[논문리뷰] Can LLM Agents Be CFOs? A Benchmark for Resource Allocation in Dynamic Enterprise Environments
링크: 논문 PDF로 바로 열기
The paper details "EnterpriseArena," a benchmark for evaluating LLM agents in long-horizon enterprise resource allocation. I need to extract:
- Authors : From the top of the paper.
- Keywords : From abstract and introduction.
- Key Terms & Definitions : Look for bolded terms or clearly defined concepts in Section 3.
- Motivation & Problem Statement : From Section 1 Introduction.
- Method & Key Results : From Section 3 EnterpriseArena and Section 4 Experiments and Results. I need quantitative results and specific metrics.
- Conclusion & Impact : From Section 5 Conclusion.
- Important Figures : I will select Figure 1 (Overview of EnterpriseArena), Table 2 (Evaluation Results), and Figure 4 (Cash by timestep). I need to get their full
image_urland shortcaption_kr.
Let's start extracting the information.
Authors : Yi Han, Lingfei Qian, Yan Wang, Yueru He, Xueqing Peng, Dongji Feng, Yankai Chen, Haohang Li, Yupeng Cao, Jimin Huang, Xue Liu, Jian-Yun Nie, Sophia Ananiadou
Keywords :
From Abstract and Introduction: LLM Agents, Resource Allocation, Enterprise Simulation, Financial Management, Uncertainty, Long-Horizon Decision-Making, CFO
Key Terms & Definitions :
- EnterpriseArena : First benchmark for evaluating agents on long-horizon enterprise resource allocation. It is a long-horizon enterprise simulator built from firm-level financial data, anonymized business documents, macroeconomic and industry signals, and expert-validated operating rules.
- Resource Allocation under Uncertainty : Decisions that bind scarce resources over time under delayed and stochastic consequences, requiring agents to balance competing objectives and preserve flexibility for future needs.
- Partially Observable Environment : The full organizational state is difficult to capture directly; agents must use budget-constrained organizational tools to acquire partial information about the enterprise's state.
- Long-Horizon Decision-Making : Actions whose consequences extend over long time horizons, requiring the agent to plan far ahead, covering multiple economic cycles (e.g., 132 months, or 11 years).
- Book-Closing : An action that triggers the reconciliation process, consolidating all accumulated operational records into a coherent enterprise state, providing an accurate view of the company's financial position.
- Fund-Raising-Request : An action to request external capital (equity or debt) with parameters for instrument type and target amount, subject to stochastic outcomes (success/failure, capital raised, settlement delay, contract cost) based on market and company conditions.
Motivation & Problem Statement : Large Language Models (LLMs) have enabled agentic systems capable of reasoning, planning, and acting in complex tasks, but their effectiveness in resource allocation under uncertainty remains unclear. Unlike short-horizon reactive decisions, resource allocation demands committing scarce resources over time, balancing competing objectives, and maintaining flexibility for future needs. Existing financial agent benchmarks largely overlook this fundamental structure of allocation problems, focusing instead on signal-response or judgment-oriented tasks that do not model binding scarce resources over time. This creates a significant gap, particularly in enterprise settings like financial management, where a Chief Financial Officer (CFO) must strategically allocate financial capacity across growth, liquidity, and robustness amidst evolving demand and macroeconomic conditions. The core problem is the lack of a benchmark that operationalizes resource allocation in dynamic, partially observable, and stochastic environments over a long time horizon.
Method & Key Results : 저자들은 EnterpriseArena 를 제안하며, 이는 불확실한 환경에서 장기적인 enterprise resource allocation 을 평가하기 위한 최초의 벤치마크이다. EnterpriseArena 는 132개월의 enterprise simulator 로, 기업 수준의 재무 데이터, 익명화된 비즈니스 문서, 거시경제 및 산업 신호, 전문가 검증을 거친 운영 규칙을 결합하여 CFO 스타일의 의사결정을 시뮬레이션한다. 이 환경은 partially observable 하며, budgeted organizational tools 을 통해서만 상태가 노출되므로, 에이전트는 정보 획득과 희소 자원 보존 사이에서 trade-off 를 해야 한다. 매월 에이전트는 book_closing , fund_raising_request , pass 중 하나의 액션을 선택하며, 각 선택은 즉각적인 가시성과 미래 기업 상태에 영향을 미친다.
