[논문리뷰] WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
링크: 논문 PDF로 바로 열기
Do not continue browsing. 저자: Zhen Li, Zian Meng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- World Modeling : 관측으로부터 세계가 어떻게 진화하는지 이해하고 예측하는 인공지능의 핵심 목표 중 하나로, 환경의 동적 프로세스를 모델링하는 것을 의미합니다.
- Action-Conditioned Dynamics : 에이전트의 액션에 따라 환경의 잠재 상태(latent-state)가 어떻게 변화하는지를 나타내는 동적 시스템입니다.
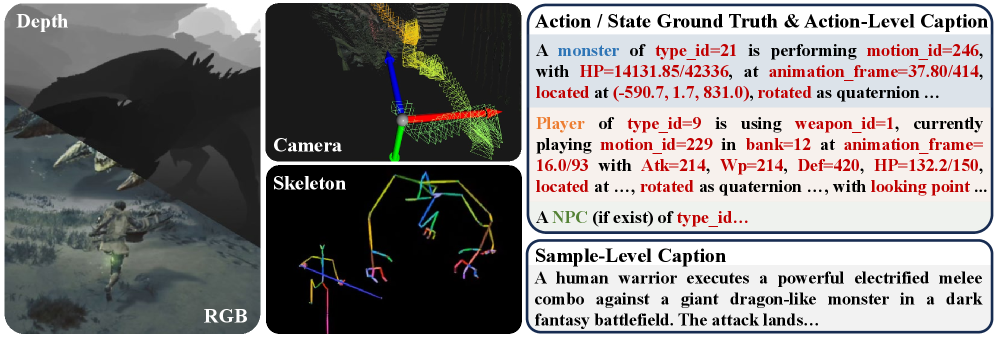
- Explicit State Annotations : 시각적 관측(visual observations) 외에 캐릭터의 스켈레톤, 월드 상태, 카메라 포즈, 깊이 맵 등 게임 세계의 내재적이고 명시적인 Ground Truth 정보를 의미합니다.
- Action Following : 모델이 입력 액션에 대해 생성된 비디오 내에서 해당 행동(sub-actions)을 얼마나 정확하게 재현하는지 측정하는 평가 지표입니다.
- State Alignment : 생성된 비디오에서 예측된 상태(예: 스켈레톤 키포인트)와 Ground Truth 상태 간의 일치도를 측정하여, 모델이 상태 전환을 얼마나 정확하게 모델링하는지 평가하는 지표입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존 비디오 월드 모델들은 액션에 조건화된 역학(action-conditioned dynamics)을 학습하는 데 어려움을 겪고 있는데, 이는 현재 데이터셋이 요구 사항을 충족하지 못하기 때문입니다. 대부분의 기존 데이터셋은 다양하고 의미론적으로 풍부한 액션 공간이 부족하며, 액션들이 기저 상태(underlying states)를 매개하기보다 시각적 관측(visual observations)에 직접적으로 묶여 있습니다. 