[논문리뷰] EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
링크: 논문 PDF로 바로 열기
저자: Tianwei Xiong, Jun Hao Liew, Zilong Huang, Zhijie Lin, Jiashi Feng, Xihui Liu
키워: Video Tokenization, Autoregressive Generation, Adaptive Length, Quality-Cost Trade-off, Router, Proxy Reward, VideoMAE
1. Key Terms & Definitions
- Autoregressive (AR) Generation : 이전에 생성된 토큰들을 조건으로 삼아 다음 토큰을 순차적으로 생성하는 방식의 Generation Model. Visual Domain에서는 픽셀을 discrete visual token으로 변환하여 사용한다.
- Video Tokenizer : Raw Video 픽셀을 discrete token sequence로 압축하는 모델. AR Visual Generative Model의 입력으로 사용되며, Token Sequence Length가 Reconstruction Quality와 Computational Cost의 균형에 critical한 영향을 미친다.
- Adaptive Length Tokenization : Input Video의 Content Complexity에 따라 Token Sequence의 길이를 가변적으로 할당하는 Tokenization 방식. 기존의 Fixed-Length Tokenization의 비효율성을 개선한다.
- Proxy Reward : Token Assignment의 Quality-Cost Trade-off 성능을 정량화하기 위해 도입된 새로운 Metric. Reconstruction Quality와 Token Length Cost를 결합하여 최적의 Assignment를 식별하는 데 사용된다.
- Router : EVATok Framework의 핵심 구성 요소 중 하나로, Lightweight Model이며 Input Video에 대한 Optimal Token Assignment를 빠르게 예측하는 역할을 한다. Classification Task 형태로 학습된다.
2. Motivation & Problem Statement
AR Video Generative Model은 Video Tokenizer를 통해 픽셀을 discrete visual token sequence로 압축하며, 이 token sequence의 길이가 Reconstruction Quality와 Downstream Generation의 Computational Cost 간의 균형에 critical하다. 기존의 대부분 Video Tokenizer는 Input Content의 복잡도와 관계없이 Fixed-Length Sequence 를 생성하는데, 이는 단순하거나 반복적인 Video Segment에서는 Token을 낭비하고, Dynamic하거나 복잡한 Segment에서는 정보 표현이 부족하여 비효율적이다.
이러한 Fixed-Length Allocation의 비효율성 이 주요 문제이며, 특히 Causal Video Tokenizer를 사용하는 AR Video Generative Model에서 두드러진다. 기존의 Adaptive Video Tokenization 접근 방식들(예: Tail-Token-Dropping [3, 41], Threshold-Based Search [70], Integer Linear Programming (ILP) [33])은 휴리스틱(heuristic)하거나 Mini-batch 구성에 묶여 Global Quality-Cost Balance를 놓칠 수 있어 Suboptimal한 결과를 초래한다. 핵심 문제는 각 Video의 내재적 복잡도에 맞는 Optimal Token Assignment 를 결정하는 명확한 Estimation Approach나 Definition이 없었다는 점이다.