평가는 survival 및 terminal valuation score 라는 두 가지 주요 지표를 사용한다. Survival 은 에이전트가 에피소드 전체 기간 동안 non-negative cash balance 를 유지하는지 평가한다. Terminal valuation score 는 최종 시점의 매출, 남은 현금 잔고, 그리고 tool calls 의 운영 비용을 고려하여 장기적인 기업 성장을 측정한다.
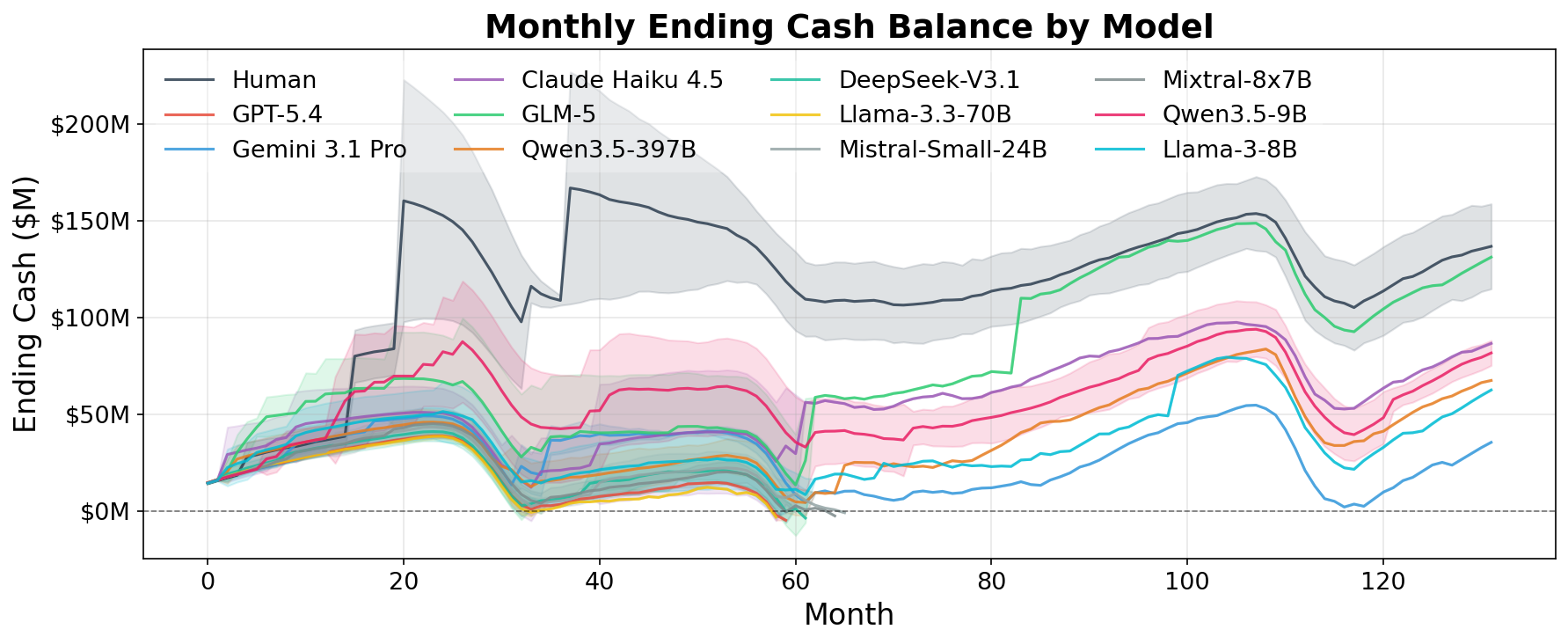
총 11개의 첨단 LLM을 대상으로 한 실험 결과, 현재 LLM 에이전트에게 효과적인 resource allocation under uncertainty 가 매우 어렵다는 것을 보여준다. 전체 실행 중 오직 16% 만이 132개월의 전체 기간 동안 생존했다. 모델 스케일이 성능을 reliably 예측하지 못하며, Qwen3.5-9B (9B 모델)가 Qwen3.5-397B (397B 모델)를 4.9배 outperform하고 모든 대규모 및 클로즈드-소스 모델을 능가하는 결과가 나타났다. 인간 전문가 baseline과 비교했을 때, LLM 에이전트들은 크게 뒤쳐진다. 인간 전문가들은 100% survival rate 를 달성했으며, Qwen3.5-9B 의 $78.8M 대비 거의 두 배인 $152.2M 의 terminal valuation score 를 기록했다. 인간 전문가들은 book closings 에 94.3% 의 액션을 할애하고 fundraising 에는 3.4% 만 사용했음에도, $207.1M 로 LLM 에이전트보다 두 배 이상의 자금을 조달했으며, 성공률도 75% 로 훨씬 높았다 [cite: 1, Figure 2, Figure 3]. 또한, 대부분의 LLM 에이전트들은 환경의 distributional shifts 를 예측하고 대비하는 데 실패하며, 이는 주로 유리한 조건에서 불리한 조건으로 전환되는 40~60개월 사이에 집중된 실패에서 드러난다 [cite: 1, Figure 4]. 오직 Qwen3.5-9B 만이 인간과 유사한 현금 버퍼를 구축하고 shift에 생존했다 [cite: 1, Figure 4].
