[논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
링크: 논문 PDF로 바로 열기
메타데이터
저자: Sunqi Fan, Qingle Liu, Runqi Yin, Meng-Hao Guo, Shuojin Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- VG-GUI-Bench: 영상 튜토리얼을 기반으로 하는 장기적(Long-horizon) GUI 작업 수행 능력을 평가하기 위해 제안된 새로운 벤치마크입니다.
- TASKER (Task-driven And Scene-aware Keyframe searchER): 작업 관련성과 장면 역학(Scene dynamics)을 결합하여 동적으로 핵심 프레임을 추출하는 알고리즘입니다.
- Video In-Context Learning: 영상으로부터 절차적 지식을 습득하고 이를 새로운 환경이나 하위 작업으로 전이하는 모델의 능력을 지칭합니다.
- Visible Frames: TASKER 탐색 과정에서 모델이 현재 인지할 수 있는 프레임들로, 탐색 노드의 시작과 끝 프레임을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 현대의 MLLM(Multimodal Large Language Models)이 VideoQA와 같은 피상적인 시각적 단서 인식에는 뛰어나지만, 영상 튜토리얼로부터 깊은 절차적 지식을 습득하고 이를 복잡한 하위 작업에 일반화하는 능력은 부족하다는 점을 문제로 제기합니다 [Figure 1]. 기존 연구들은 영상 내 중복된 정보가 많음에도 불구하고 효과적인 정보 선택 메커니즘이 결여되어 있어, 계산 효율성이 떨어지고 핵심적인 procedural 증거를 놓치는 한계가 있습니다. 따라서 본 연구는 영상 기반 GUI 에이전트의 절차적 지식 전이를 평가할 수 있는 통합 프레임워크와 이를 위한 고효율 핵심 프레임 추출 기법의 필요성을 강조합니다.
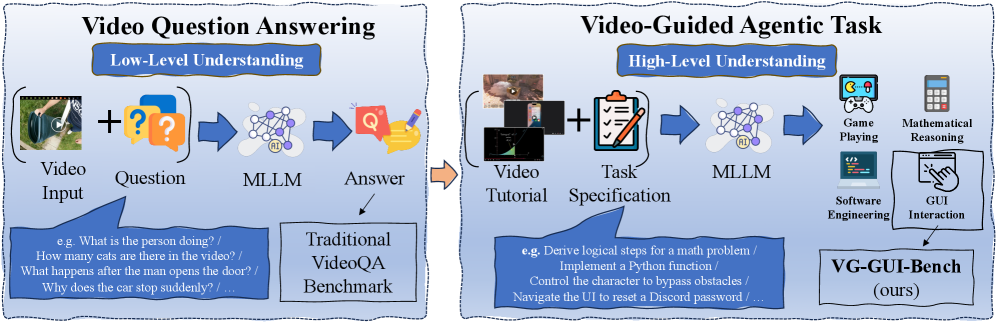
Figure 1 — 영상 이해의 두 단계
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 TASKER라는 그래프 탐색 기반의 핵심 프레임 추출 알고리즘을 제안하여, 영상의 작업 관련성과 장면 변화를 고려한 최적의 프레임 집합을 동적으로 선택합니다 [Figure 3]. 이 알고리즘은 GBFS, Dijkstra, A* 등 다양한 탐색 전략을 지원하며, MLLM의 자체 평가 및 요약을 활용하여 검색 종료 조건을 결정합니다. 실험 결과, TASKER는 EgoSchema fullset에서 기존 최고 성능 대비 2.0% 향상된 63.1%의 정확도를 기록하였으며, NExT-QA 데이터셋에서도 1.8%의 성능 개선을 달성했습니다 [Table 1]. 또한, VG-GUI-Bench 평가에서 TASKER-A* 기법은 VideoTree와 같은 강력한 베이스라인을 상회하는 40.96%의 종합 정확도를 보였으며, 더 적은 수의 프레임만으로도 높은 작업 완료율을 입증하며 우수한 Efficiency와 성능을 동시에 달성했습니다 [Table 3].
