[논문리뷰] DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
링크: 논문 PDF로 바로 열기
저자: Yujie Wei*, Xinyu Liu*, et al.
1. Key Terms & Definitions
- DreamVideo-Omni : 본 논문에서 제안하는 통합 프레임워크로, Omni-Motion control 및 Multi-Subject 비디오 맞춤 생성을 지원합니다.
- DiT (Diffusion Transformer) : 비디오 생성 모델의 백본 아키텍처로 사용되는 Transformer 기반의 확산 모델입니다.
- LIRM (Latent Identity Reward Model) : 비디오의 latent space 에서 identity preservation 을 평가하고 보상을 제공하기 위해 VDM (Video Diffusion Model) 백본 위에 구축된 특수 모델입니다.
- LIReFL (Latent Identity Reward Feedback Learning) : LIRM 을 활용하여 latent space 에서 직접 identity 보상 피드백을 학습하는 reinforcement learning 패러다임입니다.
- DreamOmni Bench : Multi-Subject 일관성 및 omni-motion control 정밀도를 통합적으로 평가하기 위해 본 논문에서 새로 구축한 대규모 벤치마크 데이터셋입니다.
2. Motivation & Problem Statement
대규모 diffusion models 가 비디오 합성 능력을 혁신했지만, multi-subject identity 와 multi-granularity motion 에 대한 정밀한 제어는 여전히 중대한 과제로 남아있습니다. 기존 연구들은 subject-driven 방식과 motion-controlled 방식으로 분리되어, 전자는 identity 일관성이 부족하고 후자는 omni-motion control 및 user-specified subjects 맞춤화에 한계가 있었습니다. 이러한 문제를 해결하기 위한 통합 프레임워크 시도는 종종 subject preservation 과 motion control 사이의 내재적인 trade-off 로 인해 suboptimal performance 를 보였습니다.
구체적으로, 기존 방법론은 1) bounding boxes , depth maps , sparse trajectories 와 같은 단일 유형의 motion signal 에 의존하여 global object placement , fine-grained local dynamics , camera movement 의 동시 제어가 어려워 Limited Motion Control Granularity 를 가집니다. 2) conditioning signals 을 명시적인 바인딩 메커니즘 없이 무분별하게 주입하여 multi-subject scenarios 에서 Motion Control 에 Ambiguity 를 초래했습니다. 3) static reference image 의 pixel-level consistency 와 dynamic pixel variation 사이의 충돌로 인해 특히 큰 움직임에서 fine-grained identity details 가 손상되는 Identity Degradation 문제가 발생했습니다. 본 연구는 이러한 문제점을 해결하여 multi-subject 환경에서 omni-motion control 을 통해 조화로운 비디오 맞춤화를 달성하는 데 중점을 둡니다.
