[논문리뷰] CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
링크: 논문 PDF로 바로 열기
저자: Kaixin Li, Aarash Feizi, Kevin Qinghong Lin, Shravan Nayak, Xiangru Jian, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
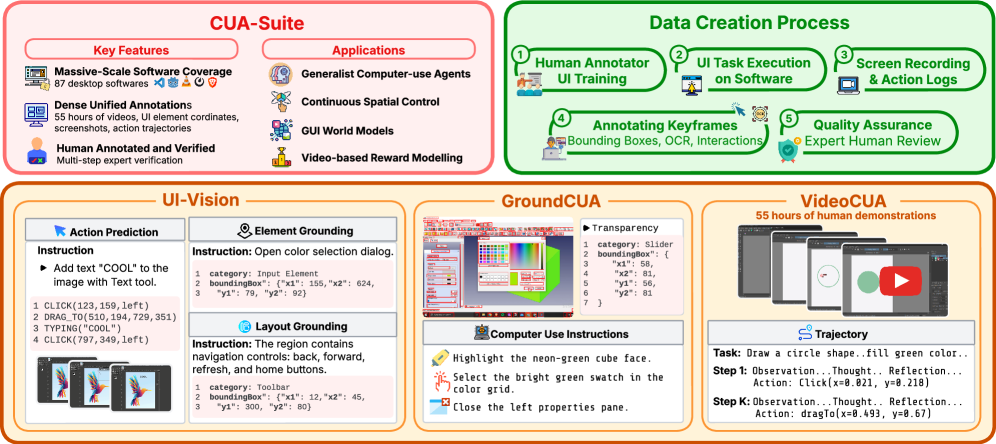
- CUA-Suite : 전문 데스크톱 컴퓨터 사용 에이전트(Computer-Use Agents, CUAs)를 위한 대규모 전문가 비디오 데모 및 dense annotations 생태계로, VideoCUA , UI-Vision , GroundCUA 로 구성된다.
- VideoCUA : CUA-Suite의 핵심 구성 요소로, 약 55시간 분량의 600만 프레임 에 달하는 연속적인 30fps 전문가 데스크톱 사용 비디오 데모와 kinematic cursor traces , multi-layered reasoning annotations 를 제공한다.
- UI-Vision : CUA-Suite의 벤치마크 구성 요소로, CUAs의 grounding 및 planning capabilities 를 평가하기 위한 데스크톱 중심 벤치마크이다.
- GroundCUA : CUA-Suite의 데이터셋 구성 요소로, 56K 의 주석이 달린 스크린샷과 360만 개 이상의 UI 요소 주석을 포함하는 대규모 grounding 데이터셋이다.
- Multi-layered Reasoning Annotations : VideoCUA 내 각 비디오에 제공되는 dense trajectory annotations로, observation , thought chain , action description , reflection 의 네 가지 계층으로 구성되어 에이전트의 instruction following 을 위한 action-level intent descriptions를 제공한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
지능형 에이전트가 복잡한 데스크톱 워크플로우를 자동화할 수 있다는 비전은 연속적이고 고품질의 인간 데모 비디오 부족으로 인해 진전이 지연되고 있다. 기존 데이터셋인 ScaleCUA 는 주로 sparse screenshots (예: 2백만 스크린샷, 약 20시간 분량)를 제공하여, visual world models 구축 및 continuous spatial control policies 학습에 필수적인 시간적 연속성이 결여되어 있다. 현재의 Computer-Use Agents (CUAs) 는 전문 데스크톱 애플리케이션(예: 3D 모델링 소프트웨어, IDEs)에서 현저히 낮은 성능을 보이며 (약 60% task failure rate ), 이는 planning 및 grounding 을 위한 풍부하고 dense한 annotation을 가진 훈련 데이터 부족이 주요 원인이다. 또한, 자동 생성된 데이터셋은 inherent noise가 많고, 인간 큐레이션 데이터셋은 부분적인 측면만을 다루거나 action discretization 에 의존하여 action 간의 intermediate visual feedback을 놓치는 한계가 있다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 데스크톱 컴퓨터 사용 에이전트의 훈련 및 평가를 위한 포괄적인 대규모 인간 주석 비디오 데모 에코시스템인 CUA-Suite 를 제안한다. CUA-Suite 는 VideoCUA , GroundCUA , UI-Vision 이라는 세 가지 핵심 리소스를 통합한다. VideoCUA 는 87개 의 다양한 애플리케이션에 걸쳐 약 10,000개 의 인간 시연 태스크를 포함하며, 30fps 의 연속적인 스크린 레코딩, kinematic cursor traces , 그리고 단계당 평균 497단어 의 multi-layered reasoning annotations 를 포함하여 총 약 55시간 (600만 프레임)의 전문가 비디오를 제공한다 [Figure 1, Table 2]. 이는 기존 최대 오픈 데이터셋 대비 2.5배 이상의 규모이다. GroundCUA 는 56K 개의 주석이 달린 스크린샷과 360만 개 이상의 UI 요소 주석을 포함하는 대규모 grounding 데이터셋으로, UI-Vision 평가에서 드러난 시각적 grounding bottleneck 을 해결하기 위해 고안되었다. UI-Vision 은 CUAs의 grounding 및 planning capabilities 를 평가하는 엄격한 데스크톱 중심 벤치마크이다.