3. Method & Key Results
저자들은 Efficient Video Adaptive Tokenizer (EVATok) Framework를 제안하여 Video별 Optimal Token Assignment를 예측하고 Adaptive Tokenizer를 학습시킨다. EVATok은 4단계로 구성된다
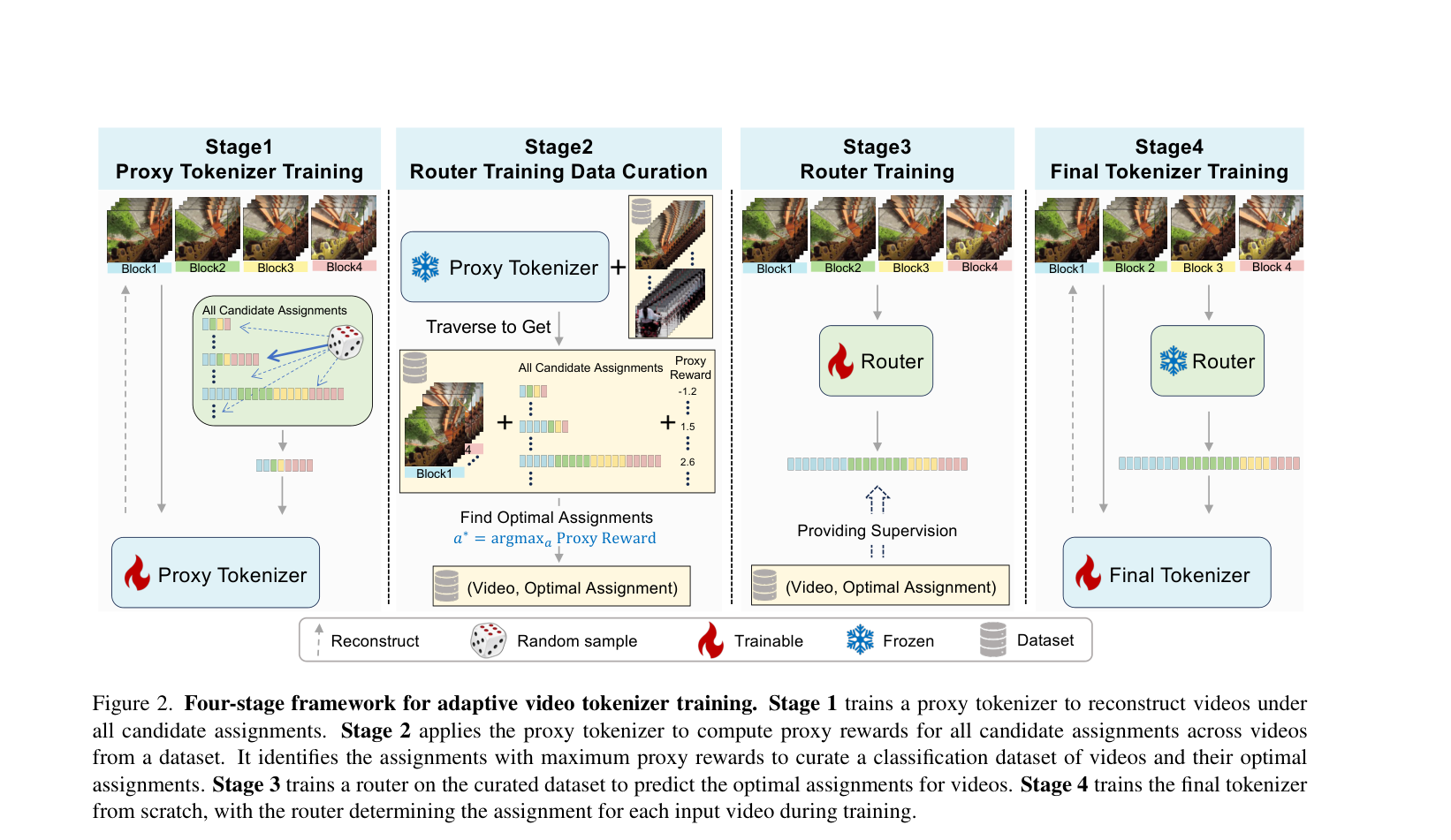 Figure 2: Four-stage framework for adaptive video tokenizer training. Stage 1 trains a proxy tokenizer to reconstruct videos under all candidate assignments. Stage 2 applies the proxy tokenizer to compute proxy rewards for all candidate assignments across videos from a dataset. It identifies the assignments with maximum proxy rewards to curate a classification dataset of videos and their optimal assignments. Stage 3 trains a router on the curated dataset to predict the optimal assignments for videos. Stage 4 trains the final tokenizer from scratch, with the router determining the assignment for each input video during training.
