[논문리뷰] DREAM: Dense Retrieval Embeddings via Autoregressive Modeling
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yixuan Tang, Yi Yang
1. Key Terms & Definitions (핵심 용어 및 정의)
- DREAM: Dense Retriever를 Autoregressive Modeling의 Next-Token Prediction Objective로 학습시키기 위해, Retrieval 점수를 Frozen LLM의 Attention Heads에 주입하는 제안 방법론입니다.
- Query-Focused Retrieval Heads: 입력 쿼리 토큰이 관련 컨텍스트에 높은 Attention 가중치를 할당하는 특정 Attention Heads로, DREAM에서 Retrieval 점수를 주입하는 인터페이스 역할을 합니다.
- Frozen LLM: 학습 과정 중 파라미터가 업데이트되지 않고, 오직 Retriever가 생성한 Retrieval 점수를 기반으로 타겟 passage를 예측하여 Retrieval 학습의 정답(Judge) 역할을 수행하는 거대 언어 모델입니다.
- NDCG@10: BEIR 및 RTEB 벤치마크에서 Retrieval 성능을 측정하기 위한 주요 평가지표로, 상위 10개 검색 결과의 순위 적합도를 평가합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존 Contrastive Learning 기반의 Dense Retriever 학습이 고비용의 레이블 데이터와 정교한 Hard Negative Mining을 필요로 하는 한계를 극복하고자 합니다. 기존 방식은 인위적으로 구성된 Positive/Negative 샘플에 의존하므로, 데이터 구축 병목 현상과 False Negative 문제에서 자유롭지 못합니다. 저자들은 이러한 수동적인 레이블링 없이, 대규모 언어 모델의 Autoregressive Next-Token Prediction (NTP) 능력을 활용하여 Retriever를 효과적으로 지도 학습할 수 있는 방법을 모색합니다. 특히, Retriever가 검색한 문맥이 LLM의 다음 토큰 예측 손실(Loss)을 얼마나 효과적으로 낮추는지를 측정함으로써 Retrieval 성능을 직접적으로 최적화하고자 합니다 [Figure 1].

Figure 1 — DREAM의 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Retrieval 점수를 Frozen LLM의 Query-Focused Attention Heads에 주입하여, 타겟 passage 예측 손실을 통해 Retriever를 학습시키는 DREAM 프레임워크를 제안합니다 [Figure 1]. Retriever는 쿼리와 후보 문서 간의 유사도를 계산하고, 이 점수는 Attention 가중치를 조절하여 LLM이 관련 문서를 더 효과적으로 참조하도록 유도합니다. 실험 결과, DREAM은 BEIR 및 RTEB 벤치마크에서 Llama-3.2 및 Qwen2.5 기반 백본 모델을 사용했을 때 기존의 RePlug나 Revela 대비 일관되게 우수한 성능을 보였습니다. 특히 NDCG@10 지표에서 BEIR 기준 최대 0.081, RTEB 기준 최대 0.102의 성능 향상을 기록했습니다 [Table 1]. 또한, 무작위 Attention Heads를 사용하는 경우보다 Query-Focused 헤드를 선택했을 때 성능이 월등히 높음을 확인하여 제안 방법론의 유효성을 입증했습니다 [Figure 2].
