[논문리뷰] EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models
링크: 논문 PDF로 바로 열기
저자: Xuanlang Dai, Yujie Zhou, et al.
키워: Chain-of-Thought, Diffusion Models, MLLMs, Latent Reasoning, Iterative Refinement, Spatial Grounding, Flow Matching
1. Key Terms & Definitions (핵심 용어 및 정의)
- Endogenous Chain-of-Thought (EndoCoT) : 확산 모델 내에서 자체적으로 Chain-of-Thought reasoning 을 수행하도록 하는 프레임워크로, 잠재 사고 상태를 반복적으로 정제하고 시각적 출력과 텍스트 감독을 연결합니다.
- Multimodal Large Language Models (MLLMs) : 텍스트 인코더로 확산 프레임워크에 통합되어 복잡한 공간 추론과 같은 태스크를 처리하는 데 사용되지만, 기존 방식에서는 추론 깊이에 한계가 있습니다.
- Diffusion Transformers (DiTs) : 확산 모델의 핵심 생성 컴포넌트로, EndoCoT 프레임워크 내에서 MLLMs 의 추론 가이드를 점진적으로 실행하여 복잡한 태스크를 단계별로 해결합니다.
- Iterative Thought Guidance : EndoCoT 의 핵심 모듈 중 하나로, MLLMs 의 잠재 사고 상태를 반복적으로 업데이트하여 진정한 CoT-like reasoning process 를 생성하고, 이 상태들을 DiT 의 디노이징 프로세스와 연결합니다.
- Terminal Thought Grounding : EndoCoT 의 또 다른 핵심 모듈로, MLLM 의 최종 추론 상태를 ground-truth answers 와 정렬하여 추론 궤적이 텍스트 감독에 기반을 두고 터미널 출력에서 cumulative drift 를 방지하도록 합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 MLLMs 가 확산 프레임워크에 텍스트 인코더로 널리 통합되어 공간 추론과 같은 복잡한 태스크를 해결하고 있지만, 이 패러다임에는 두 가지 주요 한계가 있습니다. 첫째, MLLMs text encoder 는 불충분한 추론 깊이를 보입니다. 단일 스텝 인코딩으로는 복잡한 태스크에 대한 정확한 가이드를 제공하는 데 필수적인 Chain-of-Thought process 를 활성화하지 못합니다. 