3. Method & Key Results
저자들은 multi-subject customization 과 omni-motion control 을 조화롭게 통합하는 DreamVideo-Omni 라는 통일된 프레임워크를 제안합니다. 이 프레임워크는 progressive two-stage training paradigm 을 따릅니다
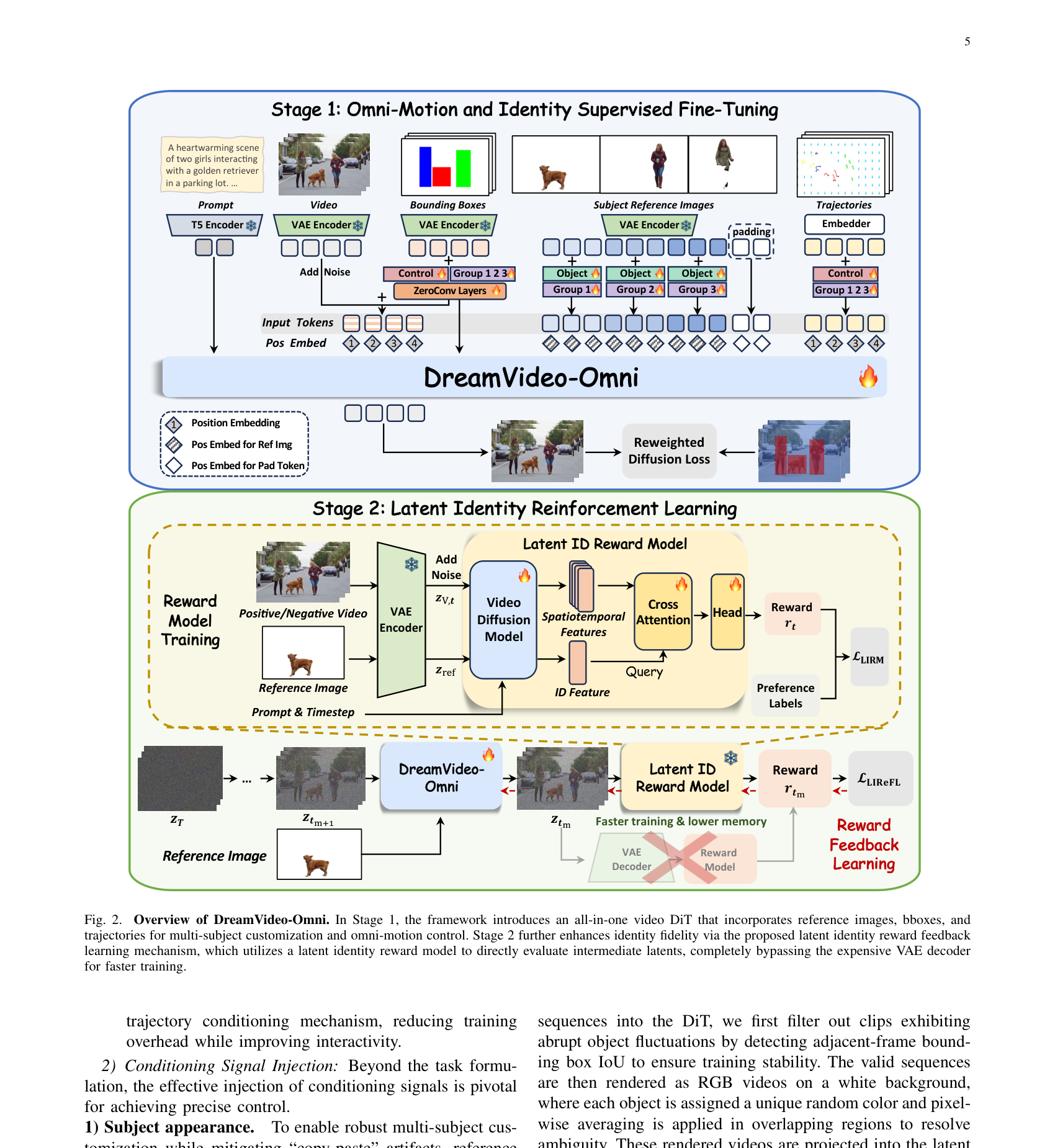 Figure 2: Overview of DreamVideo-Omni. In Stage 1, the framework introduces an all-in-one video DiT that incorporates reference images, bboxes, and trajectories for multi-subject customization and omni-motion control. Stage 2 further enhances identity fidelity via the proposed latent identity reward feedback learning mechanism, which utilizes a latent identity reward model to directly evaluate intermediate latents, completely bypassing the expensive VAE decoder for faster training.
Figure 2: Overview of DreamVideo-Omni. In Stage 1, the framework introduces an all-in-one video DiT that incorporates reference images, bboxes, and trajectories for multi-subject customization and omni-motion control. Stage 2 further enhances identity fidelity via the proposed latent identity reward feedback learning mechanism, which utilizes a latent identity reward model to directly evaluate intermediate latents, completely bypassing the expensive VAE decoder for faster training.
.
첫 번째 단계인 Omni-Motion and Identity Supervised Fine-Tuning (SFT) 에서는 subject appearances , global motion (bounding boxes) , local dynamics (sparse point-wise trajectories) , camera movements 를 아우르는 포괄적인 control signals 을 DiT 아키텍처에 통합합니다. 이를 위해 heterogeneous inputs 를 효과적으로 처리하는 condition-aware 3D RoPE 와 global motion guidance 를 강화하는 hierarchical motion injection strategy 를 도입합니다. 또한, multi-subject ambiguity 를 해결하기 위해 group and role embeddings 를 사용하여 motion signals 을 특정 identities 에 명시적으로 연결합니다.
