷰] Joint Agent Memory and Exploration Learning via Novelty Signals
- 다음글 [논문리뷰] K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
댓글