[논문리뷰] DVD: Deterministic Video Depth Estimation with Generative Priors
링크: 논문 PDF로 바로 열기
저자: Hongfei Zhang, Harold Haodong Chen, Chenfei Liao, Jing He, Zixin Zhang, Haodong Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- DVD (Deterministic Video Depth Estimation with Generative Priors) : 기존 비디오 Diffusion 모델의 강력한 Generative Priors를 활용하여 Single-Pass Depth Regressor로 Deterministic Depth Estimation을 수행하는 새로운 Framework.
- Timestep as Structural Anchor : Diffusion 모델의 Timestep
t를 Low-frequency Geometric Stability와 High-frequency Spatial Details 사이의 균형을 맞추는 Structural Anchor ( τ₀ )로 Repurpose한 개념. - Latent Manifold Rectification (LMR) : Deterministic Regression에서 발생하는 "Mean Collapse" 현상을 완화하기 위해 Latent Differential을 Align하는 Parameter-free Supervision 메커니즘으로, Sharp Boundary와 Coherent Motion을 복원.
- Global Affine Coherence : DVD Backbone에 내재된 특성으로, Inter-window Divergence를 Affine Transform으로 Bound하여 Long-duration Video에 대한 Seamless Sliding-window Inference를 가능하게 함.
- Geometric Hallucination : Generative 모델에서 시각적 Plausibility를 Geometric Accuracy보다 우선시하여 발생하는, 시간적으로 Consistent하지 않거나 부정확한 Geometric Structure 생성 문제.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 비디오 Depth Estimation 방법론은 근본적인 Trade-off에 직면해 있습니다. Diffusion-based generative models (예: DepthCrafter )는 풍부한 Spatio-temporal Prior를 제공하지만, Stochastic Sampling 으로 인해 Geometric Hallucination 과 Scale Drift 문제를 겪으며 Real-world Application에서의 Stability와 Reliability가 제한됩니다. 반면, Discriminative ViT-based models (예: VDA )는 효율적이고 Deterministic한 Output을 제공하지만, 방대한 Labeled Dataset에 크게 의존하여 Semantic Ambiguity (예: Motion Blur 또는 Textureless Region을 Structural Boundary로 오인)를 해결해야 합니다. 이러한 한계점들은 확장성 및 재현성에 상당한 장벽을 초래하며, 데이터 부족 시나리오에서의 적응력을 제한합니다. 이러한 문제들은 `