둘째, 디코딩 프로세스 동안 가이드가 불변(invariant)하게 유지됩니다. 이는 DiT 가 복잡한 지침을 실행 가능한 디노이징 스텝으로 점진적으로 분해하는 것을 방해합니다. 기존 연구인 DiffThinker [11]와 같은 명시적인 시도는 diffusion models 에 추론을 '주입'하려 했지만, 피상적인 정렬로 인해 novel domains 에 일반화될 때 치명적으로 실패하는 fragile solutions 을 생성합니다 [Figure 1(b)]. 이러한 한계는 모델이 생성 과정에서 실제 추론을 수행하기보다는 초기 디노이징 스텝 내에서 최종 솔루션에 고정되어 시각적 품질만을 refine한다는 것을 시사하며 [Figure 1(c)], robust, iterative problem-solving 을 위한 endogenous mechanism 이 부재함을 드러냅니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 한계를 극복하기 위해 Endogenous Chain-of-Thought (EndoCoT) 프레임워크를 제안합니다. EndoCoT 는 Iterative Thought Guidance 와 Terminal Thought Grounding 의 두 가지 주요 컴포넌트로 구성됩니다
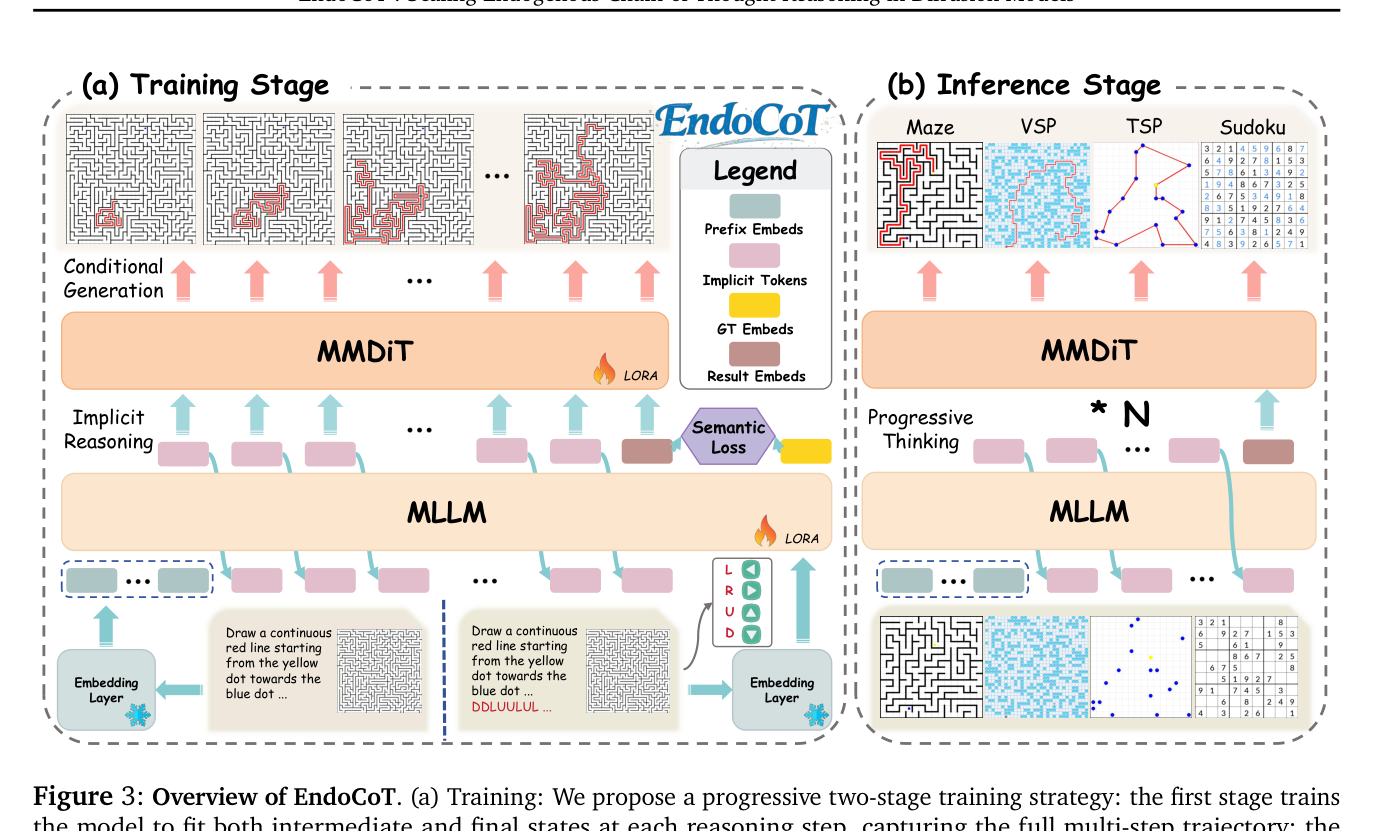 Figure 3: Overview of EndoCoT.
Figure 3: Overview of EndoCoT.
. Iterative Thought Guidance 는 MLLM 내에서 잠재 사고 상태를 반복적으로 정제하여 진정한 CoT-like reasoning process 를 만들고, 이 상태들을 DiT 의 디노이징 프로세스와 연결합니다. 이와 동시에, Terminal Thought Grounding 모듈은 MLLM 의 최종 추론 상태를 ground-truth answers 와 정렬하여 추론 궤적이 텍스트 감독에 확고히 뿌리내리도록 합니다. 모델 학습을 위해, 저자들은 progressive two-stage training strategy 를 채택했습니다. Stage 1 (Reasoning Development) 에서는 모든 중간 추론 스텝에 걸쳐 감독을 제공하여 모델이 단계별 시각적 추론을 학습하게 하고, Stage 2 (Terminal Consolidation) 에서는 중간 상태에 대한 그래디언트를 동결하고 최종 출력 품질을 정제합니다.
