[논문리뷰] CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
링크: 논문 PDF로 바로 열기
저자: Akash Ghosh, Tajamul Ashraf, Rishu Kumar Singh, Numan Saeed, Sriparna Saha, Xiuying Chen, Salman Khan et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
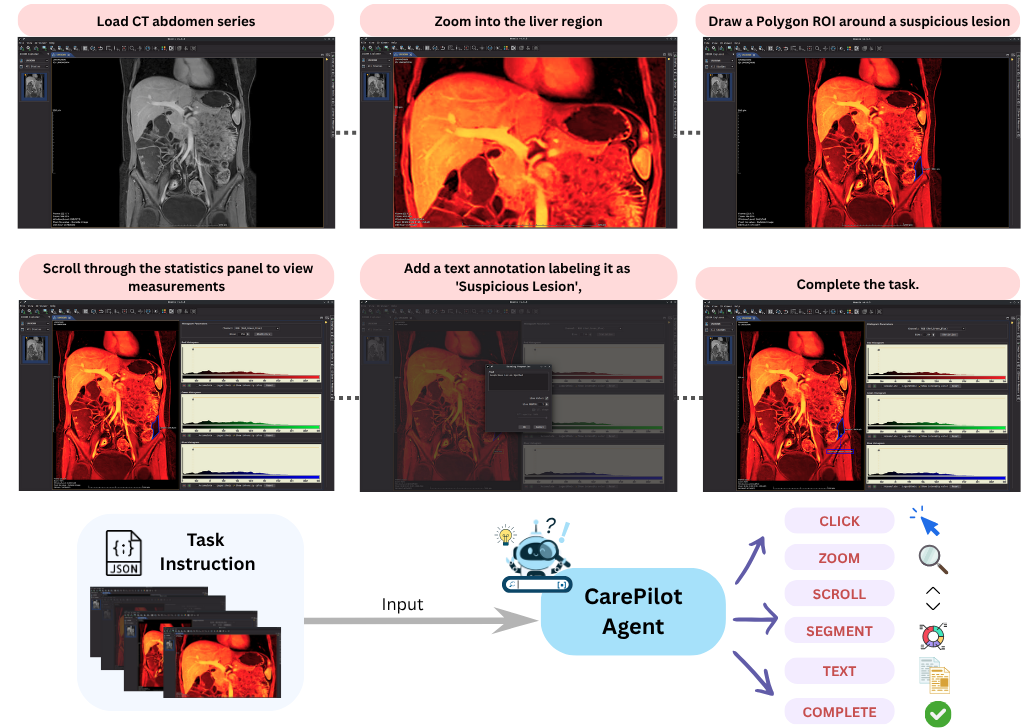
- CarePilot : 의료 분야의 Long-Horizon Computer Task Automation을 위해 제안된 Multi-Agent Framework로, Actor-Critic Paradigm 기반이다.
- CareFlow : 의료 소프트웨어 전반의 복잡하고 Long-Horizon인 소프트웨어 워크플로우를 포함하는 고품질의 Human-Annotated Benchmark Dataset이다.
- Long-Horizon Computer Task Automation : 의료 애플리케이션과 같은 특정 도메인 소프트웨어 환경에서 수십 개의 상호 의존적인 단계를 포함하는 복잡한 컴퓨터 작업을 자율적으로 수행하는 것을 의미한다.
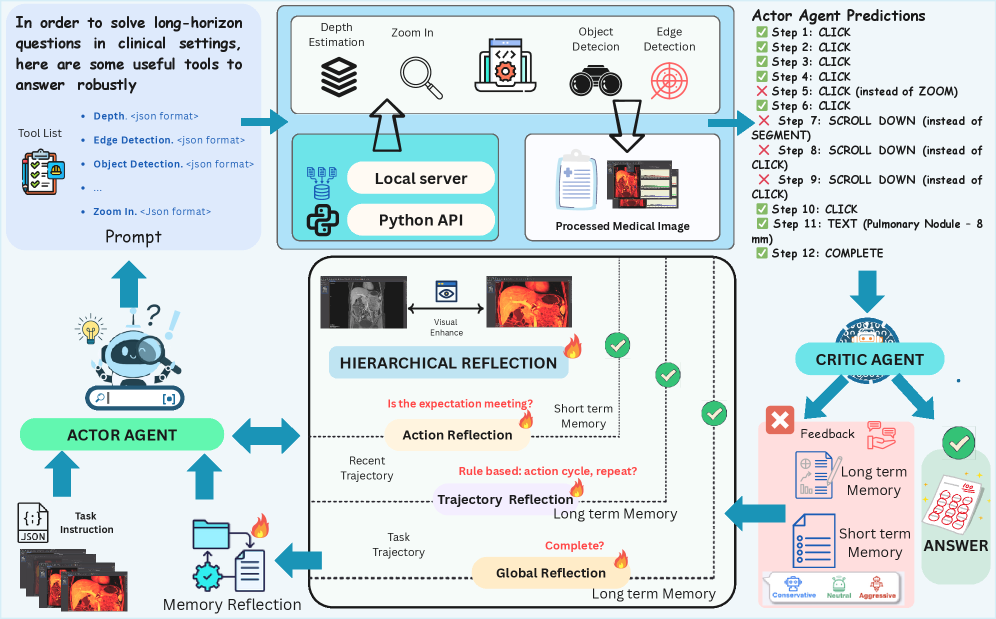
- Tool Grounding : UI Object Detection, Zoom/Crop, OCR, Template/Icon Matching과 같은 경량 Perception Tool의 출력을 통합하여 MLLM이 다음 Action을 예측하는 데 필요한 시각적 접지 신호를 제공하는 메커니즘이다.