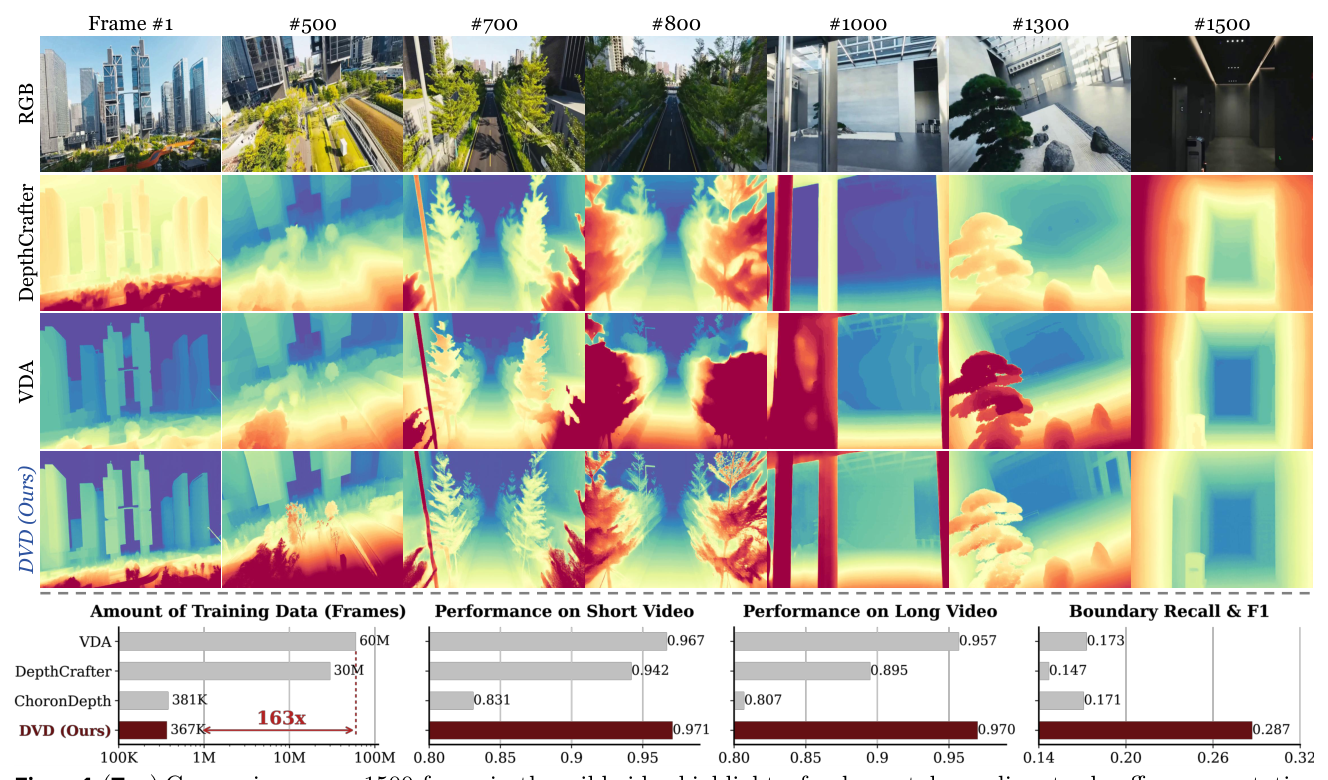 Figure 1: (Top) Comparisons on a 1500-frame in-the-wild video highlight a fundamental paradigm trade-off: representative generative models (e.g., DepthCrafter (Hu et al., 2025)) suffer from geometric hallucination, while leading discriminative baselines (e.g., VDA (Chen et al., 2025d)) face semantic ambiguity. DVD resolves this dilemma, delivering consistent, high-fidelity geometry. (Bottom) DVD achieves superior performance on both short and long videos (averaged on KITTI (Geiger et al., 2012), ScanNet (Dai et al., 2017), and Bonn (Palazzolo et al., 2019)), while successfully unlocking the rich priors implicit in video foundation models using remarkably minimal task-specific data, e.g., less than 1% of VDA's training set.
Figure 1: (Top) Comparisons on a 1500-frame in-the-wild video highlight a fundamental paradigm trade-off: representative generative models (e.g., DepthCrafter (Hu et al., 2025)) suffer from geometric hallucination, while leading discriminative baselines (e.g., VDA (Chen et al., 2025d)) face semantic ambiguity. DVD resolves this dilemma, delivering consistent, high-fidelity geometry. (Bottom) DVD achieves superior performance on both short and long videos (averaged on KITTI (Geiger et al., 2012), ScanNet (Dai et al., 2017), and Bonn (Palazzolo et al., 2019)), while successfully unlocking the rich priors implicit in video foundation models using remarkably minimal task-specific data, e.g., less than 1% of VDA's training set.
` (Top)에서 시각적으로 잘 나타납니다. 본 연구는 Generative 접근 방식의 풍부한 Spatio-temporal Prior와 Discriminative 모델의 Structural Stability를 효과적으로 균형 잡으면서 효율적이고 확장 가능한 비디오 Depth Estimation Framework를 설계하는 것을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 비디오 Depth Estimation의 Trade-off를 해결하기 위해 DVD 를 제안합니다. DVD 는 Pre-trained Video Diffusion Model을 Single-Pass Depth Regressor로 Deterministic하게 Adapting하는 최초의 Framework입니다. 제안 방법론은 세 가지 핵심 Design을 통해 기존의 Bottleneck을 해결합니다. 첫째, Diffusion Timestep t를 Structural Anchor ( τ₀ )로 Repurpose하여 Low-frequency Global Structure Stability와 High-frequency Spatial Detail 사이의 균형을 효과적으로 맞춥니다. τ₀ = 0.5 가 최적의 균형을 제공함을 [Figure 10]에서 입증했습니다. 