[논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
링크: 논문 PDF로 바로 열기
메타데이터
저자: Xiaoxuan He, Siming Fu, Zeyue Xue, Weijie Wang, Ruizhe He, Yuming Li, Dacheng Yin, Shuai Dong, Haoyang Huang, Hongfa Wang, Nan Duan, Bohan Zhuang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- GRPO (Group Relative Policy Optimization): 다수의 Rollout 그룹 내에서 상대적인 보상을 계산하여 정책을 최적화하는 Reinforcement Learning 패러다임입니다.
- Iso-temporal Grouping: 특정 프롬프트 그룹 내 모든 Rollout이 동일한 타임스텝에서 탐색을 수행하도록 강제하여, 타임스텝에 따른 난이도 차이가 보상 분산에 미치는 영향을 제거하는 기법입니다.
- Temporal Gradient Rectification: 타임스텝에 따라 달라지는 정책 그래디언트의 크기를 정규화하여, 모든 타임스텝이 최적화 과정에 균등하게 기여하도록 보정하는 메커니즘입니다.
- Wan2.1: 본 논문에서 기반 모델(Foundation Model)로 사용된 대규모 비디오 확산 모델 시리즈입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 Video Diffusion Model의 효율적인 정렬(Alignment)을 위한 단일 단계(Single-step) 훈련 프레임워크인 Flash-GRPO를 제안합니다 [Figure 1]. 기존 GRPO 기반의 정렬 방법은 전체 Denoising 궤적에 대해 그래디언트를 계산해야 하므로 연산 비용이 매우 높고 확장성이 부족하다는 한계가 있습니다. 기존의 효율적인 기법들은 슬라이딩 윈도우 서브샘플링을 통해 비용을 줄이려 시도했으나, 이는 훈련의 불안정성을 초래하고 전체 궤적 훈련 성능에 도달하지 못하는 최적화 문제를 야기합니다. 이러한 문제의 핵심 원인은 타임스텝에 따른 보상 분산의 혼재와 타임스텝 의존적인 그래디언트 크기 불균형에 있습니다 [Figure 1].