Conclusion & Impact : EnterpriseArena 벤치마크를 통해, 현재 LLM 에이전트들은 불확실한 환경에서의 long-horizon enterprise resource allocation 에서 상당한 한계를 보인다. 낮은 survival rates 와 모델 스케일이 성능을 보장하지 않는다는 결과는 LLM 에이전트가 situational awareness 를 지속적으로 유지하고, 희소 자원을 전략적으로 배분하며, 환경 변화에 대비하는 능력이 부족함을 시사한다. 이 연구는 long-horizon organizational resource allocation 이 LLM 에이전트에게 새롭고 도전적인 역량의 frontier임을 확립한다. 이는 에이전트의 신뢰할 수 있는 계획 전략 개발을 지원하고, 실제 기업 사용 사례를 위한 벤치마킹을 개선하며, 단기적인 태스크 성능보다는 의사결정 견고성에 대한 연구를 장려할 수 있다. 그러나 시뮬레이션 환경의 한계, 단일 에이전트 의사결정 구조, 그리고 평가 모델의 다양성 부족은 향후 연구에서 해결해야 할 과제로 남아있다.
Figure selection and URLs :
- Figure 1: Overview for EnterpriseArena Benchmark.
src="2603.23638v1/enterprise_benchmark.png" - Table 2: Total evaluation of different LLM models in EnterpriseArena (5-round average), including human baseline. This is an HTML table, not an image. I should avoid it as per instructions.
- Figure 2: Aggregate fundraising actions taken by agents by timestep, averaged over 5 runs.
src="2603.23638v1/chart_cumulative_fundraising.png" - Figure 3: Aggregate book closing actions taken by agents by timestep, averaged over 5 runs.
