[논문리뷰] Beyond IID: How General Are Tabular Foundation Models, Really?
링크: 논문 PDF로 바로 열기
메타데이터
저자: Lennart Purucker, Andrej Tschalzev, Nick Erickson, Gioia Blayer, David Holzmüller, Alan Arazi, Alexander Pfefferle, Mustafa Tajjar, Gaël Varoquaux, Frank Hutter
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- BeyondArena: 다양한 데이터 분포(IID 및 non-IID)와 샘플 규모, 피처 차원을 통합적으로 평가하기 위해 저자들이 제안한 최초의 홀리스틱 벤치마크 프레임워크입니다.
- DataFoundry: 예측 머신러닝을 위한 테이블 데이터셋을 재현 가능하게 큐레이션하기 위해 도입된 Python 프레임워크이자 메타데이터 스키마입니다.
- TFM (Tabular Foundation Models): 다양한 테이블 데이터셋에서 사전 학습된 지식을 통해 예측 태스크를 수행하는 모델로, 별도의 파인튜닝 없이 In-Context Learning (ICL)을 통해 추론하는 모델을 포함합니다.
- Non-IID (Independent and Identically Distributed): 데이터가 독립적이고 동일한 분포를 따르지 않는 환경으로, 본 논문에서는 temporal (시간적 의존성) 및 grouped (그룹 구조 의존성) 데이터 분포를 의미합니다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의) 본 논문은 현재 테이블 데이터 예측 머신러닝 분야의 평가가 지나치게 IID 환경에만 편중되어 있어, 실제 실무 환경에서 요구되는 복잡하고 다양한 도메인 문제를 반영하지 못한다는 한계를 지적합니다. 기존 벤치마크들은 파편화되어 있으며, 모델 연구자들이 성능 개선을 위해 IID 환경에 최적화된 작은 데이터셋에 집중하게 함으로써 TFM의 진정한 일반화 성능 평가를 저해하고 있습니다. 저자들은 이러한 현상이 학계의 연구와 실제 산업 실무 간의 간극을 심화시킨다고 판단하며, 더 까다로운 데이터 시나리오를 다룰 수 있는 포괄적인 벤치마크가 필요함을 강조합니다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과) 본 연구는 11개 모델과 142개의 엄격하게 큐레이션된 데이터셋을 바탕으로 TFM의 일반화 능력을 평가하는 새로운 벤치마크 BeyondArena를 구축하였습니다. 연구진은 DataFoundry를 사용하여 데이터셋의 품질을 보장하고, IID, temporal, grouped 태스크를 모두 포함하는 포괄적인 평가 프로토콜을 적용하였습니다. 평가 결과, TabICLv2는 전체 데이터셋의 19%에서 1위를 차지했으며, TFM은 소규모 및 중간 규모의 IID 데이터셋에서는 우수한 ICL 성능을 보였습니다. 그러나 non-IID, 대규모, 고차원, 그리고 고차수 범주형(High-cardinality) 데이터를 포함하는 데이터셋에서는 GBDT(Gradient-Boosted Decision Trees) 계열 모델과 튜닝된 RealMLP가 여전히 강력한 성능 우위를 점하고 있음을 확인했습니다 [Figure 1], [Figure 4]. 특히, TFM은 데이터가 커질수록(∼100,000행 이상) 성능이 저하되는 경향을 보였으며, 이는 대규모 데이터 환경에서 TFM의 개선 필요성을 명확히 보여줍니다 [Figure 5].