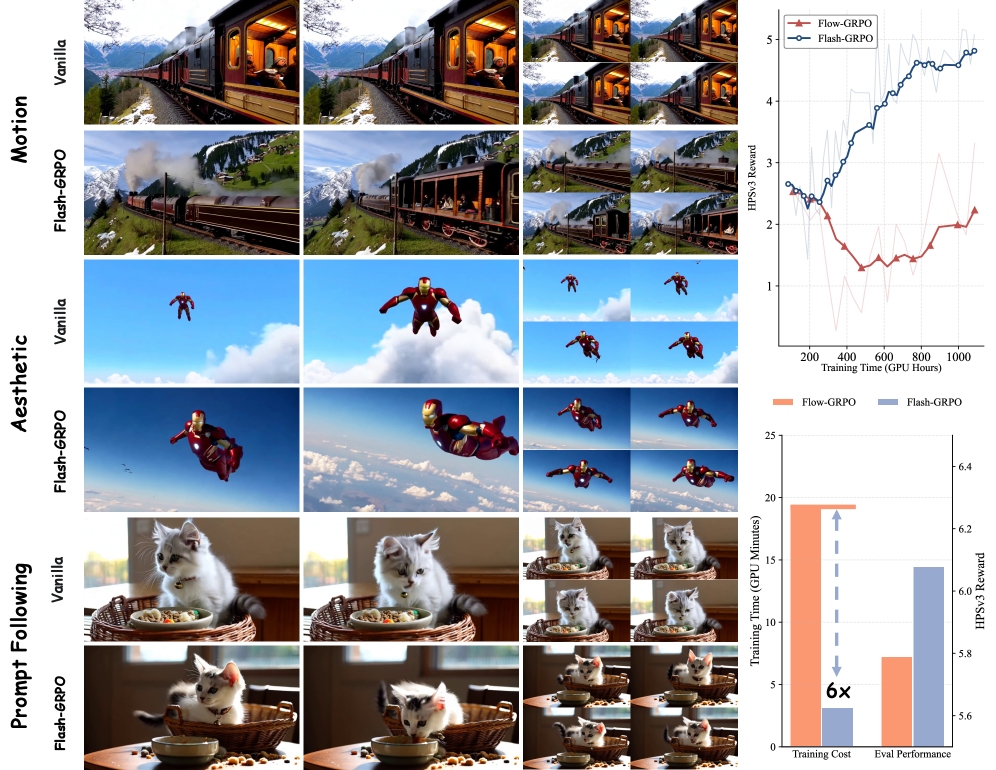
Figure 1 — Flash-GRPO 성능 개요
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Iso-temporal Grouping과 Temporal Gradient Rectification을 결합한 Flash-GRPO를 통해 단일 단계 훈련만으로 전체 궤적 성능을 달성합니다 [Figure 2]. Iso-temporal Grouping은 프롬프트 그룹 내 모든 샘플이 동일한 타임스텝을 공유하게 함으로써 타임스텝 간의 난이도 차이로 인한 편향을 제거합니다 [Figure 2]. Temporal Gradient Rectification은 SDE 이산화 과정에서 발생하는 시간 의존적 스케일링 인자 λ(t)를 명시적으로 정규화하여 그래디언트의 불균형을 해결합니다 [Figure 2]. 실험 결과, 1.3B 및 14B 파라미터 모델에서 기존 효율적 방법론(Flow-GRPO-Fast1) 대비 더 높은 안정성을 확보했습니다 [Table 1]. 특히 VBench 지표에서 Flash-GRPO는 Aesthetic Quality(66.43)와 Subject Consistency(98.70)에서 가장 우수한 성능을 기록하며, 기존 전체 궤적 훈련 방법 대비 6배 이상의 효율적인 훈련 가속을 입증했습니다 [Table 1, Figure 5].
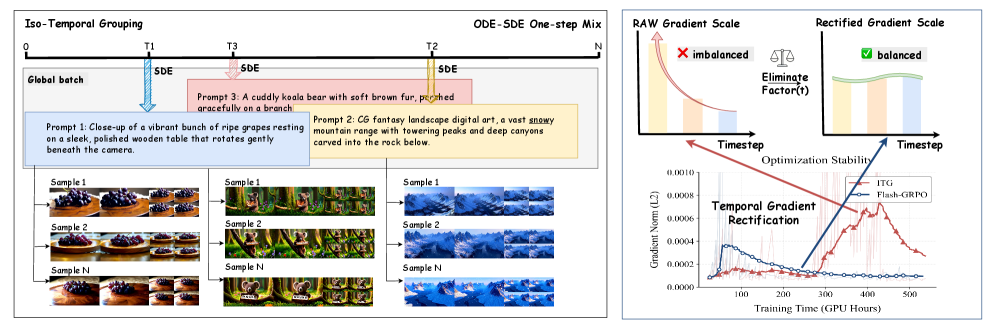
Figure 2 — Flash-GRPO 프레임워크 구조
4. Conclusion & Impact (결론 및 시사점)
본 논문은 비디오 확산 모델 정렬 과정에서 발생하는 계산적 병목 현상을 해결하는 강력한 단일 단계 최적화 프레임워크인 Flash-GRPO를 성공적으로 도입했습니다. 제안된 방법론은 타임스텝 혼재와 그래디언트 규모 불균형이라는 핵심적인 이론적 난제를 해결하여, 대규모 모델에서도 안정적인 성능 개선을 가능하게 합니다. 이 연구는 고성능 비디오 생성 모델의 RL 정렬을 더욱 실용적이고 확장 가능하게 만들어, 학계와 산업계의 효율적인 모델 튜닝 파이프라인 구축에 중요한 기여를 할 것으로 기대됩니다.
