[논문리뷰] K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
링크: 논문 PDF로 바로 열기
메타데이터
저자: Nahyun Lee, Dongkeun Yoon, Guijin Son, Geewook Kim, Dayoon Ko, Jeonghun Park, Haneul Yoo, Jaewon Cho, Junghun Park, Changyoon Lee, Kyochul Jang, Jaeyeon Kim, Eunsu Kim, Woojin Cho, Seungone Kim
1. Key Terms & Definitions (핵심 용어 및 정의)
- K-BrowseComp: 한국어 맥락(Korean contexts)에 특화된 400개의 웹 브라우징 에이전트 성능 평가용 벤치마크 데이터셋입니다.
- K-BrowseComp-Verified: 300개의 사람이 직접 작성하고 검증한 고난도 질문들로 구성된 핵심 평가 서브셋입니다.
- Parallel-branching: 질문 해결을 위해 여러 개의 독립적인 웹 사이트로부터 제약 조건을 수집하고 교차 분석해야 하는 reasoning 포맷입니다.
- Failure-mode Taxonomy: 에이전트의 브라우징 실패 원인을 9가지(F0-F8)로 분류한 체계로, 성능 분석 및 데이터 생성에 활용됩니다.
- Search_evals: 다양한 AI 에이전트의 웹 서칭 성능을 측정하기 위해 사용된 표준화된 평가 프레임워크입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 최신 Frontier 모델들이 Agentic Capability 평가로 패러다임을 전환하고 있음에도 불구하고, 한국어 환경에 특화된 브라우징 에이전트 벤치마크가 부재하다는 문제 의식에서 출발합니다. 기존 글로벌 벤치마크는 영미권 중심의 데이터와 웹 검색 관습을 기반으로 하여, 한국의 문화적, 지리적 지식 및 특정 웹 구조를 처리해야 하는 에이전트의 역량을 측정하는 데 한계가 있습니다. 특히 한국어 웹 에이전트는 검색된 정보 간의 복잡한 논리적 연결이나 한국 웹사이트 특유의 반정형화된 데이터 파싱에서 큰 성능 저하를 보입니다. 저자들은 이러한 격차를 해소하고 한국형 에이전트 개발을 위한 진단 도구를 제공하고자 본 벤치마크를 제안합니다 [Figure 1].
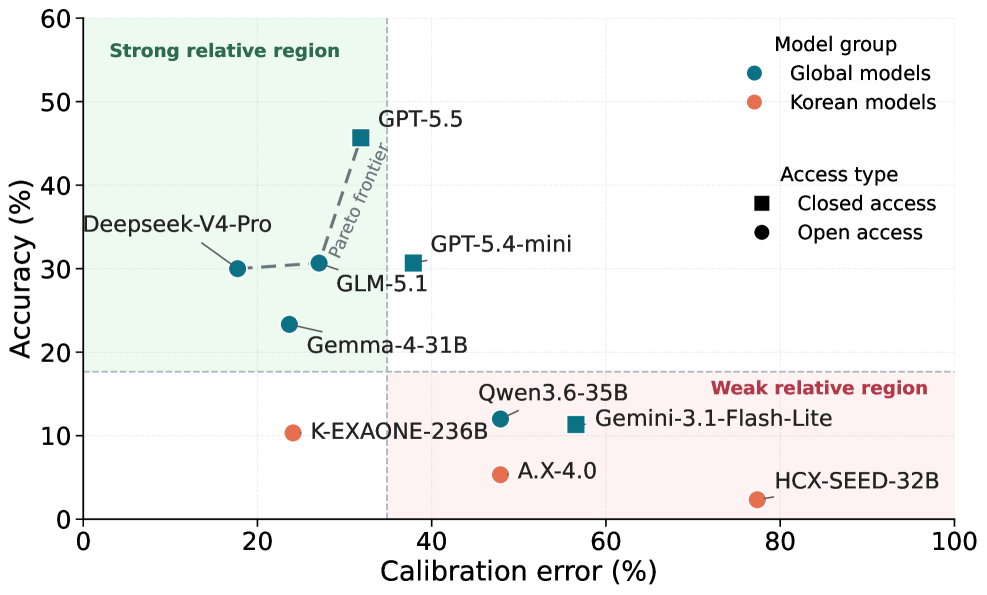
Figure 1 — 모델별 정확도 및 보정 오차
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 300개의 K-BrowseComp-Verified 문제와 100개의 인공지능 기반 Synthetic Diagnostic Split으로 구성된 평가 체계를 제안합니다. 데이터 구축 과정에서는 웹 브라우징 질문의 정보 비대칭성(문제 해결은 어렵지만 정답 확인은 쉬움)을 활용하여, 에이전트가 특정 Failure-mode를 타겟팅하도록 유도하는 역방향 생성 파이프라인을 도입하였습니다 [Table 1]. 성능 평가 결과, GPT-5.5가 45.67%로 가장 우수한 성적을 거두었으나, K-EXAONE-236B-A23B를 포함한 국내 주요 모델들은 0.00%~10.33%의 저조한 Pass@1 Acc.를 기록하며 큰 성능 차이를 보였습니다 [Table 2]. 특히 Synthetic split에서는 가장 성능이 좋은 모델조차 26.00% 이하의 정확도를 기록하여, 복합적인 Trajectory-level failure 상황에서 모델들의 한계가 극명하게 드러남을 확인했습니다. 주요 실패 유형으로는 후보군을 조기에 확정해버리는 Candidate Capture(F5) 및 여러 출처 간의 정보를 통합하지 못하는 Cross-source hopping failure(F3) 등이 관찰되었습니다 [Figure 4].

