[논문리뷰] LVSA: Training-Free Sparse Attention for Long Video Diffusion
링크: 논문 PDF로 바로 열기
메타데이터
저자: Gael Glorian, Ioannis Lamprou, Zhen Zhang, Yujie Yuan, Hongsheng Liu
1. Key Terms & Definitions (핵심 용어 및 정의)
- LVSA (Long Video Sparse Attention): 긴 영상 생성 시 발생하는 dense self-attention의 이차 복잡도(quadratic complexity) 문제를 해결하기 위해 제안된 training-free 기반의 block-sparse attention 알고리즘입니다.
- VBench-Long: 영상 생성 모델의 성능을 평가하는 기존 벤치마크로, 논문에서는 정적인 영상에 대해 높은 점수를 부여하는 한계를 지적합니다.
- VQeval: dense attention의 긴 영상 생성 실패(반복적인 루프 현상 등)를 정확하게 평가하기 위해 저자들이 새로 도입한 평가 도구입니다.
- FlashInfer: block-sparse attention 계산을 가속화하기 위해 사용되는 커널로, LVSA와 결합하여 연산 효율성을 극대화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 video diffusion transformers의 긴 영상 생성 과정에서 발생하는 dense self-attention의 연산 효율성 저하와 품질 저하 문제를 해결합니다. 영상 길이에 따라 연산 비용이 이차적으로 증가하여 긴 영상 생성이 어려우며, 특정 학습 범위를 넘어서면 모델이 정적인 영상을 반복하는 "frozen" 현상이 발생합니다. 기존 연구들은 retraining이 필요하거나, 컴퓨팅 효율성과 영상 품질을 동시에 만족하지 못하는 한계가 있습니다 [Figure 1]. 따라서 본 연구는 training-free 방식의 효율적이고 확장성 있는 대안을 제시하고자 합니다.
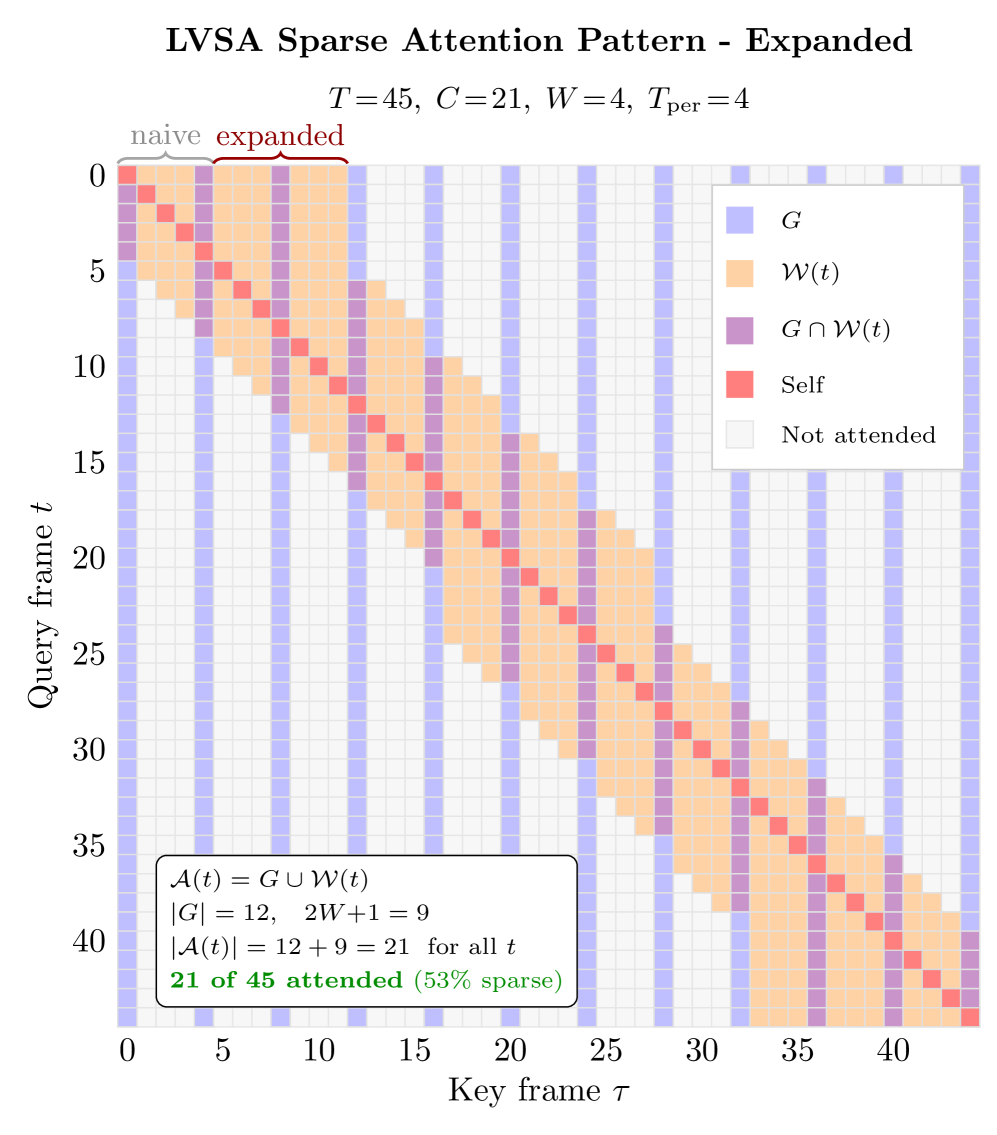
Figure 1 — LVSA의 확장된 윈도우 패턴 구조
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 LVSA를 제안하여 영상을 구성하는 각 프레임이 global anchors와 국소적인 local window에만 선택적으로 주의(Attention)를 기울이게 함으로써 연산 복잡도를 선형적으로 개선합니다. 