[논문리뷰] 6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
링크: 논문 PDF로 바로 열기
저자: Rundong Su, Jintao Zhang, Zhihang Yuan, Haojie Duanmu, Jianfei Chen, Jun Zhu
1. Key Terms & Definitions (핵심 용어 및 정의)
- NVFP4 (NVIDIA FP4) : 최신 NVIDIA 하드웨어 아키텍처(예: Blackwell)에 도입된 극단적인 압축을 위한 저비트 부동 소수점 형식 (1 sign bit, 2 exponent bits, 1 mantissa bit, E2M1)이다.
- INT8 : 메모리 및 계산 비용 절감을 위해 사용되는 8비트 정수 양자화 형식으로, 대칭 또는 비대칭 방식으로 적용될 수 있다.
- Post-Training Quantization (PTQ) : 모델이 학습된 후 가중치와 활성화 함수를 저비트 형식으로 압축하여 메모리 사용량을 줄이고 계산 속도를 높이는, 학습 과정이 필요 없는(training-free) 방법이다.
- Video Diffusion Transformers (DiTs) : 고품질 비디오 생성을 위한 백본으로 U-Net을 대체한 Transformer 기반 아키텍처로, 높은 계산 및 메모리 비용이 특징이다.
- Dynamic Mixed-Precision Quantization (DMPQ) : 추론 시간 동안 Transformer 블록 내부의 선형 레이어 활성화에 대해 동적으로 NVFP4 또는 INT8 정밀도를 할당하는 프레임워크로, 시간적 양자화 민감도에 기반한다.
- Temporal Delta Cache (TDC) : Transformer 블록의 잔차 델타(residual deltas)가 인접한 타임스텝 간에 높은 시간적 일관성을 보일 때, 캐시된 델타를 재사용하여 중복 계산을 건너뛰는 캐싱 메커니즘이다.
- Purified Cache Refresh (PDR) : DMPQ 와 TDC 의 결합 시 발생하는 양자화 노이즈 축적을 방지하기 위한 메커니즘으로, 캐시되는 델타를 가능한 한 순수하게 유지하기 위해 아웃라이어(outlier)가 많거나 시간적으로 불확실한 레이어에 더 높은 정밀도를 선택적으로 적용한다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Video Diffusion Transformers (DiTs)는 탁월한 비디오 생성 능력을 보여주지만, 높은 메모리 사용량과 막대한 계산 비용으로 인해 실제 배포에 심각한 제약을 받는다. 예를 들어, CogVideoX 와 같은 모델은 NVIDIA RTX-5090 GPU에서 49프레임의 1080p 비디오를 생성하는 데 약 22분 이 소요될 정도로 느리며, 일부 대형 모델은 일반 소비자용 장치에서 Out-Of-Memory (OOM) 오류를 일으키기도 한다.
