[논문리뷰] DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
링크: 논문 PDF로 바로 열기
저자: Aili Chen, Chi Zhang, Junteng Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Agentic Task Synthesis : LLM(Large Language Model)이 범용 도구를 활용하여 복잡한 작업을 수행할 수 있도록 훈련 데이터를 자동으로 생성하는 과정입니다.
- Diversity Scaling : 합성된 작업(synthesized tasks)의 다양성을 체계적으로 늘리는 전략으로, 도구 풀(tool-pool) 범위, 도구 세트(toolset) 다양성, 이질적인 도구 사용 패턴을 포함합니다.
- Grounded Validity : 합성된 작업이 실제 도구 실행을 통해 검증 가능하고(verifiable) 실행 가능(executable)한 상태를 유지하는 것을 의미합니다.
- SFT (Supervised Fine-tuning) : 에이전트가 신뢰할 수 있는 도구 호출 능력을 습득하기 위한 초기 훈련 단계입니다.
- RL (Reinforcement Learning) : SFT 이후 에이전트의 견고성(robustness)과 다양한 도구 세트에서의 일반화(generalization) 능력을 향상시키기 위한 훈련 단계입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 LLM 기반 에이전트의 도구 사용 능력 향상을 위한 Agentic Task Synthesis 연구가 활발합니다. 그러나 기존 접근 방식은 합성된 작업의 Insufficient Diversity 로 인해 작업 및 도구 세트 변화에 대한 Robust Generalization 능력이 부족하다는 한계를 가집니다. 이는 모델이 고정된 루틴에 과도하게 의존하게 하여 새로운 작업 유형이나 도구 세트에서 Poor Generalization 을 유발합니다. 기존 방법론은 데이터 양이나 난이도 스케일링에 주로 초점을 맞추어 왔으며, 특정 도구 세트(예: 웹 검색 도구를 갖춘 Deep-Research 작업)에 국한되어 왔습니다. `
 Figure 1: Motivation and overview of DIVE. Top: Fixed-toolset synthesis and pipeline pooling limit diversity and weaken generalization. Middle: Simulated tools and query-first synthesis for diverse tasks increase unverifiability/unsolvability risk, limiting agentic training. Bottom: DIVE performs evidence-first synthesis on diverse, real-world tools, producing verifiable and executable tasks. Radar: Gray: base model; Blue: trained on deep-research data synthesized with a fixed search/browse toolset (strong in-distribution but weak/negative transfer); Purple: trained on DIVE with matched data and training budget (robust generalization).
Figure 1: Motivation and overview of DIVE. Top: Fixed-toolset synthesis and pipeline pooling limit diversity and weaken generalization. Middle: Simulated tools and query-first synthesis for diverse tasks increase unverifiability/unsolvability risk, limiting agentic training. Bottom: DIVE performs evidence-first synthesis on diverse, real-world tools, producing verifiable and executable tasks. Radar: Gray: base model; Blue: trained on deep-research data synthesized with a fixed search/browse toolset (strong in-distribution but weak/negative transfer); Purple: trained on DIVE with matched data and training budget (robust generalization).
`은 이러한 기존 방식의 한계를 명확히 보여줍니다. 또한, 다양성을 확장하면서도 Grounded Validity (검증 가능성 및 실행 가능성)를 유지하는 것이 어려워, 시뮬레이션된 도구의 신뢰성 문제나 Query-First Synthesis의 경우 까다로운 품질 검증 문제가 발생합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 에이전트의 Generalization 을 향상시키기 위해, 합성 순서를 역전시켜 Diverse, Real-world Tools 를 먼저 실행하고 그 결과로 얻은 트레이스(traces)로부터 작업을 역으로 도출하는 DIVE (Diversity in Agentic Task Synthesis for Generalizable Tool Use) 를 제안합니다. 이 "Evidence-First" 접근 방식은 Grounding by Construction 을 보장하여 모든 합성 작업이 실행 가능하고 검증 가능하도록 만듭니다. `
 Figure 2: Overview of the DIVE framework. (1) Diverse Synthesis Resource Preparation (Left): We construct decoupled pools of tools (spanning general and expert domains), seed concepts, and query-only exemplars with implicit tool-use patterns. (2) Evidence-Driven Task Synthesis (Right): We randomly sample configurations and run an inverted loop where the model executes real tools to collect grounded evidence (a, b) and reverse-derives tasks (query-answer pairs) strictly entailed by traces (c, d), ensuring validity by construction. (3) Agentic Training (Bottom): The synthesized corpus supports effective SFT cold starts and RL using verifiable reference answers.