둘째, Deterministic Regression에서 발생하는 Spatio-temporal "Mean Collapse"를 방지하기 위해 Latent Manifold Rectification ( LMR )을 도입합니다. LMR 은 Latent Gradient ( Lsp )와 Temporal Latent Flow ( Ltemp )를 Alignment하는 Parameter-free Supervision을 통해 Sharp Boundary와 Coherent Motion을 복원합니다 ([Figure 5], [Figure 11] Left). 셋째, 모델의 Inherent Property인 Global Affine Coherence를 활용하여, Overlapping Window 간의 Discrepancy를 Affine Transformation으로 Linear하게 정렬함으로써 Long-duration Video에 대한 Seamless Sliding-window Inference를 가능하게 합니다 (`
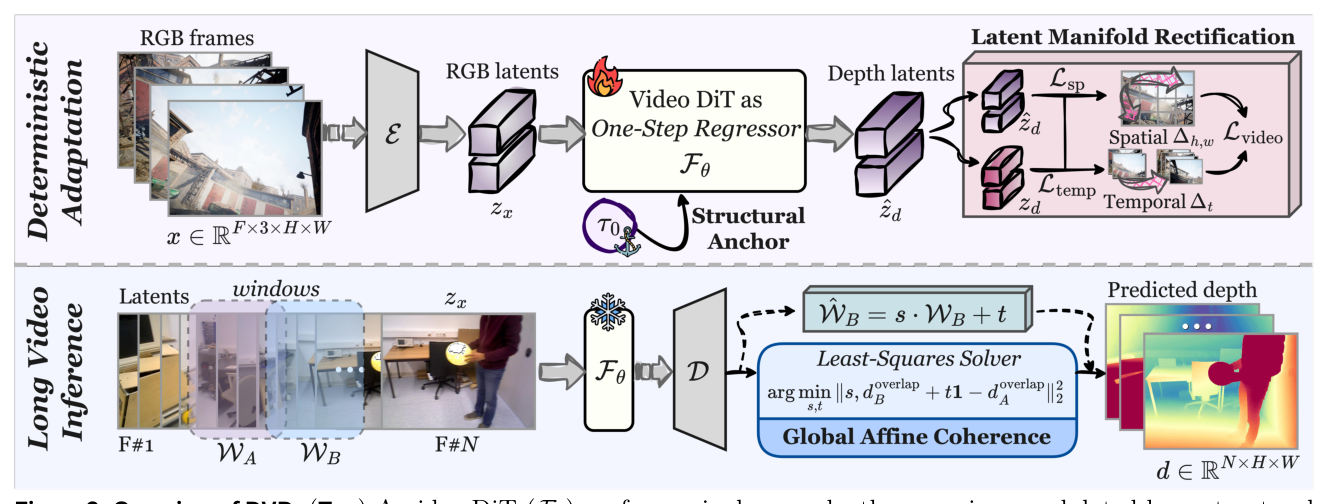 Figure 2: Overview of DVD. (Top) A video DiT (Fe) performs single-pass depth regression, modulated by a structural anchor (70). Latent manifold rectification (LMR) mitigates mean collapse via differential constraints. (Bottom) For long video depth estimation, overlapping windows (WA, WB) are seamlessly aligned using a closed-form least-squares solver, leveraging the model's global affine coherence.
Figure 2: Overview of DVD. (Top) A video DiT (Fe) performs single-pass depth regression, modulated by a structural anchor (70). Latent manifold rectification (LMR) mitigates mean collapse via differential constraints. (Bottom) For long video depth estimation, overlapping windows (WA, WB) are seamlessly aligned using a closed-form least-squares solver, leveraging the model's global affine coherence.
, [Figure 6]`).
DVD 는 Image-Video Joint Training Strategy 를 사용하여 Spatial Quality와 Temporal Consistency를 동시에 유지합니다. 실험 결과, DVD 는 Zero-shot Performance에서 State-of-the-Art를 달성했습니다. Short Video Depth Estimation에서 ScanNet 벤치마크 기준 AbsRel 5.5 (State-of-the-Art) 및 δ₁ 0.974 를 기록하여, VDA ( AbsRel 5.8 , δ₁ 0.968 ) 및 DepthCrafter ( AbsRel 7.1 , δ₁ 0.960 )를 능가합니다 (`
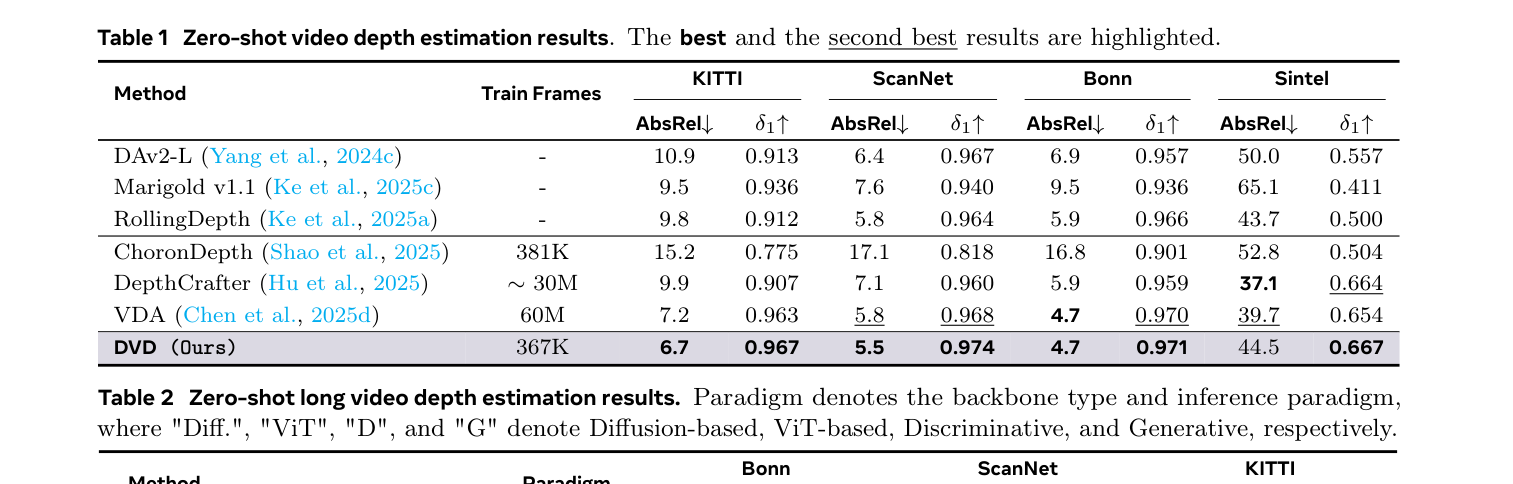 Table 1: Zero-shot video depth estimation results. The best and the second best results are highlighted.
Table 1: Zero-shot video depth estimation results. The best and the second best results are highlighted.