광범위한 실험 결과, EndoCoT 는 Maze, TSP, Visual Spatial Planning (VSP), Sudoku 등 다양한 추론 태스크 벤치마크에서 강력한 성능을 입증했습니다 [Figure 1(a), Table 1]. 특히, EndoCoT 는 모든 벤치마크에서 baseline을 능가하며 평균 정확도 92.1% 를 달성했고, 이는 가장 강력한 baseline보다 8.3% 포인트 높은 수치입니다. 태스크 복잡성이 증가함에 따라 EndoCoT 는 탁월한 정확도를 유지하여, Maze-32에서 90% , Sudoku-35에서 95% 의 정확도를 달성하며 가장 강력한 baseline인 DiffThinker 를 각각 25% 및 40% 능가했습니다
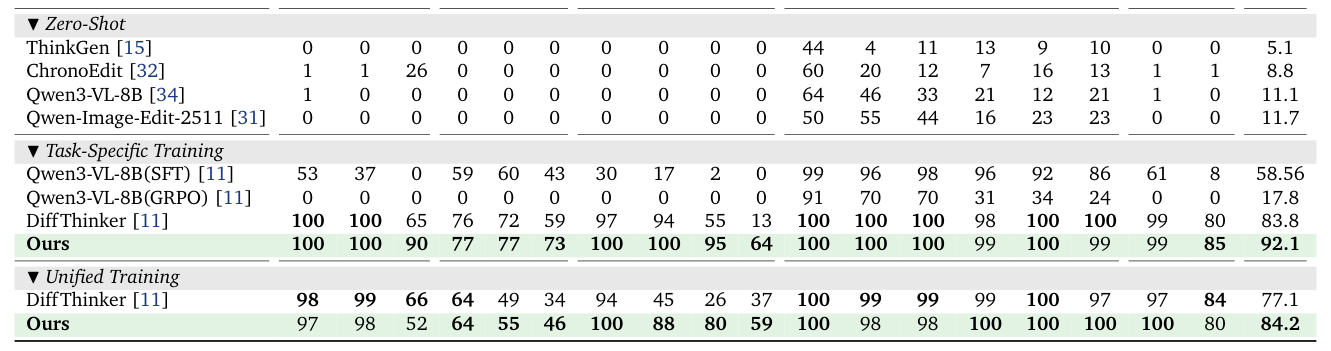 Table 1: Evaluation results across visual reasoning tasks.
Table 1: Evaluation results across visual reasoning tasks.
. 또한, semantic loss 의 효과에 대한 ablation study 결과, 이 손실을 제거하면 Maze-32 벤치마크에서 정확도가 90% 에서 14% 로, path repetition rate 가 98.13% 에서 67.24% 로 크게 하락하여 semantic loss 가 long-horizon reasoning 에 필수적인 역할을 함을 확인했습니다 [Table 2]. Inference-Time CoT Scaling 분석에서는 암묵적 추론 예산(τ)을 동적으로 증가시킴에 따라 정확도와 path repetition rate 가 꾸준히 향상됨을 보여주며, 특히 도전적인 Maze-32 벤치마크에서 두드러집니다 [Table 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 EndoCoT 라는 새로운 프레임워크를 통해 diffusion models 가 endogenous Chain-of-Thought reasoning 을 수행할 수 있도록 합니다. 이 프레임워크는 잠재 사고 상태를 반복적으로 정제하고 최종 출력을 텍스트 감독에 grounding 함으로써, high-level logical planning 과 precise visual generation 사이의 간극을 성공적으로 메웠습니다. 이 능력은 multimodal text encoder 와 DiT backbone 의 시너지적 결합에서 비롯되며, 이는 표준 디노이징 프로세스만으로는 얻기 어렵습니다. EndoCoT 는 복잡한 시각적 추론 태스크에서 높은 정확도와 견고성을 제공하여, diffusion models 의 추론 능력을 크게 확장시켰습니다. 이러한 연구는 diffusion models 의 generative capabilities 를 단순한 이미지 생성에서 더욱 복잡한 문제 해결 및 지능형 추론 시스템으로 발전시키는 중요한 이정표가 될 것입니다. 현재는 최적의 추론 스텝 수에 대한 수동 튜닝과 명시적인 중간 감독을 포함하는 고품질 데이터셋에 의존하지만, 향후 연구는 적응형 메커니즘을 개발하고 프레임워크를 보다 일반적인 태스크로 확장하는 데 집중될 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Understanding the Behaviors of Environment-aware Information Retrieval
- [논문리뷰] Thinking with Visual Grounding
- [논문리뷰] Taylor-Calibrate: Principled Initialization for Hybrid Linear Attention Distillation
- [논문리뷰] Selective Synergistic Learning for Video Object-Centric Learning
Review 의 다른글
- 이전글 [논문리뷰] EVATok: Adaptive Length Video Tokenization for Efficient Visual Autoregressive Generation
- 현재글 : [논문리뷰] EndoCoT: Scaling Endogenous Chain-of-Thought Reasoning in Diffusion Models
- 다음글 [논문리뷰] Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
댓글