두 번째 단계인 Latent Identity Reward Feedback Learning (LIReFL) 에서는 identity degradation 을 완화하기 위해 latent space 에서 reward feedback strategy 를 사용합니다. 사전 훈련된 VDM (Video Diffusion Model) 백본 위에 LIRM (Latent Identity Reward Model) 을 훈련시켜 motion-aware identity rewards 를 제공하며, 이는 human preferences 에 부합하는 identity preservation 을 우선시합니다. LIRM 은 VDM 의 시공간적 priors 를 활용하여 motion dynamics 와 통합된 video-level identity consistency 를 평가하고, latent space 에서 보상을 계산하여 computationally efficient training 을 가능하게 합니다.
실험 결과, DreamVideo-Omni 는 DreamOmni Bench 에서 DreamVideo-2 [17] 대비 모든 지표에서 우수한 성능을 보였습니다
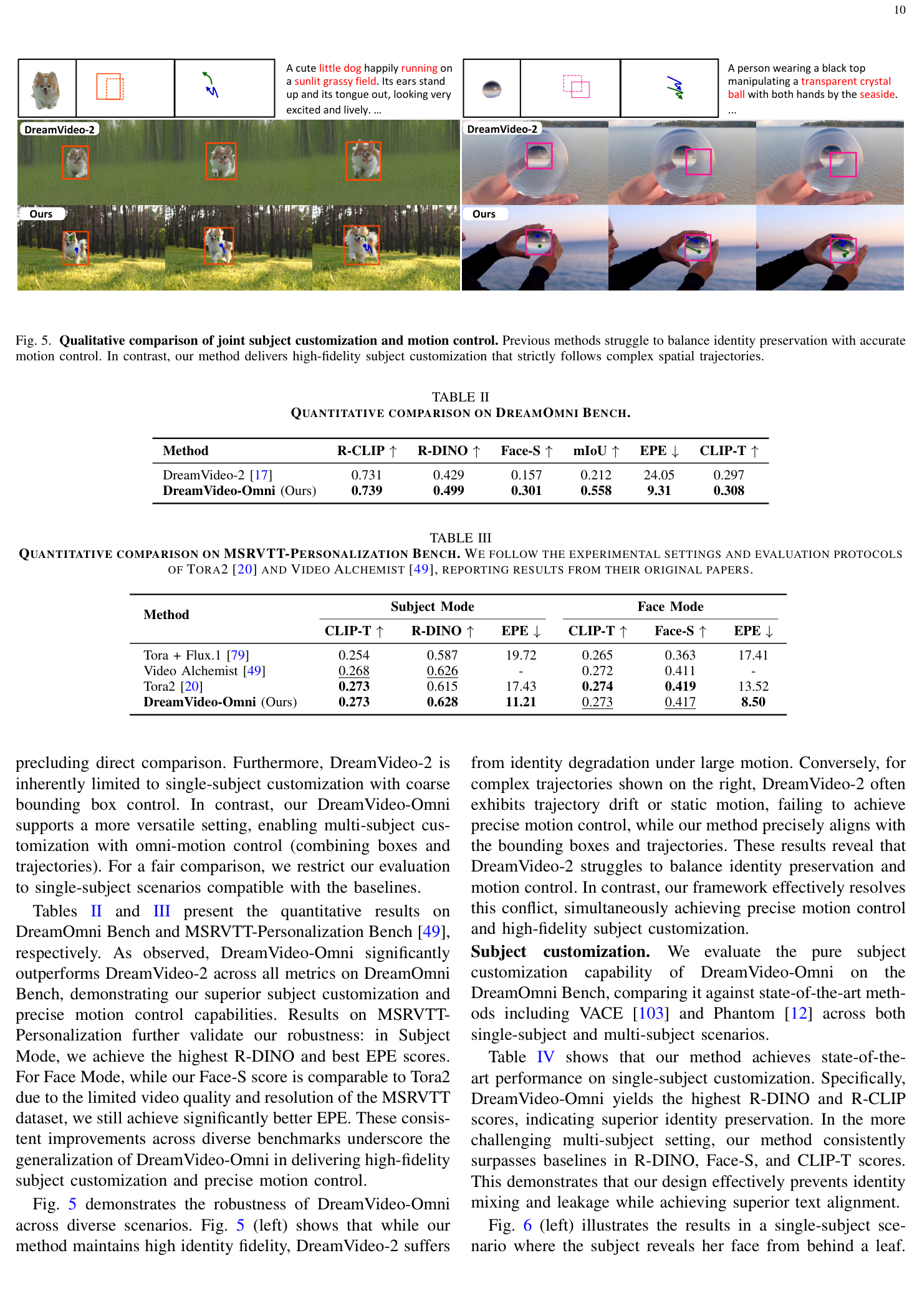 Table II: QUANTITATIVE COMPARISON ON DREAMOMNI BENCH.