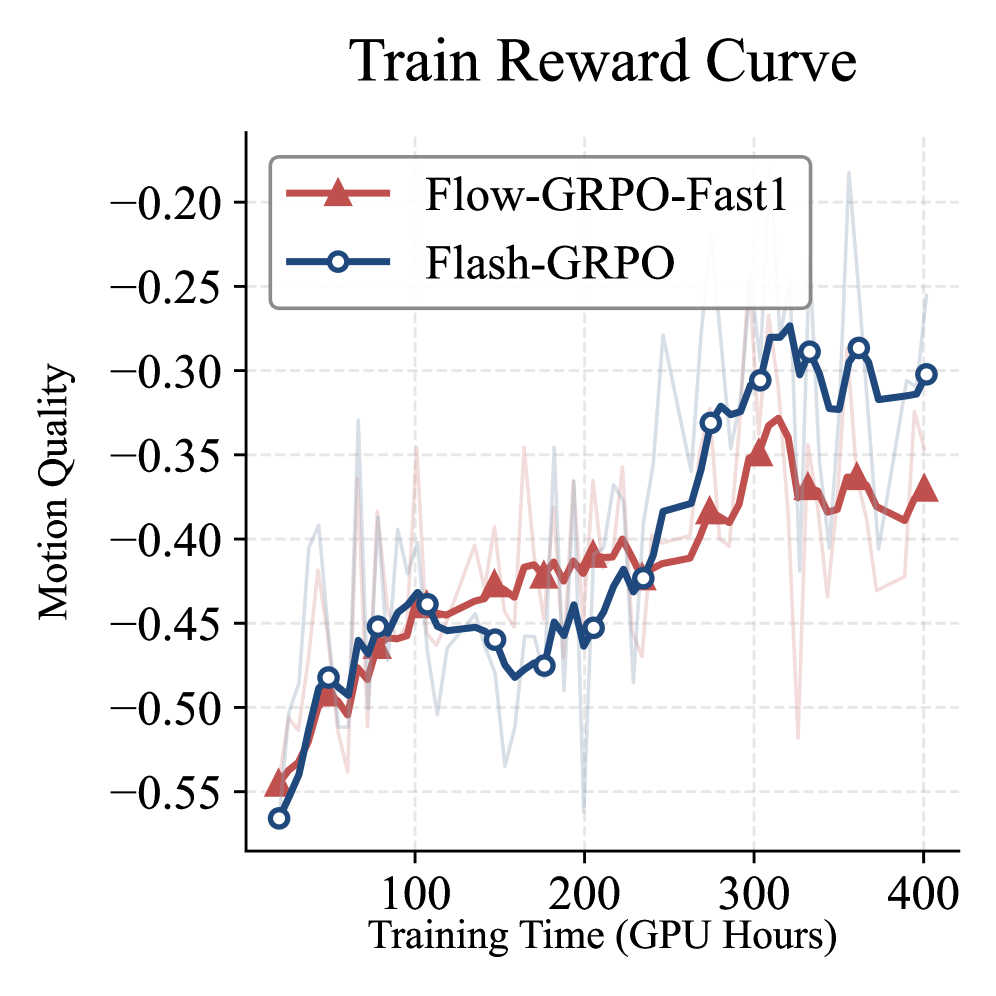
Figure 5 — 전체 궤적 방식과의 보상 곡선 비교
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
- [논문리뷰] The Mirage of Optimizing Training Policies: Monotonic Inference Policies as the Real Objective for LLM Reinforcement Learning
- [논문리뷰] RL-Index: Reinforcement Learning for Retrieval Index Reasoning
- [논문리뷰] GD^2PO: Mitigating Multi-Reward Conflicts via Group-Dynamic reward-Decoupled Policy Optimization
Review 의 다른글
- 이전글 [논문리뷰] FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization
- 현재글 : [논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
- 다음글 [논문리뷰] From Plans to Pixels: Learning to Plan and Orchestrate for Open-Ended Image Editing
댓글