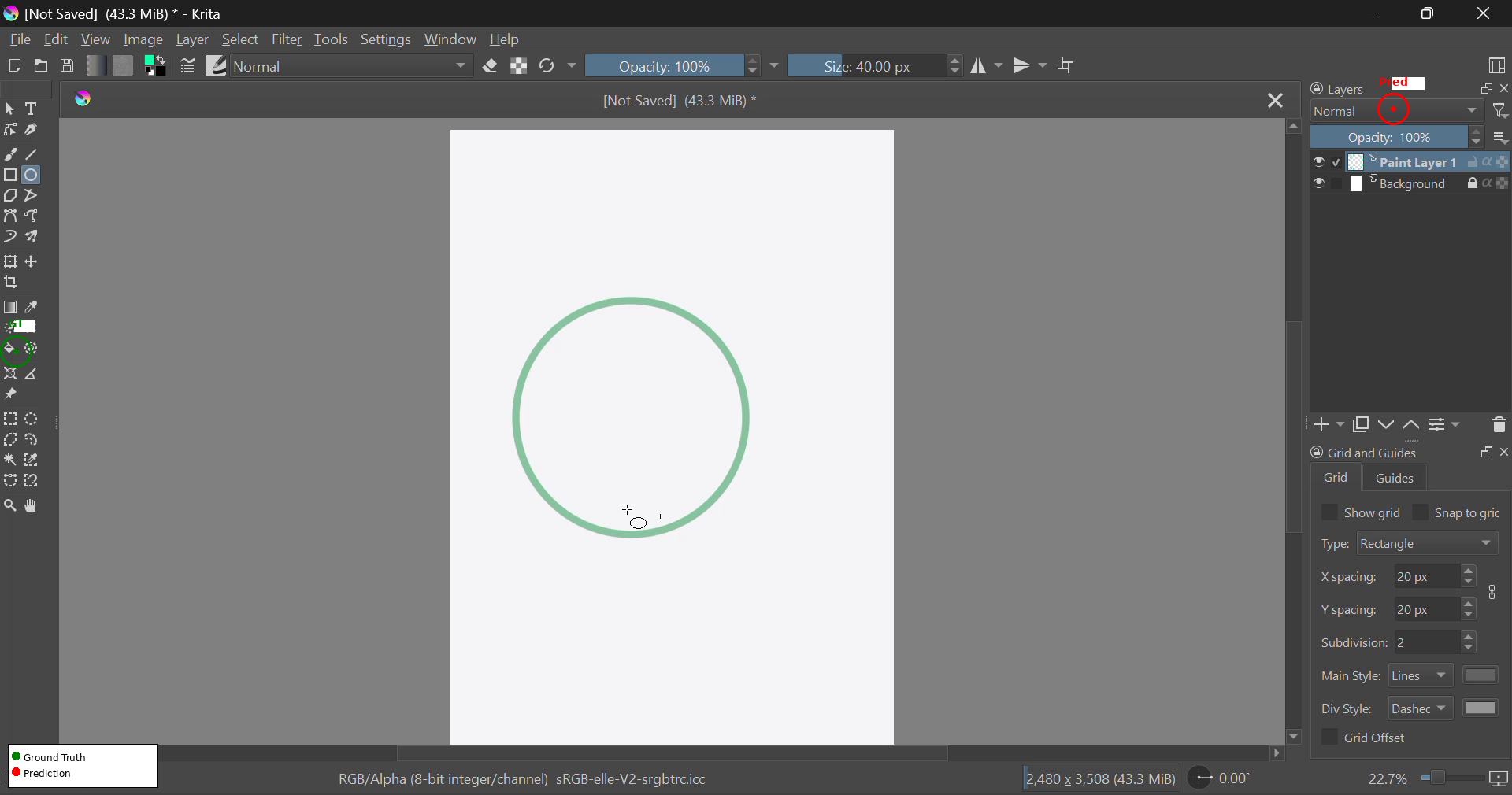
VideoCUA 의 예비 평가 결과, 현재 foundation action models 는 전문 데스크톱 애플리케이션에서 task-level prediction 에 대해 제한된 정확도를 보였다. OpenCUA-32B 모델은 @50px 에서 37.7% 의 성공률을 달성한 반면, OpenCUA-7B 모델은 16.5% 의 성공률에 그쳤다 [Table 3]. 이는 7B 에서 32B 로 모델 스케일을 늘릴 경우 @50px 에서 +21.2 퍼센티지 포인트의 개선과 mean pixel distance 가 387.5 에서 274.2 로 감소하는 consistent improvement 를 보였다. 질적 오류 분석 결과, 모델은 Krita, FreeCAD, Inkscape, OBS Studio와 같은 전문 데스크톱 애플리케이션의 복잡한 multi-panel interfaces 에서 시각적으로 유사한 상호작용 요소들을 구별하는 데 어려움을 겪는 것으로 나타났다
4. Conclusion & Impact (결론 및 시사점)
본 연구는 데스크톱 컴퓨터 사용 에이전트의 훈련 및 평가를 위한 포괄적인 에코시스템인 CUA-Suite 를 제시한다. 핵심적으로 VideoCUA 는 약 55시간 분량의 연속적인 30fps 레코딩, kinematic cursor traces , 그리고 multi-layered reasoning annotations 를 포함하는 최대 규모의 오픈 전문가 데스크톱 비디오 코퍼스를 제공한다. 이는 픽셀 단위의 정밀한 grounding (GroundCUA)과 엄격한 평가 (UI-Vision)를 통해 하나의 coherent한 에코시스템으로 보완된다. 