[논문리뷰] EVA: Efficient Reinforcement Learning for End-to-End Video Agent
링크: 논문 PDF로 바로 열기
저자: Xuanyu Zheng, Yepeng Tang, Jiahao Wang, Ruohui Wang, Yaolun Zhang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLM (Multimodal Large Language Model) : 텍스트뿐만 아니라 비디오와 같은 다양한 모달리티를 이해하고 추론할 수 있는 대규모 언어 모델을 지칭합니다. 본 논문에서는 비디오 이해 능력을 갖춘 모델을 의미합니다.
- Planning-before-Perception : 에이전트가 시각적 입력을 처리하기 전에 쿼리(query)만을 기반으로 어떤 비디오 부분을 언제, 어떻게 볼지 계획하는 패러다임입니다. 이는 기존의 "perception-first" 방식과 대비됩니다.
- Tool Use : MLLM 기반 에이전트가 비디오에서 특정 프레임을 추출하거나 해상도를 조절하는 등 외부 도구를 활용하여 비디오 정보에 능동적으로 접근하는 능력을 말합니다.
- SFT (Supervised Fine-Tuning) : 레이블링된 데이터셋을 사용하여 모델에 특정 작업 수행 능력을 가르치는 초기 학습 단계입니다. EVA에서는 비디오 에이전트의 핵심 기능(예: Tool-call 형식, 이미지-텍스트 추론)을 습득하는 데 사용됩니다.
- KTO (Kahneman-Tversky Optimization) : 성공 및 실패 전략 궤적으로 구성된 데이터셋을 사용하여 모델이 효과적인 전략을 선호하고 실패 모드를 피하도록 유도하는 최적화 기법입니다. GRPO 이전에 모델의 안정성을 향상시키는 데 기여합니다.
- GRPO (Generalized Reward Policy Optimization) : KL-정규화(KL-regularized) 정책 최적화 방법론으로, 높은 보상을 얻는 행동을 장려하면서 정책이 참조 모델(reference model)과 근접하게 유지되도록 합니다. 이를 통해 모델은 온라인으로 강화 학습(Reinforcement Learning)을 수행하며 정책을 개선합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 멀티모달 대규모 언어 모델(MLLM) 기반 비디오 이해 시스템은 비디오를 수동적인 인식기로 처리하여, 전체 비디오나 균일하게 샘플링된 프레임을 어떠한 적응적 추론 없이 처리하는 한계가 있습니다. 이는 특히 Long-form Video Understanding 에서 긴 토큰 시퀀스(long token sequences), 과도한 시간적 의존성, 그리고 중복된 프레임(redundant frames)으로 인해 비효율적이며, Sampling Dilemma 와 같은 문제로 이어집니다. 최근 에이전트 기반 방법들은 외부 도구를 도입했지만, 여전히 수동으로 설계된 워크플로우와 Perception-first 전략에 의존하여 장시간 비디오에서 비효율성을 야기합니다.
저자들은 MLLM 기반 에이전트가 Video Understanding 에서 자율적으로 "무엇을 볼지, 언제 볼지, 어떻게 볼지" 결정할 수 있도록 하는 근본적인 질문을 제기하며, 이러한 간극을 해결하고자 합니다. 기존 방식들은 고정된 샘플링 비율이나 제한된 제어 매개변수(parameter)로 인해 에이전트의 탐색 능력과 유연성이 부족하다는 점이 문제로 지적됩니다. 이에 저자들은 에이전트가 시각적 입력에 앞서 텍스트 쿼리(textual query)만을 통해 먼저 추론하여 시각적 토큰(visual tokens) 사용을 계획하는 Planning-before-Perception 패러다임을 제안합니다
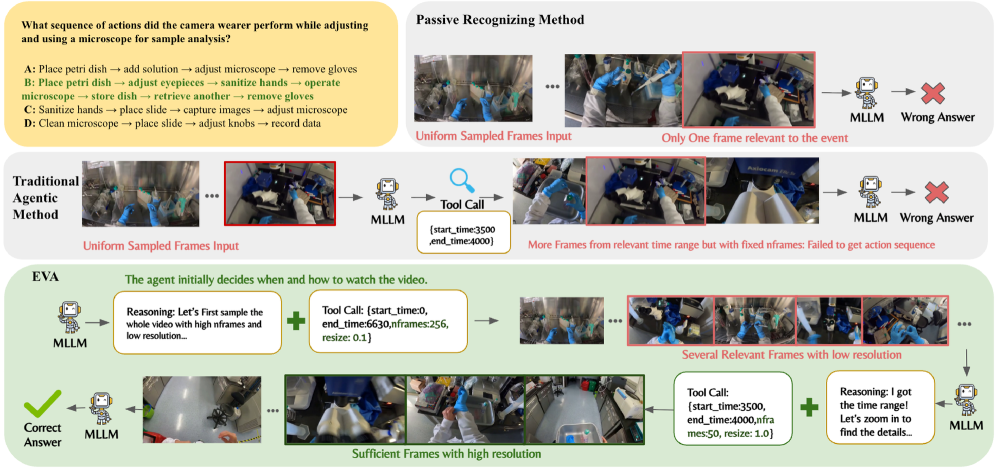
이 패러다임은 쿼리-주도(query-driven) 및 효율적인 비디오 이해를 가능하게 하여, 불필요한 연산을 피하고 정보가 풍부한 순간에 선택적으로 집중할 수 있도록 합니다 [Figure 1].