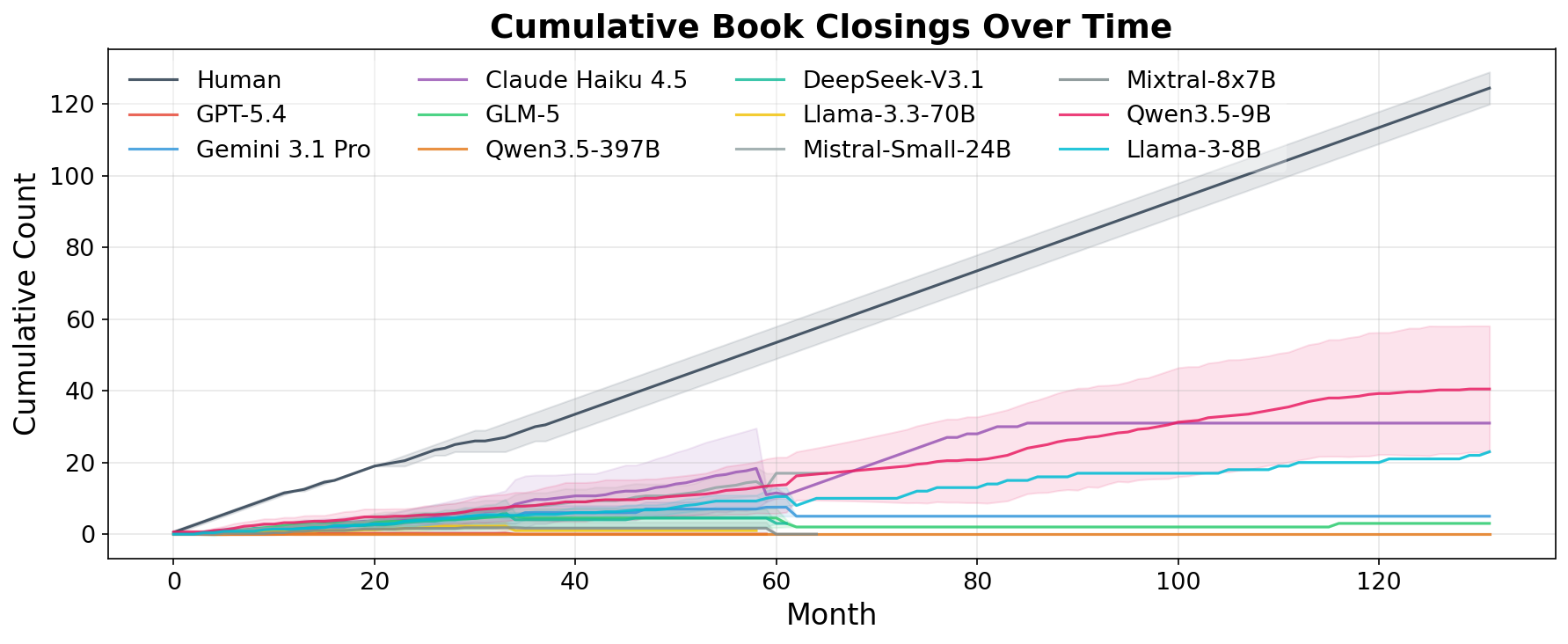
src="2603.23638v1/chart_cumulative_bookclosing.png" - Figure 4: Cash by timestep, averaged over 5 runs.
src="2603.23638v1/chart_monthly_cash.png"
I need to select up to 3 figures.
- Figure 1: Overall architecture/framework.
- Figure 4: Key results (cash by timestep) showing human vs LLM performance and distributional shifts.
- I will pick Figure 3 as it shows aggregate book closing actions, which is a key action in the methodology and also highlights the difference between human and LLM agents.
Let's refine the captions and construct the JSON.
Figure 1 image URL: https://arxiv.org/html/2603.23638v1/enterprise_benchmark.png
Caption KR: "EnterpriseArena 개요"
Figure 3 image URL: https://arxiv.org/html/2603.23638v1/chart_cumulative_bookclosing.png
Caption KR: "누적 Book Closing 액션"
Figure 4 image URL: https://arxiv.org/html/2603.23638v1/chart_monthly_cash.png
Caption KR: "월별 현금 잔고"
Now, I will combine all the extracted and summarized information into the required format. 저자: Yi Han, Lingfei Qian, Yan Wang, Yueru He, Xueqing Peng, Dongji Feng, Yankai Chen, Haohang Li, Yupeng Cao, Jimin Huang, Xue Liu, Jian-Yun Nie, Sophia Ananiadou et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- EnterpriseArena : 장기적인 enterprise resource allocation 환경에서 에이전트를 평가하기 위한 최초의 벤치마크이다. 기업 수준의 재무 데이터, 익명화된 비즈니스 문서, 거시경제 및 산업 신호, 전문가 검증을 거친 운영 규칙을 결합한 132개월 enterprise simulator 로 구성된다.
- Resource Allocation under Uncertainty : 제한된 자원을 시간 경과에 따라 할당하며, 지연되고 확률적인 결과 하에 경쟁하는 목표들 간의 균형을 맞추고 미래의 불확실한 요구에 대비하기 위한 유연성을 유지해야 하는 의사결정 문제이다.