Figure 4 — 대표적인 에이전트 실패 유형
4. Conclusion & Impact (결론 및 시사점)
본 논문은 한국어 환경에 최적화된 브라우징 에이전트 벤치마크인 K-BrowseComp를 통해 한국 AI 생태계의 브라우징 에이전트 성능을 객관적으로 측정할 수 있는 기준을 마련했습니다. 연구 결과는 범용 모델과 한국어 특화 모델 간의 성능 격차뿐만 아니라, 에이전트가 복잡한 추론 과정에서 겪는 구조적인 실패 패턴을 구체적으로 식별했습니다. 이 벤치마크는 향후 한국형 Sovereign AI를 위한 에이전트 학습 및 고도화 연구에 핵심적인 진단 도구로 활용될 것으로 기대됩니다.
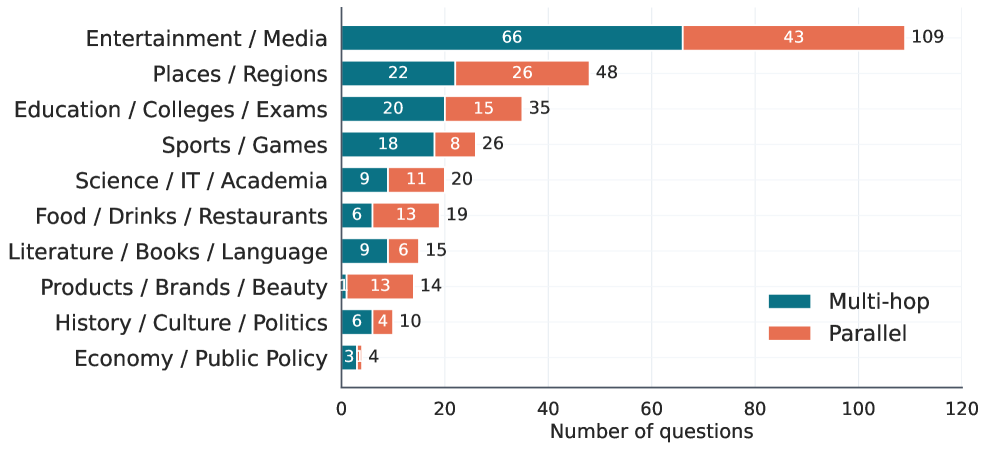
Figure 3 — 데이터셋 카테고리 분포
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When Search Agents Should Ask: DiscoBench for Clarification-Aware Deep Search
- [논문리뷰] Are We on the Right Way for Assessing Document Retrieval-Augmented Generation?
- [논문리뷰] GRASP: GRanularity-Aware Search Policy for Agentic RAG
- [논문리뷰] Quantifying and Expanding the Theoretical Capacity of Late-Interaction Retrieval Models
- [논문리뷰] DREAM: Dense Retrieval Embeddings via Autoregressive Modeling
Review 의 다른글
- 이전글 [논문리뷰] Joint Agent Memory and Exploration Learning via Novelty Signals
- 현재글 : [논문리뷰] K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
- 다음글 [논문리뷰] LVSA: Training-Free Sparse Attention for Long Video Diffusion
댓글