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Planning-before-Perception 패러다임을 구현하기 위해 EVA (Efficient Reinforcement Learning for End-to-End Video Agent) 를 제안합니다. EVA는 반복적인 Summary–Plan–Action–Reflection 추론을 통해 작동하며, 에이전트가 능동적으로 비디오 정보를 탐색하고 활용하도록 합니다. 이를 위해 저자들은 SFT (Supervised Fine-Tuning) , KTO (Kahneman–Tversky Optimization) , GRPO (Generalized Reward Policy Optimization) 의 세 단계로 구성된 학습 파이프라인을 설계했습니다
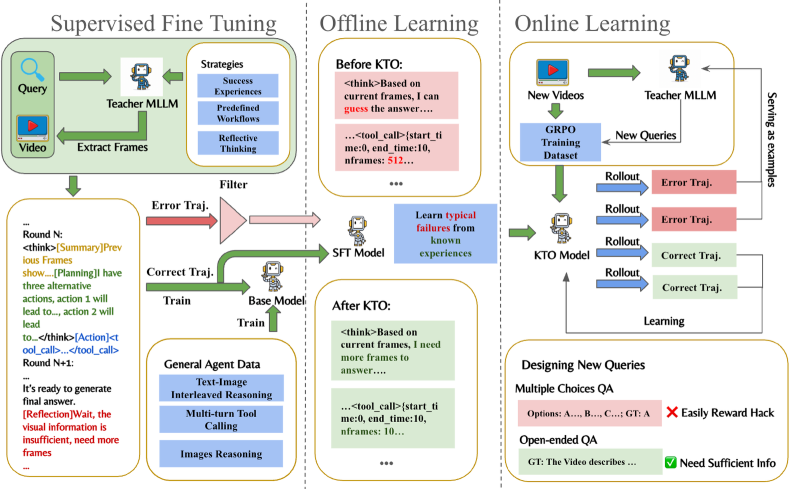
첫 번째 SFT Cold-Start 단계에서는 Qwen2.5-VL-72B 를 교사 MLLM으로 활용하여, tool-call 형식, 이미지-텍스트 추론, 프레임 수준 이해 및 기본 프레임 선택 전략을 포함하는 고품질 에이전트 비디오 이해 데이터를 생성합니다. 이 데이터는 Summary , Planning , Action , Reflection 의 네 단계로 구성되어 모델이 도구 사용의 매개변수와 출력을 더 잘 이해하도록 돕습니다. 두 번째 KTO 단계에서는 SFT 훈련 모델의 일반적인 실패 사례(예: 시각적 증거 부족에도 불구하고 답변 생성, 짧은 시간 내 과도한 프레임 샘플링)를 해결하기 위해 성공 및 실패 궤적(trajectory)을 포함하는 데이터셋을 사용합니다. KTO는 모델이 효과적인 전략을 선호하고 실패 모드를 피하도록 안내하여 후속 GRPO 의 수렴 및 안정성을 향상시킵니다. 마지막 GRPO 단계에서는 Data-Enhanced GRPO 파이프라인을 도입하여, KTO 훈련 모델의 실패 사례를 수집하고 이를 교사 MLLM의 In-Context Example로 사용하여 새로운 개방형 비디오 QA 데이터를 생성합니다 [Figure 2]. 보상 함수는 다지선다형 질문에 대한 Completeness Self-Verification (CSV) 보상과 개방형 질문에 대한 ROUGE score 를 혼합하여 사용하며, 모델이 적절한 추론 없이 답을 추측하는 것을 방지하기 위한 Format Reward (0.05)도 포함합니다.