Figure 2: Overview of the DIVE framework. (1) Diverse Synthesis Resource Preparation (Left): We construct decoupled pools of tools (spanning general and expert domains), seed concepts, and query-only exemplars with implicit tool-use patterns. (2) Evidence-Driven Task Synthesis (Right): We randomly sample configurations and run an inverted loop where the model executes real tools to collect grounded evidence (a, b) and reverse-derives tasks (query-answer pairs) strictly entailed by traces (c, d), ensuring validity by construction. (3) Agentic Training (Bottom): The synthesized corpus supports effective SFT cold starts and RL using verifiable reference answers.
`는 DIVE 프레임워크의 전체적인 구조를 보여줍니다.
DIVE는 다음 세 가지 단계를 포함합니다:
- Diverse Synthesis Resource Preparation : 373개의 도구를 포함하는 광범위한 Tool Pool (General 및 Expert 도메인), Long-tail Semantic Coverage를 제공하는 Seed Pool , 이질적인 구조적 사전 정보(Structural Priors)를 담는 Exemplar Pool 을 구축합니다.
- Evidence-Driven Task Synthesis : 무작위로 샘플링된 합성 구성(Toolset, Seed, Exemplars)을 기반으로 Evidence Collector 에이전트가 실제 도구를 실행하여 Grounded Evidence (도구 실행 트레이스 및 출력)를 수집합니다. 이후 Task Generator LLM 이 수집된 Evidence와 Exemplar에 기반하여 Query-Answer 쌍을 역으로 도출하며, K번의 Iterative Synthesis Loop를 통해 작업의 다양성을 점진적으로 증가시키고 Grounding 을 유지합니다.
- Agentic Training with DIVE Tasks : 합성된 DIVE 데이터셋으로 SFT (Cold Start) 및 RL (Robustness 및 Generalization 강화) 훈련을 수행합니다.
핵심 결과 :
- 일반화 성능 향상 : DIVE로 훈련된 Qwen3-8B 는 9개 OOD 벤치마크 전반에 걸쳐 평균 +22점 향상되었고, 가장 강력한 8B Baseline 대비 +68% 우수한 성능을 보였습니다. 특히 TOOLATHLON 벤치마크에서는 거의 0점 에서 8.3점 으로 크게 개선되었습니다. `
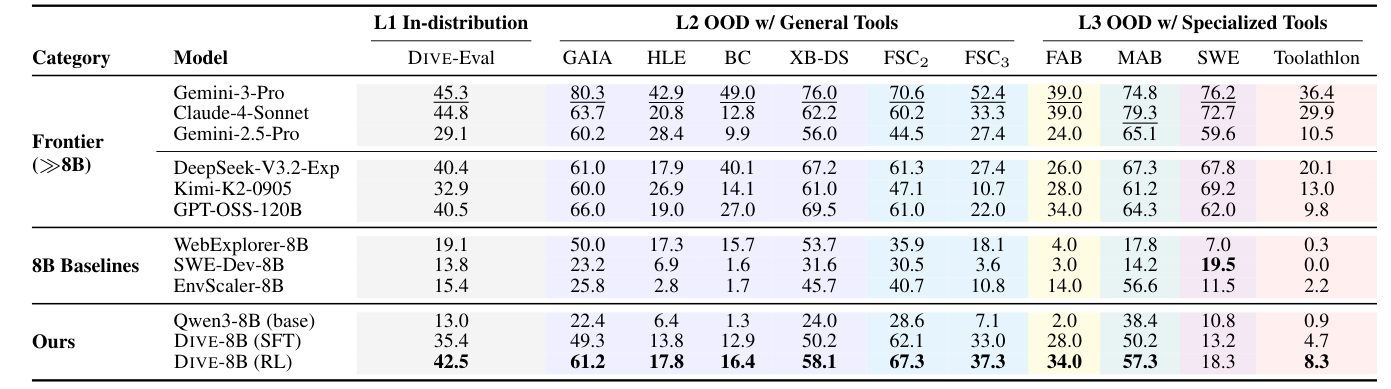 Table 2: Overall comparison across L1-L3 benchmarks. L1: in-distribution; L2: OOD w/ general tools; L3: OOD w/ specialized tools. BC=BrowseComp; XB-DS=Xbench-DeepSearch; FSC2/FSC3=FinSearchComp Global-T2/T3; FAB=Finance Agent Benchmark; MAB=MedAgentBench; SWE=SWE-bench Verified. 8B Baselines include specialized agentic models (WebExplorer-8B; our SWE-Dev-8B trained on SWE-Dev (Wang et al., 2025a)) and generalizable agentic models (EnvScaler-8B). Scores are success rates (%). Toolathlon is averaged over 3 runs; all other benchmarks are averaged over 4 runs. Underline: best overall; Bold: best among 8B backbone.