Table II: QUANTITATIVE COMPARISON ON DREAMOMNI BENCH.
. 특히, R-CLIP 은 0.739 로 DreamVideo-2 의 0.731 을, mIoU 는 0.558 로 0.212 를 크게 상회했습니다. MSRVTT-Personalization Bench 에서는 Subject Mode 에서 가장 높은 R-DINO (0.628) 및 가장 낮은 EPE (11.21) 를 달성했습니다 [Table III]. Face Mode 에서는 Face-S 는 Tora2 [20] 와 유사했지만 EPE 는 8.50 으로 훨씬 뛰어났습니다. Ablation studies 를 통해 condition-aware 3D RoPE , group and role embeddings , hierarchical BBox injection , 그리고 LIReFL 의 각 구성 요소가 성능에 결정적인 역할을 함이 검증되었습니다
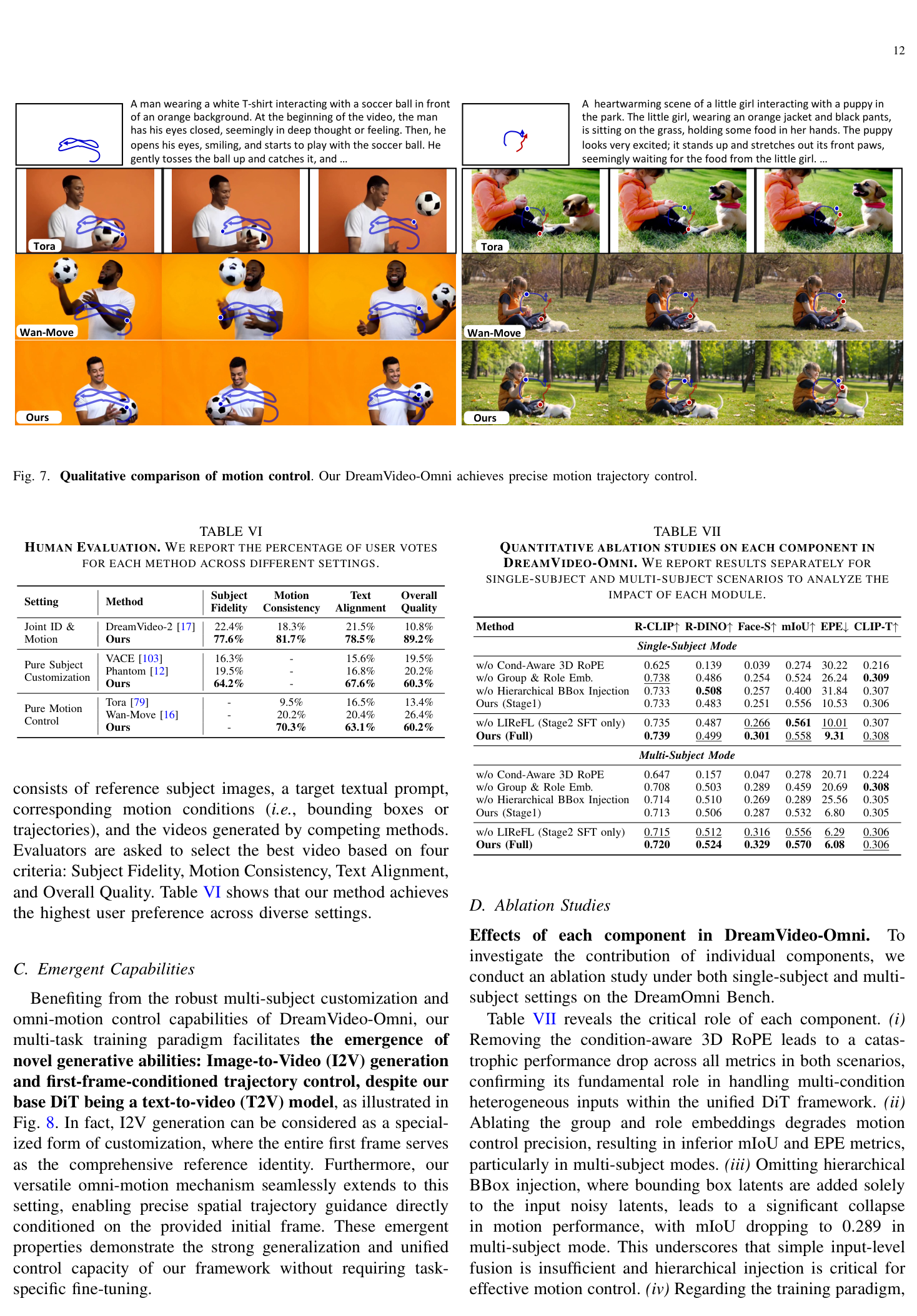 Table VII: QUANTITATIVE ABLATION STUDIES ON EACH COMPONENT IN DREAMVIDEO-OMNI. WE REPORT RESULTS SEPARATELY FOR SINGLE-SUBJECT AND MULTI-SUBJECT SCENARIOS TO ANALYZE THE IMPACT OF EACH MODULE.
Table VII: QUANTITATIVE ABLATION STUDIES ON EACH COMPONENT IN DREAMVIDEO-OMNI. WE REPORT RESULTS SEPARATELY FOR SINGLE-SUBJECT AND MULTI-SUBJECT SCENARIOS TO ANALYZE THE IMPACT OF EACH MODULE.
. 또한, 본 프레임워크는 text-to-video (T2V) 기반 모델임에도 불구하고 zero-shot Image-to-Video (I2V) generation 및 first-frame-conditioned trajectory control 과 같은 새로운 generative capabilities 를 보였습니다 [Figure 8].
4. Conclusion & Impact