Figure 2: Four-stage framework for adaptive video tokenizer training. Stage 1 trains a proxy tokenizer to reconstruct videos under all candidate assignments. Stage 2 applies the proxy tokenizer to compute proxy rewards for all candidate assignments across videos from a dataset. It identifies the assignments with maximum proxy rewards to curate a classification dataset of videos and their optimal assignments. Stage 3 trains a router on the curated dataset to predict the optimal assignments for videos. Stage 4 trains the final tokenizer from scratch, with the router determining the assignment for each input video during training.
:
- Stage 1: Proxy Tokenizer Training : Randomly Sample된 Token Assignment에 따라 Video를 재구성하는 Proxy Tokenizer를 학습시킨다. 이 Proxy Tokenizer는 추후 Proxy Reward 를 계산하는 데 사용된다.
- Stage 2: Dataset Curation for Router Training : Proxy Tokenizer를 사용하여 모든 Candidate Assignment에 대한 Proxy Reward 를 계산하고, 각 Video에 대해 Proxy Reward 를 최대화하는 Optimal Assignment(a*)를 식별한다. 이를 통해 (Video, Optimal Assignment) Pair로 구성된 Dataset을 구축한다. Proxy Reward 는 Reconstruction Quality (Normalized LPIPS )와 Token Length Cost (Normalized Length)를 Weighted Sum하여 계산된다.
- Stage 3: Router Training : Stage 2에서 구축한 Dataset을 사용하여 Lightweight Router (ViT-like Architecture)를 학습시킨다. 이 Router 는 Input Video에 대한 Optimal Assignment를 Classification Task 형태로 빠르게 예측한다.