기존 Post-Training Quantization (PTQ) 방법들은 일반적으로 정적(static) 비트 폭 할당을 사용하는데, 이는 확산(denoising) 타임스텝(timesteps)에 따라 활성화(activations)의 양자화 민감도가 크게 변동하는 Video DiTs에는 최적화되지 않은 방식이다 [Figure 1]. 이러한 정적 정책은 민감한 타임스텝에서 심각한 시간적 깜빡임(temporal flickering)을 유발하거나, 안정적인 타임스텝에서 압축 기회를 낭비하는 한계가 있었다. 또한, 기존의 Diffusion Caching 방법들은 모델 양자화와 독립적으로 작동하는 경향이 있으며, 이들을 단순하게 결합할 경우 양자화 오류가 누적되어 비디오 품질을 저하시킬 수 있다는 문제점이 존재한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 Video DiTs의 고비용 문제를 해결하기 위해, 추론 시간(inference-time)에 Dynamic Mixed-Precision Quantization (DMPQ) , Temporal Delta Cache (TDC) , 그리고 Purified Cache Refresh (PDR) 를 통합한 훈련-무관(training-free) 가속 프레임워크인 6Bit-Diffusion 을 제안한다
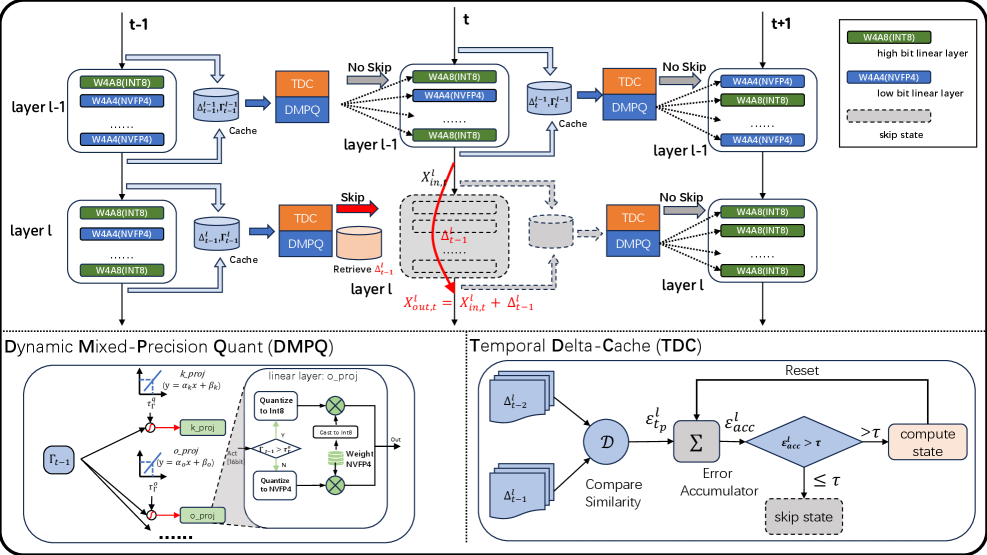
먼저, DMPQ 는 Transformer 블록의 이전 타임스텝 입력-출력 차이(Γt−1)와 해당 블록 내 선형 레이어의 양자화 민감도(Erel) 간의 강한 선형 상관관계를 발견하여 이를 활용한다
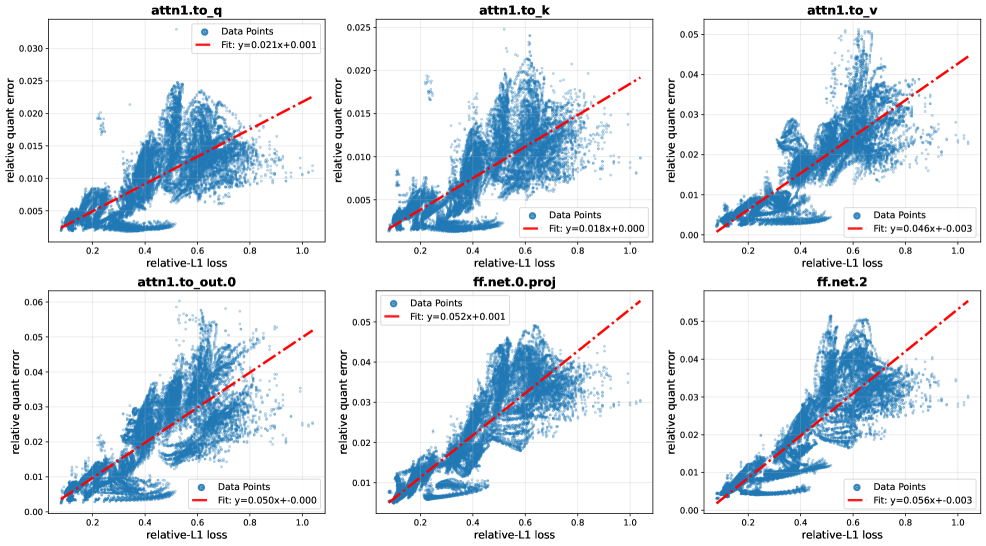
이 통찰을 바탕으로 경량 예측기를 설계하여, 시간적으로 안정적인(temporally stable) 레이어에는 NVFP4 를, 민감한(volatile) 레이어에는 INT8 을 동적으로 할당하여 메모리 압축을 극대화하면서도 견고성을 보장한다. 모든 가중치(weights)는 오프라인에서 NVFP4 로 양자화되지만, 활성화(activations)가 INT8 로 라우팅될 경우 해당 가중치도 INT8 로 즉시(on-the-fly) 캐스팅되어 GEMM (General Matrix Multiply) 데이터 타입 요구사항을 충족시킨다. 활성화 아웃라이어(outliers) 완화를 위해 온라인 Block Hadamard Transform 을 사용하여 오버헤드 없이 아웃라이어를 재분배한다.