본 연구의 평가는 현재 foundation action models 에 있어 spatial grounding 이 데스크톱 환경에서 주요 bottleneck 임을 시사하며, 이는 다양한 애플리케이션 도메인에서 성능 편차가 크게 나타남을 확인했다. CUA-Suite 의 연속적인 비디오 스트림, kinematic traces , 그리고 dense annotations는 generalist screen parsing , continuous spatial control , visual world models 와 같은 새로운 연구 패러다임을 지원하는 데 중요한 역할을 할 것으로 기대된다. 모든 데이터와 모델은 공개되어 커뮤니티의 차세대 범용 컴퓨터 사용 에이전트 연구를 가속화할 잠재력을 가진다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PerceptionRubrics: Calibrating Multimodal Evaluation to Human Perception
- [논문리뷰] OSWorld2.0: Benchmarking Computer Use Agents on Long-Horizon Real-World Tasks
- [논문리뷰] GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
- [논문리뷰] GUI vs. CLI: Execution Bottlenecks in Screen-Only and Skill-Mediated Computer-Use Agents
- [논문리뷰] V-Zero: Answer-Label-Free On-Policy Distillation with Contrastive Evidence Gating for Fine-Grained Visual Reasoning
Review 의 다른글
- 이전글 [논문리뷰] 6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
- 현재글 : [논문리뷰] CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
- 다음글 [논문리뷰] Can LLM Agents Be CFOs? A Benchmark for Resource Allocation in Dynamic Enterprise Environments
댓글