[논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
링크: 논문 PDF로 바로 열기
메타데이터
저자: Yang Tian, Rui Wang, Xumeng Wen, Junjie Li, Shizhao Sun, Lei Song, Jiang Bian, Bo Zhao
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 최종 결과의 정확성을 자동 검증할 수 있는 환경에서 LLM을 학습시키는 패러다임.
- PBSD (Privileged Bayesian Self-Distillation): 정답 정보를 포함한 Privileged 정보를 활용하여, 중간 추론 단계의 기여도를 Bayesian evidence score로 계산하고 이를 통해 turn-level credit을 재보정하는 방법론.
- Bayesian Evidence Score: 주어진 turn의 행동이 최종 정답(y*)의 가능성을 얼마나 높이는지를 student 모델과 answer-conditioned teacher 모델의 likelihood 비율로 측정한 지표.
- GRPO (Group Relative Policy Optimization): 여러 trajectory를 샘플링하고 그룹 내 보상 비교를 통해 정책을 최적화하는 온폴리시(on-policy) 강화학습 알고리즘.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 long-horizon agentic task에서 발생하는 sparse reward로 인한 credit assignment의 근본적인 한계를 해결하고자 한다. 기존의 outcome-based RLVR은 최종 결과물에만 보상을 제공하므로, 수백 번의 turn을 거치는 복잡한 검색 및 추론 과정에서 어떤 중간 단계가 실질적인 기여를 했는지 평가하지 못하는 문제가 있다. 기존의 rubric 기반 평가나 tree-search 기반 추정은 비용이 높거나 불필요한 보상 편향(reward hacking)을 유발할 위험이 있다. 저자들은 이러한 제약 조건 하에서, 중간 행동들이 최종 결과에 미치는 증거적 가치를 정량적으로 평가할 수 있는 새로운 접근 방식의 필요성을 제시한다 [Figure 1].
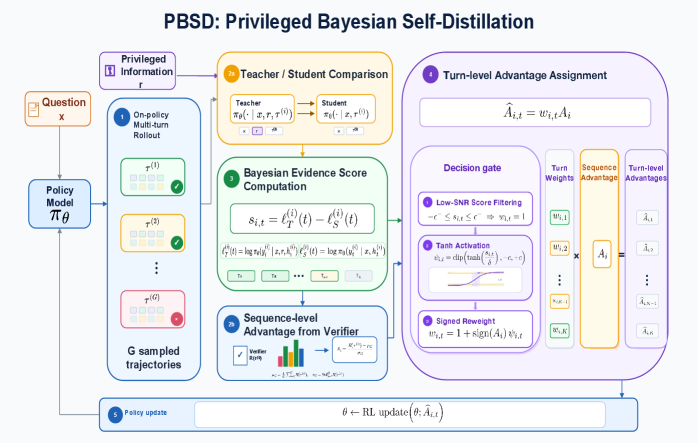
Figure 1 — PBSD 프레임워크 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 trajectory-level의 정답 정보를 이용해 중간 단계의 행동을 재평가하는 PBSD 프레임워크를 제안한다. PBSD는 Bayes’ rule을 적용하여 posterior-to-prior 확률비를 추정 가능한 likelihood 비율(student 모델 vs. answer-conditioned teacher 모델)로 변환하며, 이를 통해 각 turn의 기여도를 나타내는 Bayesian evidence score를 도출한다 [Figure 1]. 저자들은 이 점수를 사용하여 기존 GRPO의 trajectory-level advantage를 turn-level로 정교하게 재보정(reweighting)하며, 저신뢰도(low-SNR) 구간의 노이즈를 필터링하는 메커니즘을 포함한다.
실험 결과, PBSD는 30B MoE 모델 환경에서 기존 GRPO 대비 성능을 유의미하게 개선하였다. 특히 BrowseComp(300) 벤치마크에서 GRPO와 비교하여 검증 정확도를 3.50 포인트 이상 향상시켰으며, 학습 초기 단계부터 더 안정적인 수렴과 높은 점수를 기록하였다 [Figure 2]. 또한, 64K context로 학습되었음에도 불구하고 256K context를 요구하는 환경으로의 강력한 일반화 성능을 입증하였다.
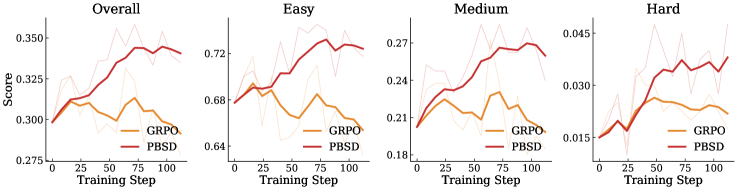
Figure 2 — BrowseComp 성능 비교
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Bayesian evidence calibration을 통해 복잡한 agentic task에서 발생하는 credit assignment 문제를 해결하는 효과적이고 확장 가능한 프레임워크를 제시한다. PBSD는 외부 평가자나 추가적인 비용 없이도 모델 자체의 likelihood 비율만을 활용하여 정교한 turn-level supervision을 생성할 수 있음을 보여주었다. 이 연구는 강화학습을 활용한 long-horizon agent 학습에서 데이터 효율성을 크게 높이고, 추론 과정의 투명성을 개선하여 실제 서비스 환경에서의 모델 성능과 신뢰성을 확보하는 데 중요한 시사점을 제공한다.
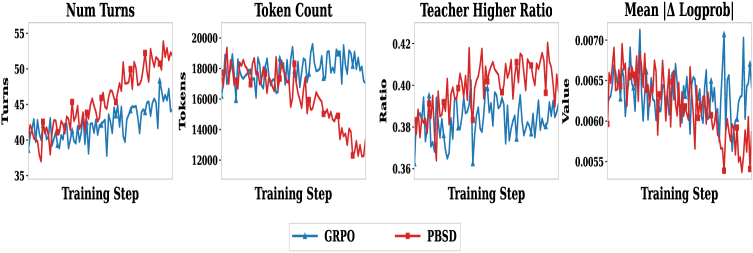
Figure 3 — GRPO와 PBSD 학습 동학
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reinforcement Learning from Rich Feedback with Distributional DAgger
- [논문리뷰] Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
- [논문리뷰] GDSD: Reinforcement Learning as Guided Denoiser Self-Distillation for Diffusion Language Models
- [논문리뷰] HINT-SD: Targeted Hindsight Self-Distillation for Long-Horizon Agents
- [논문리뷰] Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
Review 의 다른글
- 이전글 [논문리뷰] Optical Reasoning: Rethinking Images as an Expressive Reasoning Medium Beyond Text
- 현재글 : [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- 다음글 [논문리뷰] PIPE-Cypher: Automatic Enterprise Benchmark Generation for Text-to-Cypher Systems
댓글