- Stage 4: Final Adaptive Video Tokenizer Training : Router 가 예측한 Optimal Assignment를 기반으로 Final Adaptive Video Tokenizer를 처음부터 학습시킨다. 이 단계에서는 VideoMAE Semantic Encoder [2, 53]를 Discriminator로 활용하고 Video Representation Alignment를 통합하여 Reconstruction Quality를 향상시킨다.
핵심 결과:
- Efficiency 및 Overall Quality 향상 : EVATok은 Downstream AR Generation 및 Video Reconstruction에서 Token Usage를 크게 절감하면서도 뛰어난 성능을 달성한다 [Figure 1].
- Token Length Saving : 기존 LARP [59] 및 Fixed-Length Baseline 대비 평균 Token Usage를 최소 24.4% 절감하면서도 더 나은 Quality를 보여준다. 구체적으로 UCF-101 Reconstruction에서 24.4% 의 Token 절감 (1024 Token → 774 Token)과 함께 LARP ( 20 rFVD)보다 우수한 9.7 rFVD 를 달성했다
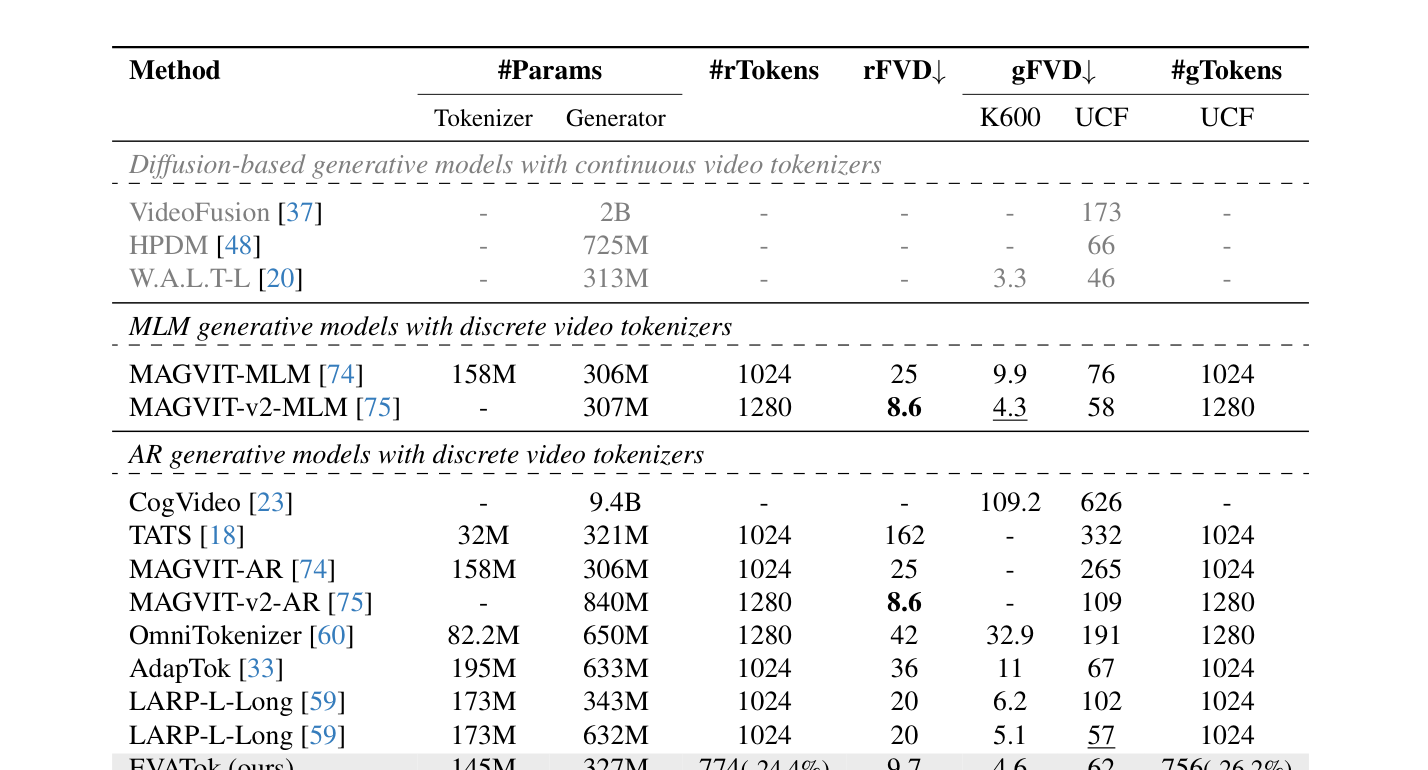 Table 3: System-level comparison for tokenizers and downstream generation models. EVATok achieves superior performances in UCF-101 video reconstruction, downstream class-to-video generation and K600 frame prediction, while saving 24.4% tokens in reconstruction and 26.2% tokens in UCF class-to-video generation.
Table 3: System-level comparison for tokenizers and downstream generation models. EVATok achieves superior performances in UCF-101 video reconstruction, downstream class-to-video generation and K600 frame prediction, while saving 24.4% tokens in reconstruction and 26.2% tokens in UCF class-to-video generation.
.
- State-of-the-Art AR Generation : UCF-101 Class-to-Video Generation에서 LARP 대비 26.2% Token 절감 (1024 Token → 756 Token)과 함께 48 gFVD 를 기록하여 State-of-the-Art 성능을 달성했다 [Table 3].