- Dual-Memory Mechanism : Agent가 현재 Context와 과거 Context를 모두 추론할 수 있도록 Short-Term Memory (STM)와 Long-Term Memory (LTM)로 구성된 메모리 시스템이다. STM은 가장 최근의 Context를 요약하고, LTM은 Tool-Grounding Feature를 사용하여 압축된 Trajectory Embedding을 업데이트한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Multimodal Agentic Pipelines이 Human-Computer Interaction을 변화시키고 있지만, 대부분 Short-Horizon 또는 General-Purpose Application에 초점을 맞추고 있으며, 특히 Healthcare 분야에서 Long-Horizon Automation은 크게 탐구되지 않은 상태이다. 기존 Vision-Language Models (VLMs)는 의료 Context의 Long-Horizon Reasoning 및 Multi-Step Interaction에서 낮은 성능을 보여주며, 복잡한 Real-World Workflow를 안정적으로 실행하는 데 어려움을 겪고 있다. Healthcare Software Ecosystem은 본질적으로 광범위하고 Workflow-Centric하며, DICOM 서버/뷰어, Image-Computing 및 Annotation Tools, EMR/EHR 시스템, Laboratory Information Systems (LIS) 등을 포함한다. 이러한 플랫폼은 매우 Heterogeneous하고 Policy-Constrained하며, 사용자 인터페이스 업데이트 및 기관별 구성 등으로 인해 Agents가 특정 Layout에 Overfit될 경우 취약해진다. 이러한 Heterogeneity, Long-Horizon Dependencies, Strict Compliance Requirements의 조합은 Healthcare를 Long-Horizon GUI Agents에 대한 독특하고 도전적인 Testbed로 만든다. 현재 Medical Professionals가 수행하는 Healthcare-Specific Task를 반영하는 표준화된 Public Benchmark의 부재는 현 Agents의 Healthcare 도메인 Generalization 능력을 평가하기 어렵게 만든다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Healthcare Software Ecosystem에서 복잡하고 도메인 특화된 Long-Horizon Workflow를 처리하기 위해 Actor-Critic Paradigm에 기반한 Memory- 및 Tool-Augmented Multi-Agent Framework인 CarePilot 을 제안한다 [cite: 1, Figure 2]. CarePilot의 Actor 는 현재 Screenshot, Instruction을 받아 Tool Modules (예: UI Object Detection, Zoom/Crop, OCR, Template/Icon Matching)를 호출하여 Grounding Signals을 얻고, Dual-Memory (Long-Term 및 Short-Term Memory) 메커니즘을 통합하여 다음 Semantic Action을 예측한다 [cite: 1, Figure 2]. Critic 은 Actor의 제안을 평가하고, 관찰된 효과를 기반으로 메모리를 업데이트하며, Hierarchical Reflection을 통해 교정 피드백을 제공한다 [cite: 1, Figure 2]. 이 계층적 Reflection은 Action Reflector, Trajectory Reflector, Global Reflector의 세 가지 수준에서 이루어지며, 국지적 수정 및 장기적 안정성을 촉진한다. 훈련 과정에서는 Critic의 피드백을 Reasoning Distillation Paradigm에 따라 Actor에게 증류하여, 추론 시 명시적인 Multi-Agent Evaluation 없이도 Critic의 추론 능력을 Actor에 포함시킨다.