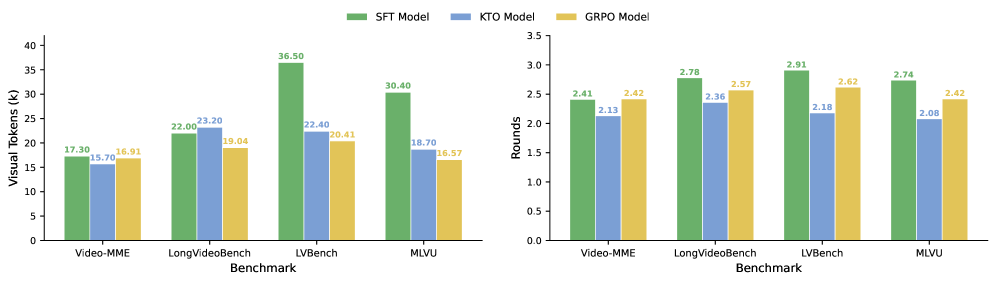
실험 결과, EVA는 6가지 비디오 이해 벤치마크에서 뛰어난 성능을 보였습니다. Sampling Dilemma Bench (LSDBench) 에서 EVA는 기존 Qwen2.5-VL 대비 +2.6% 향상된 51.8% 의 정확도(accuracy)를 달성했으며, 동시에 6.2K 의 시각적 토큰(visual tokens)만을 사용하여 브루트 포스(brute-force) 방식보다 현저히 적은 토큰을 소비했습니다 [Table 1]. Long-Form Video Understanding 벤치마크(LongVideoBench, MLVU, VideoMME, LVBench)에서도 EVA는 20-30 프레임 만으로 55.0% (LongVideoBench), 68.3% (MLVU), 60.2% (VideoMME-Overall), 43.3% (LVBench)의 높은 정확도를 기록하여, 대부분의 오픈소스 및 적응형 에이전트(adaptive agents)를 능가했습니다 [Table 2]. 특히 MLVU 벤치마크에서는 FrameThinker 의 59.1% 대비 +9.2%p 이상의 큰 폭의 성능 향상을 보여주었습니다 [Table 2]. Video-Holmes 벤치마크에서 제로샷(zero-shot)으로 평가된 EVA는 37.2% 의 Overall Accuracy 를 달성하여 Video-R1 (36.5%)과 같은 기존 모델들을 상회하며 강력한 일반화(generalization) 능력을 입증했습니다 [Table 3]. 어블레이션 연구(Ablation Study)를 통해 SFT, KTO, GRPO 각 단계가 모델의 효율성과 추론 전략을 점진적으로 개선함을 확인했습니다
4. Conclusion & Impact (결론 및 시사점)
본 연구는 반복적인 Summary–Plan–Action–Reflection 루프에 이해, 계획, 도구 사용, 그리고 반성(reflection)을 통합하는 쿼리-주도 프레임워크를 도입함으로써 진정한 자율 비디오 이해 에이전트 구축에 한 걸음 더 나아갔습니다. SFT cold-start , KTO , 그리고 GRPO 를 포함하는 3단계 훈련 패러다임을 통해 EVA는 지각 효율성(perceptual efficiency)과 추론 깊이(reasoning depth)의 균형을 학습하며, 수동적인 비디오 인식기에서 능동적이고 자기 주도적인 에이전트 와처(agentic watcher)로 발전합니다.
이 연구는 기존 MLLM의 Long-form Video Understanding 문제와 Sampling Dilemma 를 효과적으로 해결하며, 더 적은 시각적 토큰으로 높은 정확도를 달성하는 방법을 제시합니다. 제안된 Planning-before-Perception 패러다임과 3단계 학습 전략은 비디오 에이전트 분야에서 새로운 연구 방향을 제시하고, 학계에서는 효율적이고 해석 가능한 비디오 이해 시스템 개발에 기여할 수 있습니다. 산업계에서는 자율 주행, 보안 감시, 콘텐츠 분석 등 긴 비디오 데이터를 처리해야 하는 다양한 애플리케이션에서 MLLM의 활용 가능성을 크게 확장할 수 있는 잠재력을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Robust Tool Use via Fission-GRPO: Learning to Recover from Execution Errors
- [논문리뷰] TREK: Distill to Explore, Reinforce to Refine
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] TACO: Tool-Augmented Credit Optimization for Agentic Tool Use
- [논문리뷰] STARE: Surprisal-Guided Token-Level Advantage Reweighting for Policy Entropy Stability
Review 의 다른글
- 이전글 [논문리뷰] CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
- 현재글 : [논문리뷰] EVA: Efficient Reinforcement Learning for End-to-End Video Agent
- 다음글 [논문리뷰] GameplayQA: A Benchmarking Framework for Decision-Dense POV-Synced Multi-Video Understanding of 3D Virtual Agents
댓글