- Router의 효과 : Router 기반의 Assignment Strategy는 Max-Proxy-Reward Strategy와 매우 유사한 Quality-Cost Trade-off Curve를 보여주며
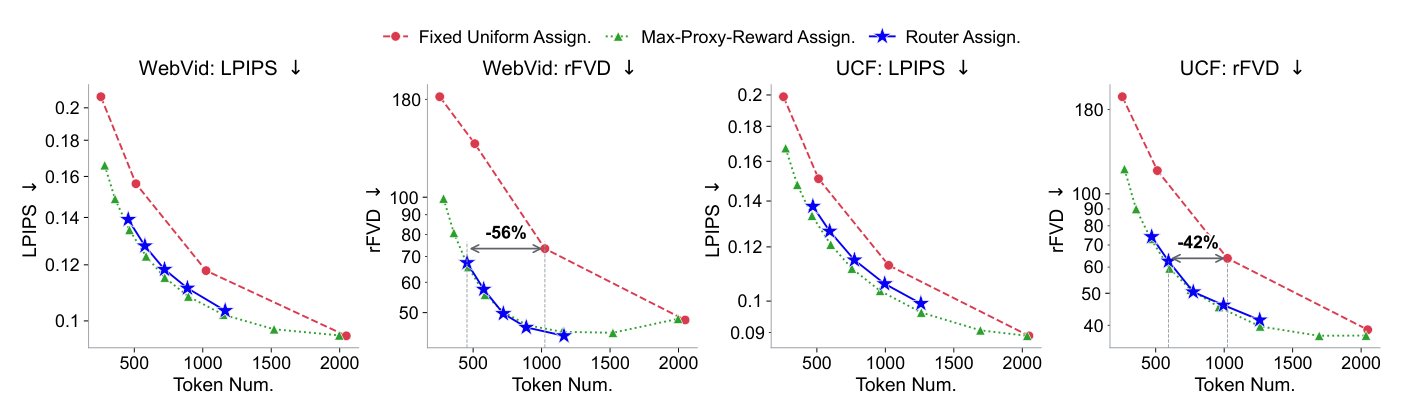 Figure 4: Quality-cost trade-off curves for different assignment strategies. By adaptively assigning token budgets to different temporal blocks across various videos, our max-proxy-reward strategy (green series) achieves superior performance under various overall budgets compared to the typical fixed uniform token assignment approach (red series). The router-based assignment (blue series) delivers performance close to that of the max-proxy-reward strategy on both WebVid and UCF datasets (the latter unseen during router training).
Figure 4: Quality-cost trade-off curves for different assignment strategies. By adaptively assigning token budgets to different temporal blocks across various videos, our max-proxy-reward strategy (green series) achieves superior performance under various overall budgets compared to the typical fixed uniform token assignment approach (red series). The router-based assignment (blue series) delivers performance close to that of the max-proxy-reward strategy on both WebVid and UCF datasets (the latter unseen during router training).
, WebVid 에서 56% , UCF 에서 42% 의 Token Saving을 달성했다.
- VideoMAE Discriminator의 기여 : VideoMAE Discriminator 통합은 PSNR/LPIPS 수치 저하에도 불구하고 rFVD 및 Downstream gFVD 를 크게 향상시키며, Perceptual Quality 측면에서 blurriness 및 artifact를 완화하는 효과가 있음을 Qualitative Analysis를 통해 입증했다 [Table 5], [Figure 8].
4. Conclusion & Impact
EVATok은 Content-Adaptive Video Tokenization의 핵심 과제인 Optimal Assignment 식별 문제를 해결하기 위한 Four-Stage Framework 를 성공적으로 제안했다. 특히, Proxy Reward 라는 새로운 Metric을 도입하여 Quality-Cost Trade-off를 최적화하는 Assignment를 정의하고, Lightweight Router 를 통해 이를 효율적으로 예측하도록 함으로써 기존 방식의 한계를 극복했다.
이 연구는 State-of-the-Art 성능을 달성하면서도 Video Reconstruction 및 Downstream AR Generation에서 상당한 Token Length Saving (최소 24.4%) 을 실현하여 효율성과 Quality를 동시에 향상시켰다. EVATok은 Content-Adaptive Video Tokenization의 잠재력을 입증했으며, 이는 향후 더 긴 Duration과 고해상도 Video를 처리하는 AR Generative Model의 효율성을 크게 높이는 데 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
- 현재글 : [논문리뷰] EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
- 다음글 [논문리뷰] EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models
댓글