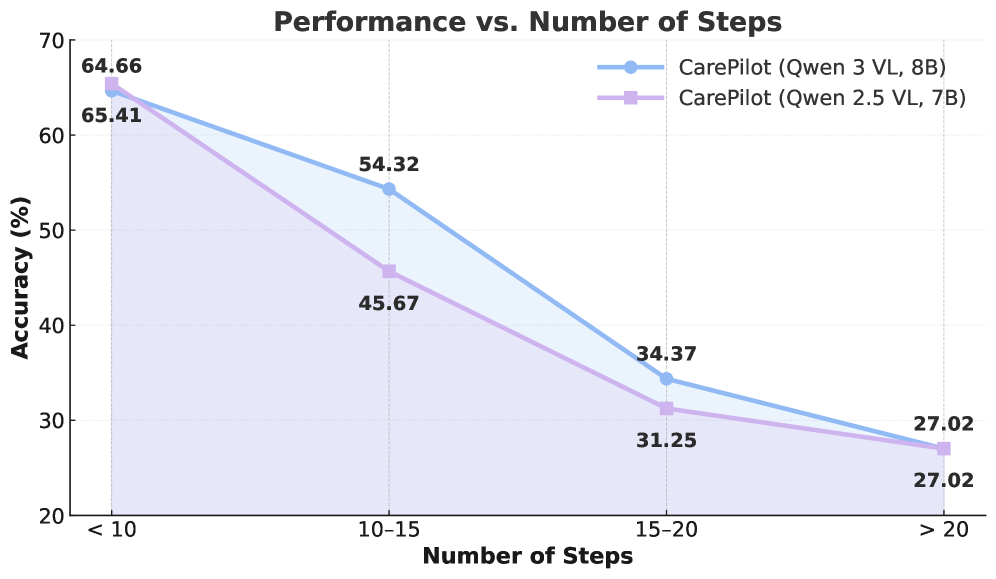
실험 결과, CarePilot은 CareFlow 벤치마크에서 State-of-the-Art 성능 을 달성했다. 특히, CarePilot (Qwen 3 VL-8B) 버전은 Task Accuracy (TA) 에서 48.76% 를 기록하여, GPT-5의 36.19% 및 Qwen 2.5 VL의 40.00% 를 크게 능가한다 [cite: 1, Table 3]. 또한 Step-Wise Accuracy (SWA) 에서는 90.18% 를 달성하여 GPT-5의 85.22% 보다 7% 이상 높은 성능을 보여주었다 [cite: 1, Table 3]. Out-of-Distribution (OOD) OpenHospital 벤치마크에서도 CarePilot (Qwen 3 VL-8B) 은 38.18% TA 로 강력한 Closed-Source 및 Open-Source 모델 대비 우수한 Robustness를 입증했다 [cite: 1, Table 4]. Ablation Studies 결과, Tool Grounding (TG) 이 가장 중요한 요소로 나타났으며, TG를 제거할 경우 TA가 9.37% 로 급락하는 것을 확인했다 [cite: 1, Table 6]. 또한 Long-Term Memory (LTM) 가 Short-Term Memory (STM) 보다 성능에 더 큰 영향을 미쳤다 [cite: 1, Table 6]. Figure 6은 Task Length가 증가함에 따라 성능이 저하되지만, Qwen 3 VL 기반의 CarePilot이 더 긴 Task에서 더 높은 안정성과 Resilience를 보임을 나타낸다 [cite: 1, Figure 6].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Healthcare 분야의 Long-Horizon Task Automation을 위한 Novel Multi-Agent Framework인 CarePilot 을 제안한다. CarePilot은 Tool Grounding과 Dual-Memory Mechanism ( Short-Term Memory 및 Long-Term Memory )을 통해 기록적인 Context를 통합하여 Robust한 다음 Action 예측을 가능하게 한다. 또한, 다양한 Clinical Subdomain의 여러 플랫폼에서 샘플을 포함하는 Long-Horizon Healthcare Software Task 전용 최초의 Benchmark인 CareFlow 를 제시했다 [cite: 1, Figure 1]. 실험 결과, CarePilot은 정확한 Contextual Grounding 및 Memory-Based Reasoning을 통해 기존 Open-Source 및 Closed-Source Multimodal Agents 대비 State-of-the-Art 성능 을 달성함을 입증했다. 이 연구는 Clinical 환경에서 안전하고, 해석 가능하며, Generalizable한 자동화를 위한 길을 열어줌으로써 Healthcare 분야의 Multimodal Agent 역량을 크게 발전시킬 잠재력을 가지고 있다. CareFlow는 제한된 Healthcare 플랫폼을 다루고 Pixel-Level Grounding이 부족하며, CarePilot이 High-Level Semantic Action을 예측한다는 점은 향후 연구의 개선점으로 제시되었다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] GUI-Libra: Training Native GUI Agents to Reason and Act with Action-aware Supervision and Partially Verifiable RL
- [논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
- [논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
- [논문리뷰] GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
- [논문리뷰] LingxiDiagBench: A Multi-Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis
Review 의 다른글
- 이전글 [논문리뷰] Can LLM Agents Be CFOs? A Benchmark for Resource Allocation in Dynamic Enterprise Environments
- 현재글 : [논문리뷰] CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
- 다음글 [논문리뷰] EVA: Efficient Reinforcement Learning for End-to-End Video Agent
댓글