[논문리뷰] PIPE-Cypher: Automatic Enterprise Benchmark Generation for Text-to-Cypher Systems
링크: 논문 PDF로 바로 열기
메타데이터
저자: Suraj Ranganath, Anish Raghavendra
1. Key Terms & Definitions (핵심 용어 및 정의)
- Text2Cypher: 자연어 질의를 Cypher 쿼리로 변환하여 그래프 데이터베이스에서 정보를 추출하는 작업을 지칭합니다.
- Reverse-Query Grounding: 실제 그래프 데이터로부터 유효한 결과값을 역으로 추출하여, 자연어 질문이 해당 그래프에서 반드시 답변 가능하도록 보장하는 기법입니다.
- Deterministic Governance: 생성된 쿼리의 안전성 및 정확성을 보장하기 위해 룰 기반의 문법 검사, Schema 일치성 확인, 방향성 제약 등을 강제하는 검증 계층입니다.
- Execution Validation: 생성된 Cypher 쿼리를 실제 그래프 환경에서 실행하여 쿼리 결과의 존재 여부와 런타임 오류를 사전에 필터링하는 품질 보증 과정입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기업 내 Property Graph 환경에서 신뢰할 수 있는 Text2Cypher 평가를 위한 반복 가능하고 자동화된 벤치마크 생성 파이프라인의 부재 문제를 해결합니다. 기존의 정적 벤치마크는 기업 고유의 Schema 구조나 데이터 변화를 반영하지 못하며, 모델이 생성한 쿼리의 실행 가능성이나 보안성을 보장하기 어렵습니다. 저자들은 데이터 보안 및 개인정보 보호를 위해 외부 API 의존 없이 기업 내부에서 안전하게 실행 가능한 자동화 벤치마크 생성 시스템인 PIPE-Cypher를 제안합니다 [Figure 1].
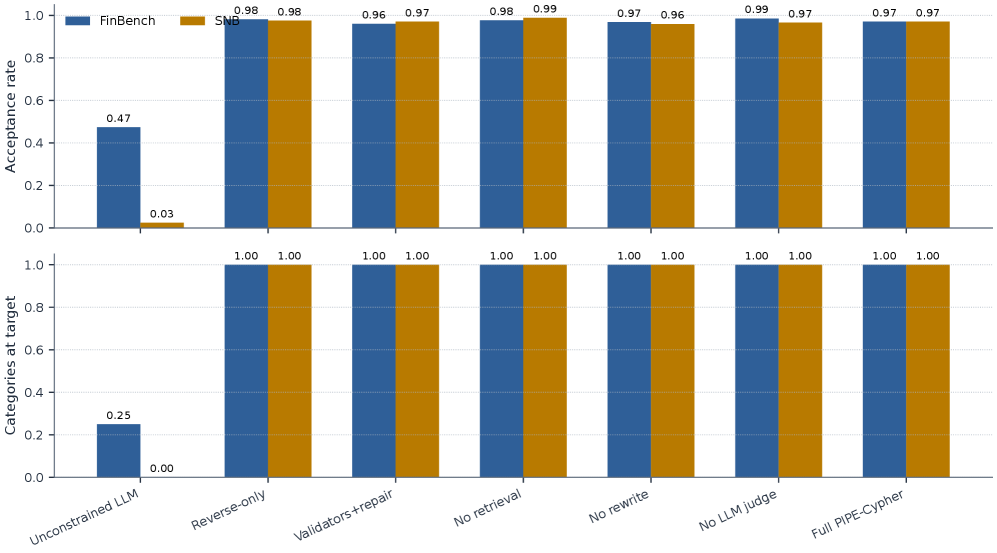
Figure 1 — PIPE-Cypher 파이프라인 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Schema 프로파일링, 워크로드 계획, Reverse-Query Grounding, Constrained Generation, Deterministic Validation, 그리고 LLM-judge 리뷰로 이어지는 6단계 자동화 파이프라인을 제안합니다 [Figure 1]. 저자들은 Qwen3.5-9B 모델을 활용하여 FinBench 및 SNB 데이터셋 기반의 3,000개 벤치마크 예제를 성공적으로 생성하였습니다 [Table 2]. 주요 실험 결과, PIPE-Cypher로 생성된 벤치마크는 100%의 범주별 타겟 달성률을 보였으며, 인간 평가자와의 일치도가 Cohen’s κ=0.60으로 나타나 높은 정밀도를 입증했습니다. 또한, 11개 로컬 모델에 대한 Downstream 평가 결과, No-signature 조건 하에서 벤치마크를 활용한 Few-shot 학습이 평균 실행 정확도를 0.036에서 0.200으로 크게 향상시켰음을 확인하였습니다 [Table 4].