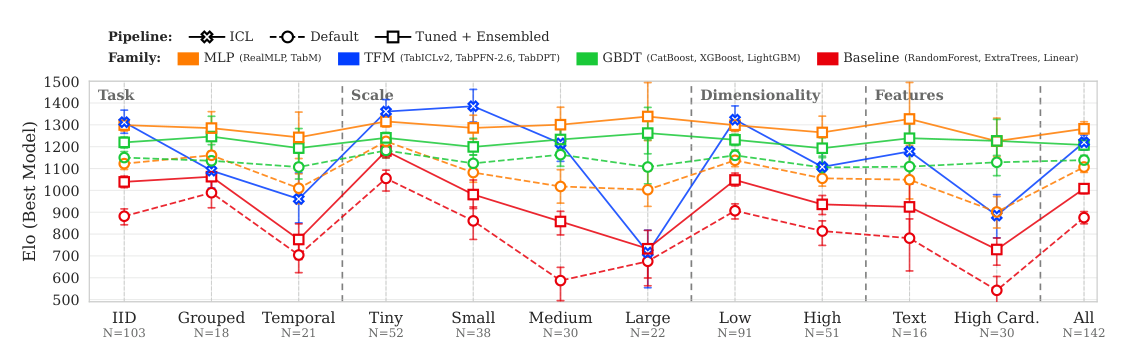
Figure 1 — 모델 패밀리별 성능(Elo)을 하위 벤치마크별로 한눈에 보여주는 핵심 결과 그래프
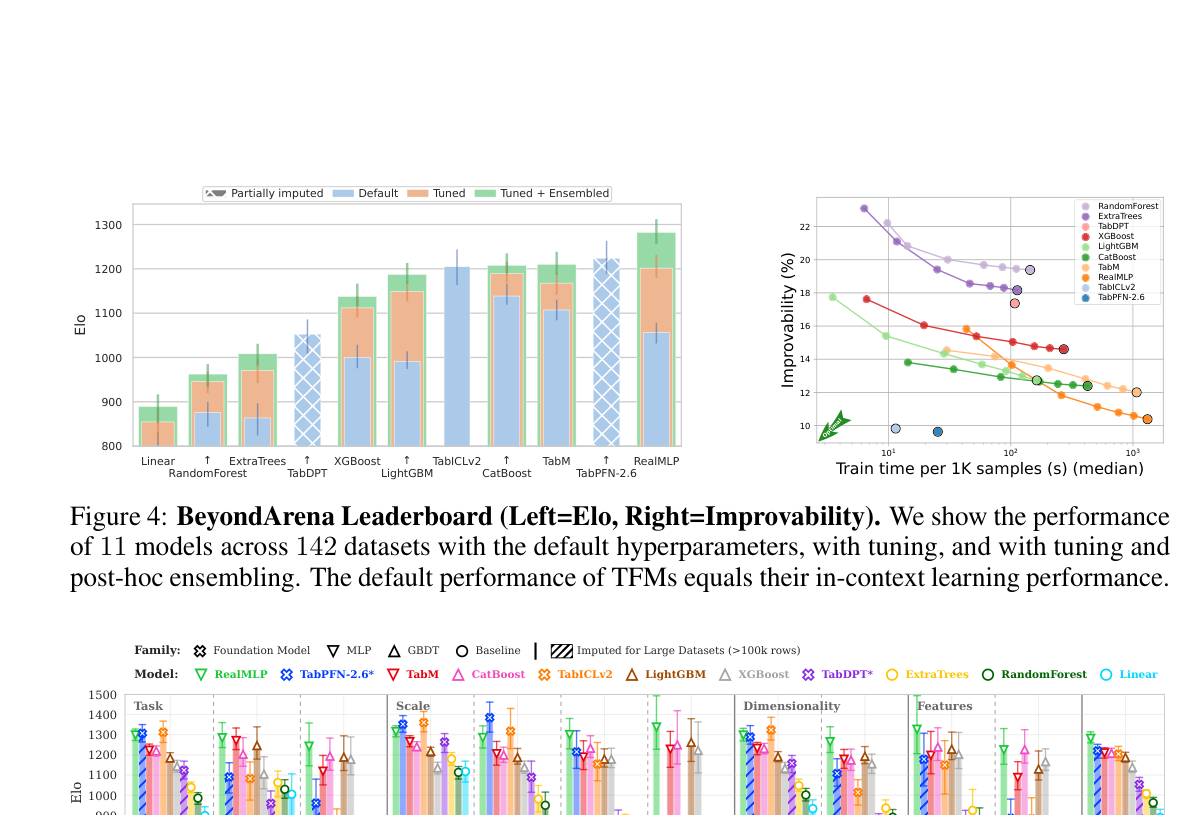
Figure 4 — 전체 11개 모델의 성능을 Elo 및 Improvability 지표로 비교한 종합 리더보드
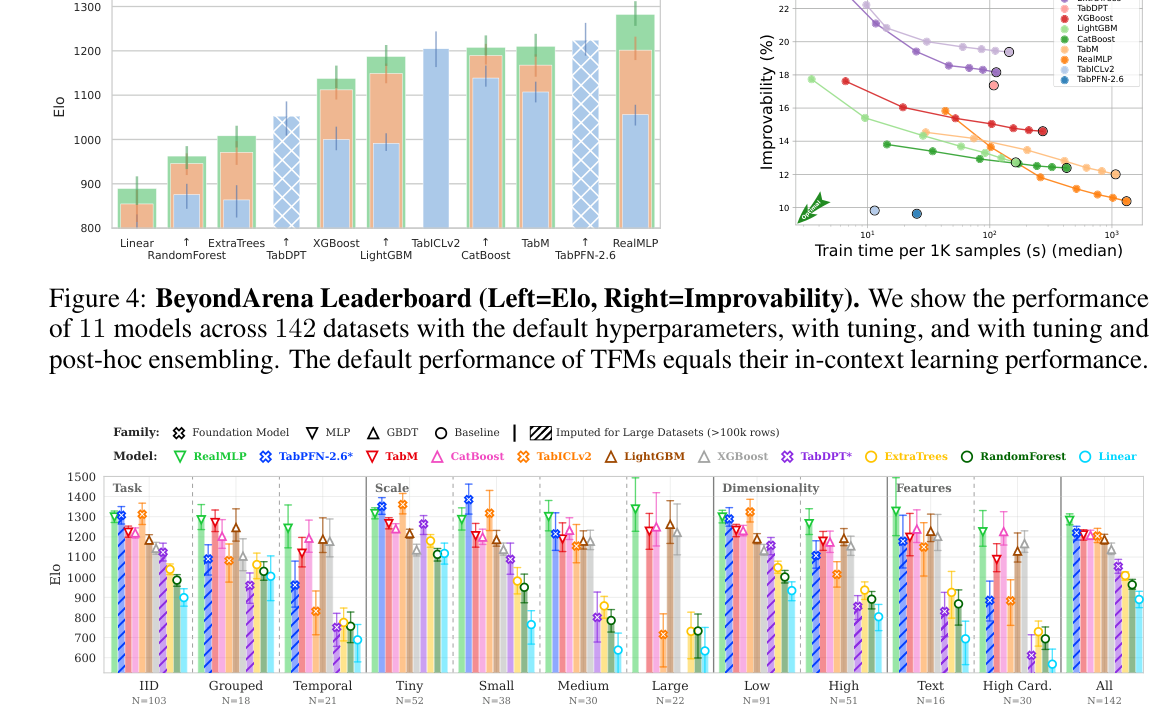
Figure 5 — 각 하위 벤치마크(태스크 유형, 규모, 차원 등)별 개별 모델의 성능 분포를 상세히 보여주는 그래프
## 4. Conclusion & Impact (결론 및 시사점) 본 논문은 현재의 TFM이 소규모 일반 데이터셋에서는 강력한 도구이지만, 실무의 복잡한 대규모 및 non-IID 데이터 환경에서는 전통적인 머신러닝 방법론을 완전히 대체하기 어렵다는 결론을 도출합니다. 본 연구에서 제안한 BeyondArena는 테이블 데이터 머신러닝 연구를 더 도전적이고 실질적인 방향으로 유도하는 새로운 표준이 될 것입니다. 저자들이 공개한 DataFoundry 프레임워크와 큐레이션된 데이터셋은 학계와 산업계 모두에게 더욱 일반화 가능하고 견고한 테이블 데이터 예측 모델을 개발하는 데 핵심적인 기여를 할 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] TabTune: A Unified Library for Inference and Fine-Tuning Tabular Foundation Models
- [논문리뷰] Estimating Time Series Foundation Model Transferability via In-Context Learning
- [논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
- [논문리뷰] Beyond Drug Discovery: The Nanotechnology Molecular Optimization (NMO) Benchmark
- [논문리뷰] DiffusionBench: On Holistic Evaluation of Diffusion Transformers
Review 의 다른글
- 이전글 [논문리뷰] Beyond Drug Discovery: The Nanotechnology Molecular Optimization (NMO) Benchmark
- 현재글 : [논문리뷰] Beyond IID: How General Are Tabular Foundation Models, Really?
- 다음글 [논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
댓글