- Partially Observable Environment : 조직의 전체 상태를 단일 뷰로 파악하기 어려우며, 에이전트가 예산이 제약된 조직 운영 tools 을 통해 부분적인 정보를 획득해야 하는 환경을 의미한다.
- Book-Closing : 내부 운영 기록을 통합하여 일관된 기업 상태(재무제표 포함)를 생성하는 정산 프로세스를 실행하는 액션이다. 이는 기업의 진정한 상태를 정확하게 파악할 수 있는 유일한 방법이다.
- Fund-Raising-Request : 외부 자본(equity 또는 debt)을 요청하는 액션으로, 자금 조달 수단 유형과 목표 금액을 지정한다. 시장 조건 및 기업 내부 상태에 따라 성공 여부, 조달 금액, 정산 지연, 계약 비용이 확률적으로 결정된다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 LLM(Large Language Models)의 발전은 복잡한 태스크에서 추론, 계획 및 실행이 가능한 에이전트 시스템을 가능하게 했지만, 불확실한 환경에서 자원을 효과적으로 할당할 수 있는지에 대한 여부는 불분명하다. resource allocation 은 단기적인 반응적 의사결정과 근본적으로 다르다. 에이전트는 제한된 자원을 시간 경과에 따라 투입하고, 상충되는 목표들 사이에서 균형을 잡으며, 불확실한 미래 요구에 대비한 유연성을 유지해야 한다.
기존의 금융 에이전트 벤치마크들은 주로 시장 관찰에 반응하는 신호-반응 태스크나 정보 검색 및 분석을 통한 판단 중심 태스크에 초점을 맞추어, resource allocation 문제의 핵심적인 구조인 시간 경과에 따른 희소 자원의 구속력 있는 할당을 모델링하지 못했다. 이러한 한계는 특히 대출 비즈니스의 CFO와 같은 기업 환경에서 두드러진다. CFO는 수요 및 거시경제 상황 변화에 따라 성장, 유동성, 견고성 간에 재무 역량을 할당해야 하는데, 기존 벤치마크는 이러한 장기적인 전략적 의사결정을 평가하지 못한다. 따라서 본 연구는 동적이고 부분적으로 관찰 가능하며 확률적인 환경에서 불확실성 하의 resource allocation 을 평가할 수 있는 벤치마크의 필요성을 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 불확실한 환경에서의 long-horizon enterprise resource allocation 을 평가하기 위해 EnterpriseArena 벤치마크를 도입한다. 이 벤치마크는 132개월(11년)의 enterprise simulator 로, 기업 수준의 재무 데이터, 익명화된 비즈니스 문서, 10년 규모의 거시경제 및 산업 신호, 그리고 전문가 검증을 거친 운영 규칙을 통합하여 CFO의 의사결정 과정을 모방한다. 환경은 partially observable 하며, 에이전트는 유동성, 내부 기록, 시장 조건 및 예상 현금 흐름에 대한 정보를 얻기 위해 예산이 제약된 organizational tools 을 활용해야 한다. 매월 에이전트는 book_closing , fund_raising_request , pass 중 하나의 액션을 선택하며, 각 선택은 즉각적인 정보 가시성 및 미래 기업 상태에 영향을 미친다.
에이전트 성능은 두 가지 보완적인 지표로 평가된다: 첫째, 기업이 survival 하는지 (매월 non-negative cash balance 유지). 둘째, terminal valuation score 를 통해 장기적인 기업 성장 능력을 측정한다. Score 는 최종 시점의 trailing-twelve-months revenue , 남은 cash balance , 그리고 총 tool calls 횟수에 대한 페널티를 포함한다.