본 논문은 DreamVideo-Omni 를 통해 multi-subject customization 과 omni-motion control 을 조화롭게 통합하는 통일된 프레임워크를 성공적으로 제시했습니다. Progressive two-stage training paradigm 과 condition-aware 3D RoPE , hierarchical motion injection , group and role embeddings 같은 특수 아키텍처 구성 요소를 통해 복잡한 motion control 과 identity preservation 사이의 trade-off 를 효과적으로 해결했습니다. 특히, LIRM 과 LIReFL 을 통한 latent identity reward feedback learning 은 motion-aware identity preservation 을 강화하여 human preferences 에 부합하는 결과를 도출했습니다.
이 연구는 multi-subject 환경에서 high-quality, customizable videos 를 정밀하게 제어하는 능력에 대한 새로운 기준을 제시하며, controllable video generation 분야에 큰 영향을 미칠 것입니다. 또한, DreamOmni Bench 라는 포괄적인 벤치마크를 구축하여 향후 연구의 평가 프로토콜을 표준화하고, I2V generation 과 같은 새로운 emergent capabilities 를 입증함으로써 실제 응용 분야에서의 활용 가능성을 크게 확장했습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization
- [논문리뷰] VGGRPO: Towards World-Consistent Video Generation with 4D Latent Reward
- [논문리뷰] Learning Smooth Time-Varying Linear Policies with an Action Jacobian Penalty
- [논문리뷰] Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation
- [논문리뷰] ToonComposer: Streamlining Cartoon Production with Generative Post-Keyframing
Review 의 다른글
- 이전글 [논문리뷰] DVD: Deterministic Video Depth Estimation with Generative Priors
- 현재글 : [논문리뷰] DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
- 다음글 [논문리뷰] EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
댓글