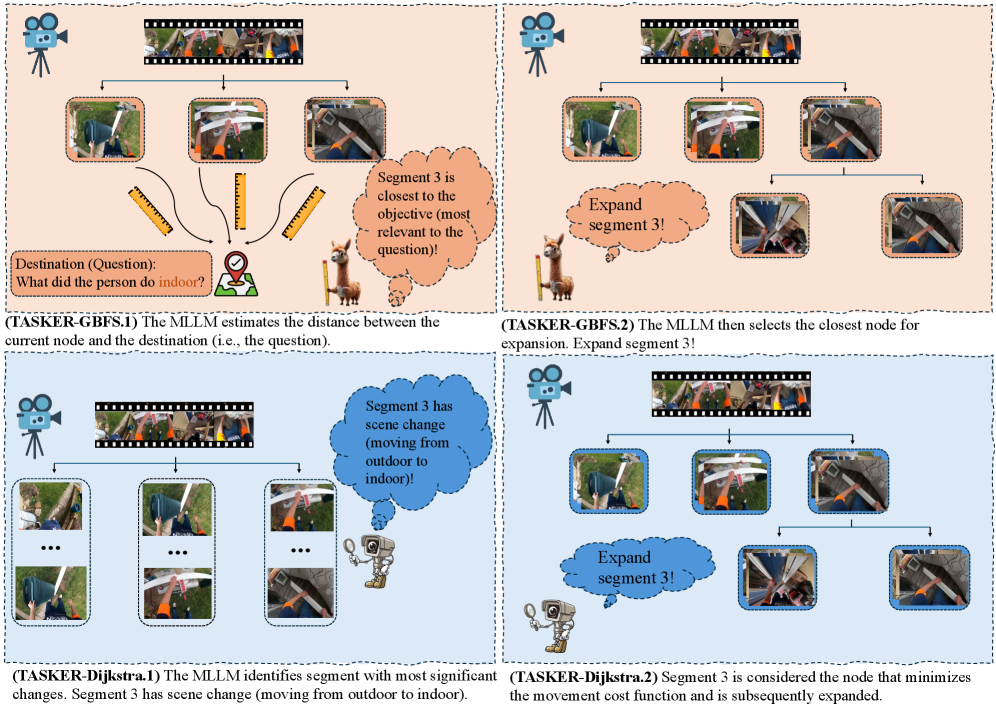
Figure 3 — TASKER 알고리즘 상세
4. Conclusion & Impact (결론 및 시사점)
본 논문은 영상 이해를 단순한 질문 답변 차원에서 복잡한 절차적 에이전트 작업으로 확장하는 VG-GUI-Bench를 도입하고, 이를 위한 일반화된 프레임 추출 방법론인 TASKER를 성공적으로 제시했습니다. 이 연구는 훈련이 필요 없는(Training-free) 모듈로서 영상 기반 인-컨텍스트 학습의 성능을 크게 제고하였으며, GUI 자동화 및 복잡한 영상 튜토리얼 학습 분야에 중요한 기술적 토대를 마련했습니다. 결과적으로, 본 연구의 통합 프레임워크는 MLLM이 실제 시나리오에서 인간의 영상을 모방하고 복잡한 조작을 수행하는 에이전트로 진화하는 데 크게 기여할 것입니다.
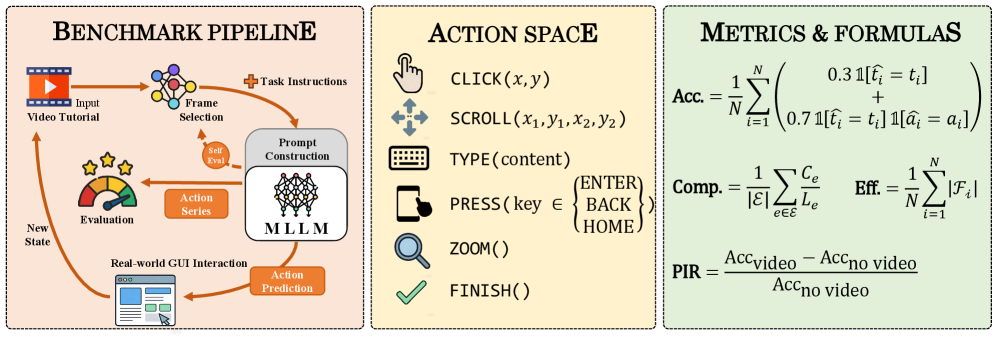
Figure 2 — VG-GUI-Bench 개요
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OmniGUI: Benchmarking GUI Agents in Omni-Modal Smartphone Environments
- [논문리뷰] MMSkills: Towards Multimodal Skills for General Visual Agents
- [논문리뷰] Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
- [논문리뷰] Unified Video Editing with Temporal Reasoner
- [논문리뷰] Map the Flow: Revealing Hidden Pathways of Information in VideoLLMs
Review 의 다른글
- 이전글 [논문리뷰] Beyond IID: How General Are Tabular Foundation Models, Really?
- 현재글 : [논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
- 다음글 [논문리뷰] Cognitive Episodes in LLM Reasoning Traces Enable Interpretable Human Item Difficulty Prediction
댓글