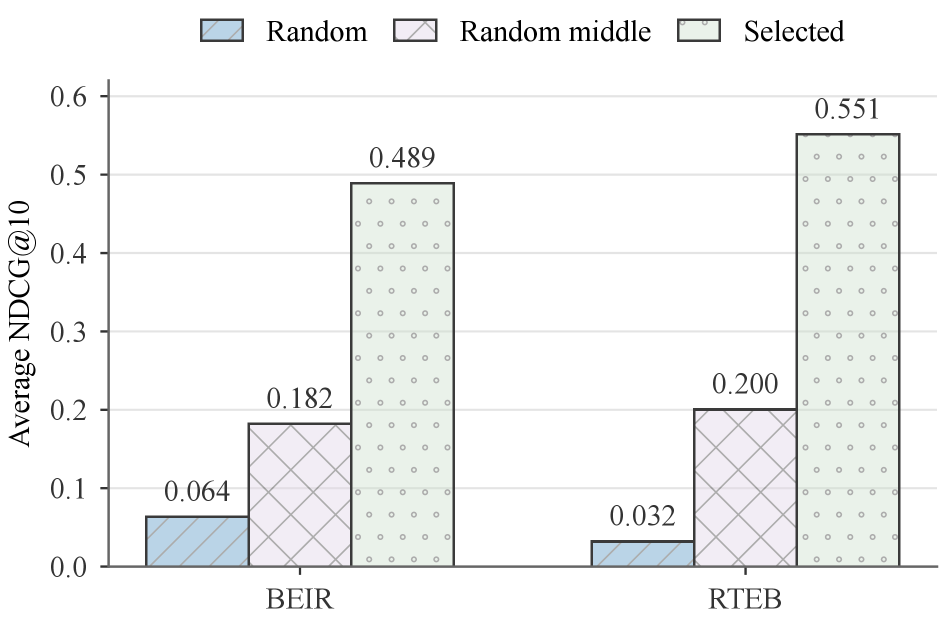
Figure 2 — 헤드 선택 분석 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Autoregressive Next-Token Prediction을 활용하여 추가적인 레이블 없이도 강력한 Dense Retriever를 학습시킬 수 있음을 입증했습니다. Retrieval 점수를 LLM의 Attention 메커니즘에 직접 주입하는 DREAM은 기존의 Contrastive 학습 방식을 대체할 수 있는 실용적이고 확장 가능한 접근법을 제시합니다. 이러한 결과는 Retriever와 LLM 간의 새로운 상호작용 방식으로서, 향후 정보 검색 및 Retrieval-Augmented Generation (RAG) 시스템 설계에 중요한 학술적 시사점을 제공합니다.
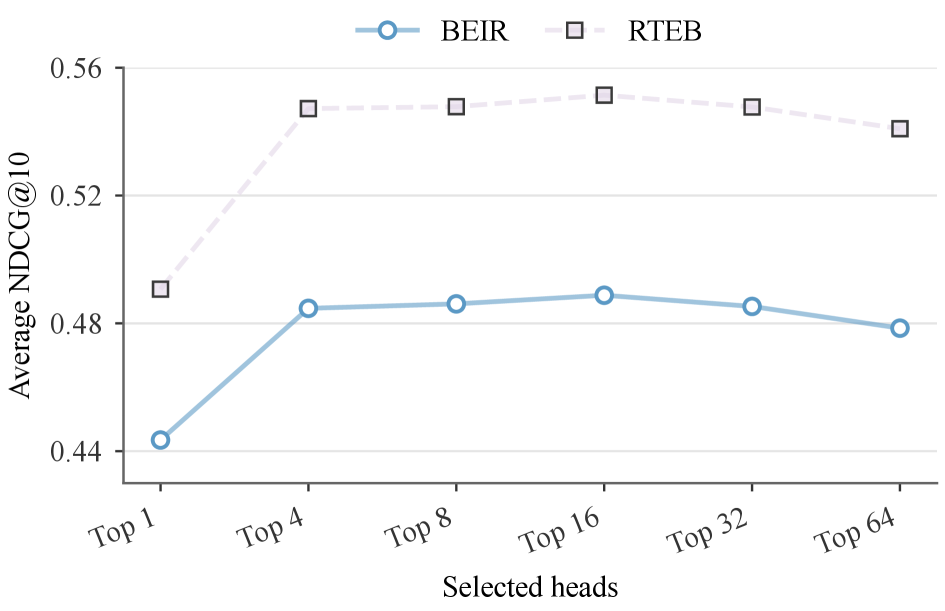
Figure 3 — 선택된 헤드 수에 따른 성능
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Beyond Hard Negatives: The Importance of Score Distribution in Knowledge Distillation for Dense Retrieval
- [논문리뷰] LongCat-Next: Lexicalizing Modalities as Discrete Tokens
- [논문리뷰] TurkColBERT: A Benchmark of Dense and Late-Interaction Models for Turkish Information Retrieval
- [논문리뷰] Unified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
- [논문리뷰] Dr-DCI: Scaling Direct Corpus Interaction via Dynamic Workspace Expansion
Review 의 다른글
- 이전글 [논문리뷰] ChartWalker: Benchmarking the Cross-Chart RAG Task
- 현재글 : [논문리뷰] DREAM: Dense Retrieval Embeddings via Autoregressive Modeling
- 다음글 [논문리뷰] DiffusionBench: On Holistic Evaluation of Diffusion Transformers
댓글