Table 2: Overall comparison across L1-L3 benchmarks. L1: in-distribution; L2: OOD w/ general tools; L3: OOD w/ specialized tools. BC=BrowseComp; XB-DS=Xbench-DeepSearch; FSC2/FSC3=FinSearchComp Global-T2/T3; FAB=Finance Agent Benchmark; MAB=MedAgentBench; SWE=SWE-bench Verified. 8B Baselines include specialized agentic models (WebExplorer-8B; our SWE-Dev-8B trained on SWE-Dev (Wang et al., 2025a)) and generalizable agentic models (EnvScaler-8B). Scores are success rates (%). Toolathlon is averaged over 3 runs; all other benchmarks are averaged over 4 runs. Underline: best overall; Bold: best among 8B backbone.
`에서 상세한 벤치마크 비교 결과를 확인할 수 있습니다.
- 다양성 스케일링의 우위 : Diversity Scaling 은 Quantity Scaling 보다 OOD 일반화에서 일관되고 강력한 이득을 제공했습니다. 4배 적은 데이터 (12k vs. 48k)로도 Diversity-only 방식이 Quantity-only 방식을 지속적으로 능가했습니다.
[Figure 3a]는 이러한 스케일링 분석을 보여줍니다. - RL의 다양성 증폭 효과 : RL 훈련 과정에서 정확도가 향상되는 동시에 Structural Diversity (Unique Tool-call Graphs, R/P Topologies)가 계속 증가했습니다. RL 은 SFT 단계에서 관찰된 다양성 스케일링 추세를 증폭시켜, 더 광범위한 효과적인 도구 사용 구조를 탐색하고 강화하는 데 기여합니다.
[Figure 3c]와[Figure 4]가 이를 시각화합니다. - 높은 구조적 다양성 : DIVE는 기존 Gen-DR 대비 186배 많은 Tool Coverage, 46k배 많은 Unique Toolsets, 20배 많은 Unique Tool-call Sequences, 135% 많은 R/P Topology Classes를 달성하여 높은 수준의 구조적 다양성을 입증했습니다.
[Table 3]에서 Gen-DR과의 상세한 다양성 비교를 확인할 수 있습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 DIVE 라는 Evidence-First 프레임워크를 통해 실세계의 다양한 도구 세트(toolsets)를 활용하는 LLM 에이전트 훈련 방법을 제시합니다. 합성 순서를 역전시킴으로써( Evidence-First, Tasks Derived from Traces ), Grounding된 Superivison 을 유지하면서도 Diversity Scaling 을 달성합니다. 실험 결과는 DIVE가 OOD Generalization 을 크게 개선하며, 특히 Tool-pool Diversity 가 데이터 양보다 더 중요함을 보여줍니다. 이러한 접근 방식은 LLM 에이전트의 Tool-use Generalization 을 획기적으로 향상시켜, 학계와 산업계 모두에서 더욱 Robust 하고 Reliable 한 에이전트 시스템 개발에 중요한 기반을 제공할 것입니다. 궁극적으로 DIVE는 광범위한 실제 시나리오에서 LLM 에이전트가 도구를 효과적으로 활용할 수 있도록 돕습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] AdaReasoner: Dynamic Tool Orchestration for Iterative Visual Reasoning
- [논문리뷰] LLM-in-Sandbox Elicits General Agentic Intelligence
- [논문리뷰] GUI Exploration Lab: Enhancing Screen Navigation in Agents via Multi-Turn Reinforcement Learning
- [논문리뷰] DeepEyesV2: Toward Agentic Multimodal Model
- [논문리뷰] Macaron-A2UI: A Model for Generative UI in Personal Agents
Review 의 다른글
- 이전글 [논문리뷰] Coarse-Guided Visual Generation via Weighted h-Transform Sampling
- 현재글 : [논문리뷰] DIVE: Scaling Diversity in Agentic Task Synthesis for Generalizable Tool Use
- 다음글 [논문리뷰] DVD: Deterministic Video Depth Estimation with Generative Priors
댓글