다음으로, TDC 는 Transformer 블록의 잔차 델타(residual deltas)가 인접한 타임스텝 간에 높은 시간적 일관성을 보인다는 관찰을 기반으로 한다
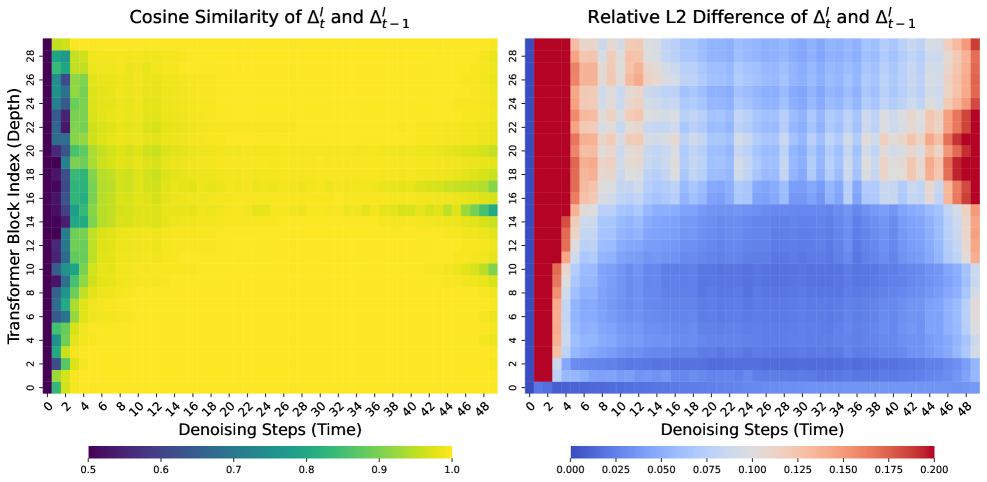
이는 대부분의 확산 과정에서 델타(Δtl)가 이전 델타(Δt−1l)와 매우 유사하다는 것을 의미하며, 이러한 시간적 중복성(temporal redundancy)을 활용하여 중복되는 블록 계산을 건너뛰고 이전에 캐시된 델타를 재사용한다. 캐시된 델타는 NVFP4 와 같은 초저정밀도(ultra-low precision) 형식으로 양자화되어 메모리 오버헤드를 최소화한다.
마지막으로, PDR 은 DMPQ 와 TDC 를 결합할 때 발생하는 양자화 노이즈의 시간적 축적 문제를 해결한다. 양자화 노이즈(ϵq)가 캐시된 델타에 누적되어 비디오 품질 저하로 이어지는 것을 방지하기 위해, 캐시되는 델타(Δt)가 최대한 순수하도록 보장한다. 이를 위해 아웃라이어 비율(Routlier)이 임계값(τoutlier=25)을 초과하는 레이어는 양자화를 건너뛰고 FP16/BF16 (full precision)을 사용하여 캐시를 고충실도(high-fidelity) 특징으로 새로 고친다.
실험 결과, CogVideoX 모델(2B 및 5B 파라미터)에서 제안하는 프레임워크는 BF16/FP16 baseline 대비 1.92× end-to-end acceleration 및 3.32× GPU memory reduction 을 달성하면서도, 원본과 유사한 비디오 품질을 유지함을 입증했다 [Table 2]. 특히, DMPQ (W4A6) 는 CogVideoX-2B 에서 Aesthetic Quality 0.5437 을 기록하며, 모든 W4A6 baseline을 능가하고, 심지어 SmoothQuant (0.5332) 및 ViDiT-Q (0.5332) 와 같은 최첨단 정적 W4A8 방법들과 동등하거나 더 우수한 성능을 보였다 [Table 1]. 또한, Ablation study를 통해 DMPQ 의 필요성, TDC 의 이점, 그리고 양자화 노이즈 축적 방지 및 Flow Score 를 4.7271 에서 5.5417 로 복원하는 데 있어 PDR 의 결정적인 역할을 확인했다 [Table 3].
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Video Diffusion Transformers의 높은 메모리 및 계산 비용을 줄이기 위한 6Bit-Diffusion 프레임워크를 제안한다. 이 프레임워크는 동적으로 정밀도를 할당하는 DMPQ , 시간적 중복성을 활용하는 TDC , 그리고 양자화 오류 누적을 방지하는 PDR 의 세 가지 핵심 구성 요소를 통해 이루어진다.
CogVideoX 에 대한 광범위한 실험을 통해, 제안된 방법론이 추론 속도를 1.92배 가속하고 메모리 사용량을 3.32배 줄이면서도 원본 비디오 품질을 성공적으로 유지함을 입증했다. 이 연구는 효율적인 비디오 DiTs 추론을 위한 새로운 baseline을 설정하며, 리소스 제약이 있는 환경에서도 고급 비디오 생성 모델의 실용적인 배포 가능성을 크게 향상시키는 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RAMP: Reinforcement Adaptive Mixed Precision Quantization for Efficient On Device LLM Inference
- [논문리뷰] HunyuanOCR-1.5: Making Lightweight OCR VLMs Faster and Better
- [논문리뷰] OrbitQuant: Data-Agnostic Quantization for Image and Video Diffusion Transformers
- [논문리뷰] LVSA: Training-Free Sparse Attention for Long Video Diffusion
- [논문리뷰] SANA-Streaming: Real-time Streaming Video Editing with Hybrid Diffusion Transformer
Review 의 다른글
- 이전글 [논문리뷰] WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
- 현재글 : [논문리뷰] 6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
- 다음글 [논문리뷰] CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
댓글