총 11개의 첨단 LLM을 대상으로 한 실험 결과, EnterpriseArena 태스크는 현재 모델들에게 매우 도전적인 것으로 나타났다. 전체 실행의 16% 만이 132개월의 전체 기간 동안 생존했으며, 11개 모델 중 5개 모델은 어떤 시도에서도 생존하지 못했다. 특히, 모델 스케일이 성능을 reliably 예측하지 못하는 흥미로운 결과가 도출되었다. Qwen3.5-9B (9B 모델)는 Qwen3.5-397B (397B 모델)보다 4.9배 높은 성능을 보였고, 모든 대규모 및 클로즈드-소스 모델을 능가했다. 이는 효과적인 resource allocation under uncertainty 가 단순히 모델의 용량 함수가 아님을 시사한다.
인간 전문가 baseline 과의 비교에서는 LLM 에이전트와 상당한 격차가 관찰되었다. 인간 전문가들은 100% survival rate 와 $152.2M 의 terminal valuation score 를 달성하여, 가장 성능이 좋은 LLM 에이전트인 Qwen3.5-9B ( $78.8M , 80% survival )보다 거의 두 배 높은 점수를 기록했다. 인간 전문가들은 book closings 에 액션의 94.3% 를 할애하고 fundraising 에는 3.4% 만 사용했지만 [cite: 1, Figure 3], LLM 에이전트보다 두 배 이상 많은 $207.1M 의 자금을 75% 의 성공률로 조달했다 [cite: 1, Figure 2]. 이는 인간이 지속적인 상황 인식 유지와 전략적 자원 배분에 훨씬 능숙함을 보여준다. 대부분의 LLM 에이전트들은 환경의 distributional shifts 를 예측하고 대비하는 데 실패하며, 주로 환경 조건이 불리하게 바뀌는 40~60개월 사이에 많은 실패가 집중되었다 [cite: 1, Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 불확실한 환경에서 LLM 에이전트의 long-horizon enterprise resource allocation 역량을 평가하는 최초의 벤치마크인 EnterpriseArena 를 제시했다. 동적이고, 부분적으로 관찰 가능하며, 확률적인 CFO 스타일의 의사결정 환경을 모델링함으로써, EnterpriseArena 는 기존 금융 에이전트 벤치마크의 한계를 넘어섰다.
실험 결과는 현재 LLM 에이전트들이 이러한 설정에서 여전히 어려움을 겪고 있음을 명확히 보여준다. 낮은 survival rates , 모델 간의 넓은 성능 편차, 그리고 대규모 모델이 반드시 소규모 모델보다 우수하지 않다는 점은 LLM 에이전트가 지속적인 situational awareness 유지, 희소 자원의 전략적 배분, 그리고 시간 경과에 따른 환경 변화 대비 능력에서 제한적임을 시사한다.
궁극적으로, 이 연구 결과는 long-horizon organizational resource allocation 이 LLM 에이전트에게 독특하고 도전적인 역량의 frontier 임을 확립한다. 이는 에이전트의 보다 신뢰할 수 있는 계획 전략 개발을 지원하고, 실제 기업 사용 사례를 위한 벤치마킹을 개선하며, 단기적인 태스크 성능보다는 의사결정 견고성에 대한 연구를 장려하는 데 기여할 수 있다. 그러나 시뮬레이션 환경의 본질적인 한계, 단일 에이전트 의사결정 구조, 그리고 평가된 모델 아키텍처 및 에이전트 프레임워크의 다양성 부족은 향후 연구에서 확장될 필요가 있는 부분이다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Harnessing Uncertainty: Entropy-Modulated Policy Gradients for Long-Horizon LLM Agents
- [논문리뷰] AgentTTS: Large Language Model Agent for Test-time Compute-optimal Scaling Strategy in Complex Tasks
- [논문리뷰] Automating the Design of Embodied Agent Architectures
- [논문리뷰] When Classic Cache Policies Fail: Learning-Augmented Replacement for Semantic Retrieval Buffers
- [논문리뷰] Safety Testing LLM Agents at Scale: From Risk Discovery to Evidence-Grounded Verification
Review 의 다른글
- 이전글 [논문리뷰] CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
- 현재글 : [논문리뷰] Can LLM Agents Be CFOs? A Benchmark for Resource Allocation in Dynamic Enterprise Environments
- 다음글 [논문리뷰] CarePilot: A Multi-Agent Framework for Long-Horizon Computer Task Automation in Healthcare
댓글