특히 고정된 그리드 편향을 제거하기 위해 rotating periodic global frames 기법을 적용하여 denoising 단계마다 글로벌 프레임 위치를 변경함으로써 긴 영상에서도 시간적 일관성을 유지합니다 [Figure 2]. Wan 2.1 1.3B 모델 기준 6x horizon에서 dense attention 대비 3.17x의 속도 향상을 기록하였으며, HunyuanVideo 1.5 모델에서는 기존에 OOM(Out-Of-Memory)으로 인해 생성이 불가능했던 환경에서도 성공적으로 영상을 생성합니다 [Table 1], [Figure 3]. 또한 VQeval 평가 지표에서 타 기법(RIFLEx, UltraViCo) 대비 뛰어난 품질을 입증하였으며, NPU 환경에서도 최대 3.24x의 속도 향상을 확인했습니다.
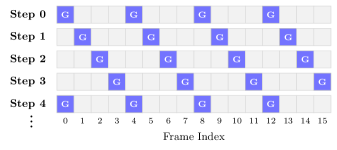
Figure 2 — 회전하는 글로벌 프레임 구조

Figure 3 — HunyuanVideo 2x 생성 예시
4. Conclusion & Impact (결론 및 시사점)
본 논문은 training-free block-sparse attention인 LVSA를 통해 긴 영상 생성의 연산 한계와 품질 저하 문제를 효과적으로 극복했습니다. 이 연구는 모델 구조 변경 없이 플러그인 형태로 즉각적인 효율성 향상을 제공하므로, 대규모 video generative models의 배포 및 추론 최적화에 중요한 실용적 가치를 지닙니다. 향후 다양한 하드웨어 가속기에서의 활용성과 다중 장면(multi-scene) 영상 생성으로의 확장이 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] FASA: Frequency-aware Sparse Attention
- [논문리뷰] LongCat-Video Technical Report
- [논문리뷰] MoGA: Mixture-of-Groups Attention for End-to-End Long Video Generation
- [논문리뷰] Mixture of Contexts for Long Video Generation
- [논문리뷰] Less Is More: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
Review 의 다른글
- 이전글 [논문리뷰] K-BrowseComp: A Web Browsing Agent Benchmark Grounded in Korean Contexts
- 현재글 : [논문리뷰] LVSA: Training-Free Sparse Attention for Long Video Diffusion
- 다음글 [논문리뷰] Linear Ensembles Wash Away Watermarks: On the Fragility of Distributional Perturbations in LLMs
댓글