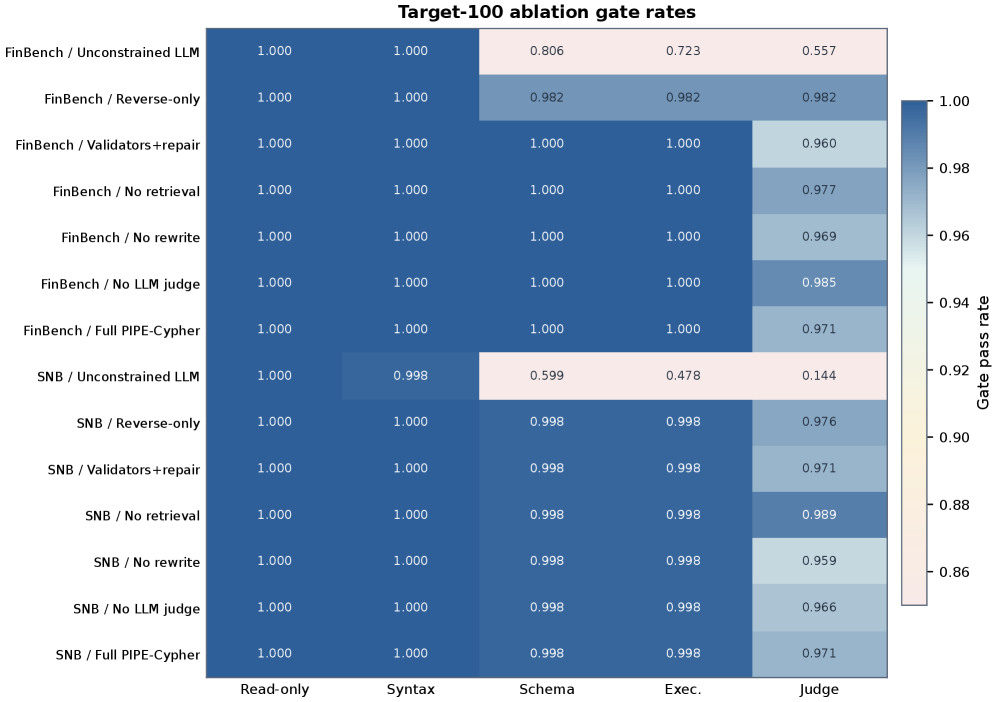
Table 2 — 생성 및 수락 통계
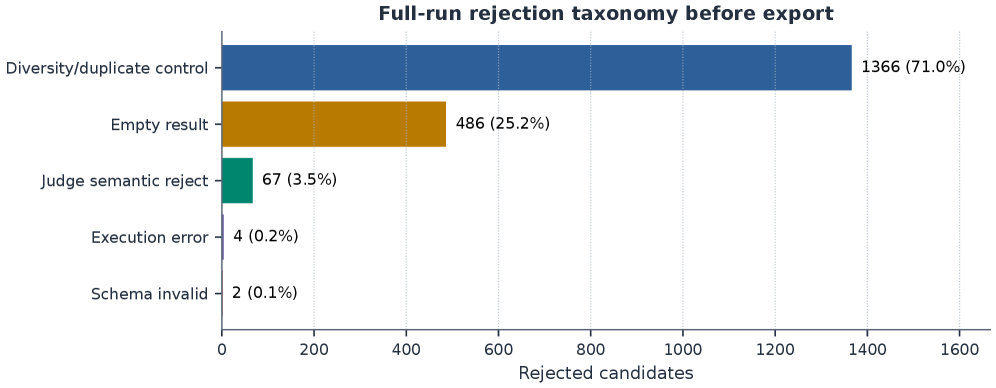
Table 4 — Downstream 전이 실험 결과
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Text2Cypher 벤치마크 생성을 단순한 데이터 수집이 아닌, 기업의 환경 변화에 대응 가능한 반복적인 Enterprise Workflow로 재정의합니다. 제안된 파이프라인은 보안이 유지되는 로컬 환경에서 실행 가능한 벤치마크를 생성함으로써, 조직이 자사의 특정 Schema와 데이터 정책에 최적화된 모델 평가를 수행할 수 있게 합니다. 이는 향후 산업계의 그래프 기반 자연어 인터페이스 구축 및 모델 신뢰성 검증에 중요한 기술적 토대를 제공할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] A2RBench: An Automatic Paradigm for Formally Verifiable Abstract Reasoning Benchmark Generation
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback
- [논문리뷰] WeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
- [논문리뷰] WEAVER, Better, Faster, Longer: An Effective World Model for Robotic Manipulation
Review 의 다른글
- 이전글 [논문리뷰] PBSD: Privileged Bayesian Self-Distillation for Long-Horizon Credit Assignment
- 현재글 : [논문리뷰] PIPE-Cypher: Automatic Enterprise Benchmark Generation for Text-to-Cypher Systems
- 다음글 [논문리뷰] Phase Marginalization for Patch-Grid Instability in Vision Transformers
댓글