). Long Video 시나리오에서도 **Bonn** 벤치마크 기준 **AbsRel 5.3** 및 **δ₁ 0.978** 를 달성하며 **DepthCrafter** ( **AbsRel 8.5** , **δ₁ 0.962** ) 대비 현저히 우수한 성능을 보였습니다 ([Table 2]). 특히, **DVD** 는 선행 Baseline 대비 **163배 적은** Task-specific Training Data ( **367K 프레임** vs. **VDA 60M 프레임** )를 사용하면서도 성능 우위를 확보하여 Compelling Data Efficiency를 입증했습니다 ([Figure 1]Bottom,[Figure 8] Left). Inference Speed 또한 Discriminative 모델과 유사한 수준을 유지하며 실용적인 가치를 보여주었습니다 ([Figure 8]` Middle).
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Pre-trained Video Diffusion 모델을 Single-Pass Depth Estimation을 위한 Deterministic Regressor로 성공적으로 변환하는 Framework인 DVD 를 제안합니다. DVD 는 Stochastic Sampling을 우회함으로써 Generative 모델의 Geometric Hallucination 문제와 Discriminative 모델의 Semantic Ambiguity 문제를 동시에 해결합니다. Timestep-driven Structural Anchor, Latent Manifold Rectification (LMR), 그리고 Global Affine Coherence라는 세 가지 핵심 Design을 통해, DVD 는 Generative 모델의 Semantic Richness와 Discriminative 모델의 Structural Stability를 결합하여 Robust한 Zero-shot Solution을 제공합니다. 이 Framework는 State-of-the-Art Geometric Fidelity와 Temporal Coherence를 달성하면서도 선행 Baseline 대비 163배 적은 Task-specific Training Data를 사용하여 탁월한 Data Efficiency와 Scalability를 보여줍니다. DVD 는 Dynamic 3D Scene Understanding 을 위한 Highly Efficient하고 Scalable한 Paradigm을 제시하며, 미래 3D Perception 시스템 개발에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
- [논문리뷰] GenRecon: Bridging Generative Priors for Multi-View 3D Scene Reconstruction
- [논문리뷰] Enhancing Train-Free Infinite-Frame Generation for Consistent Long Videos
- [논문리뷰] DreamWorld: Unified World Modeling in Video Generation
- [논문리뷰] NOVA: Sparse Control, Dense Synthesis for Pair-Free Video Editing
Review 의 다른글
- 이전글 [논문리뷰] DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
- 현재글 : [논문리뷰] DVD: Deterministic Video Depth Estimation with Generative Priors
- 다음글 [논문리뷰] DreamVideo-Omni: Omni-Motion Controlled Multi-Subject Video Customization with Latent Identity Reinforcement Learning
댓글