이러한 문제로 인해 액션이 픽셀 수준의 변화와 얽히게 되어, 모델이 구조화된 월드 역학을 학습하고 장기적인 예측에서 일관성을 유지하는 것을 어렵게 만듭니다. 예를 들어, "shoot" 액션이 "remaining ammunition count"와 같은 내재적 상태에 영향을 미치지만, 이러한 상태는 시각적으로 명확하게 드러나지 않아 시각적 결과 예측에 혼란을 초래합니다. 이러한 한계점을 극복하기 위해, 저자들은 명시적 상태 주석을 포함하는 대규모 액션-조건부 월드 모델링 데이터셋의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
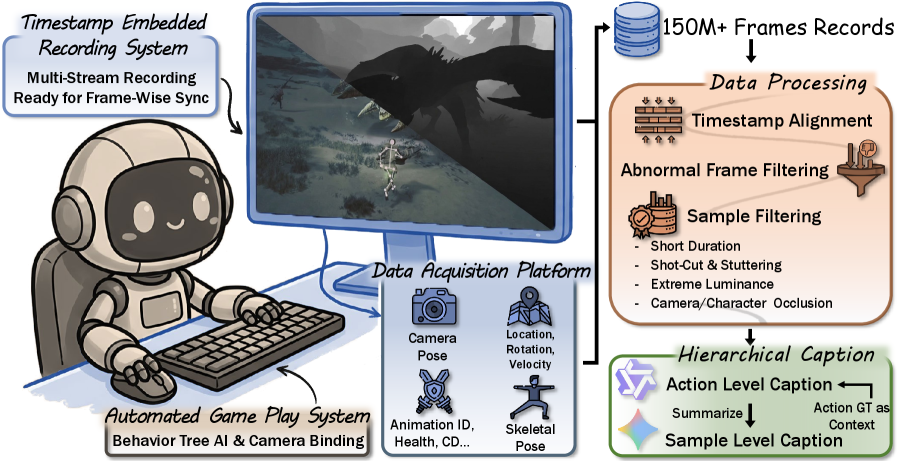
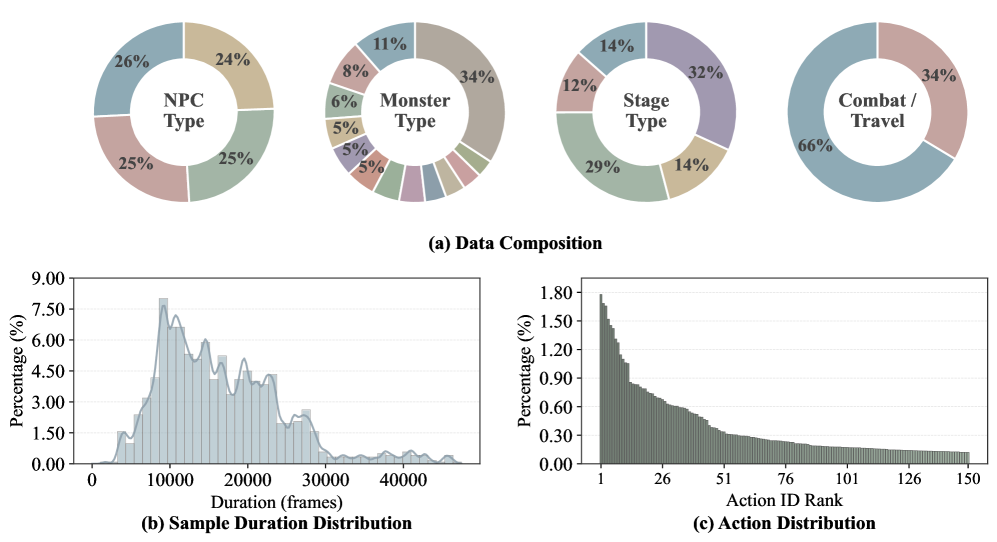
저자들은 AAA 액션 롤플레잉 게임인 Monster Hunter: Wilds 에서 자동으로 수집된 대규모 Action-Conditioned World Modeling Dataset인 WildWorld를 제안합니다. WildWorld는 1억 8백만 프레임 이상과 450개 이상의 액션을 포함하며, 캐릭터 스켈레톤, 월드 상태, 카메라 포즈, 깊이 맵 등 프레임별 동기화된 명시적 Ground Truth Annotation을 제공합니다 [cite: 1, Figure 1]. 데이터 수집을 위해 저자들은 자동화된 게임 플레이 파이프라인과 통합된 맞춤형 도구 체인을 개발하여, 최소한의 사람 개입으로 다양한 상호작용 시나리오를 커버하며 대규모 데이터를 수집할 수 있도록 했습니다 [cite: 1, Figure 2].
또한, 저자들은 WildWorld를 기반으로 대화형 월드 모델을 평가하기 위한 WildBench 벤치마크를 구축했습니다. WildBench는 Action Following과 State Alignment라는 두 가지 핵심 평가 메트릭을 도입하여 시각적 사실성뿐만 아니라 모델이 입력 액션을 얼마나 잘 따르고 정렬된 상태를 생성하는지 측정합니다.
실험 결과는 다음과 같습니다 [cite: 1, Table 1]:
- CamCtrl 모델은 Camera Control의 Absolute Trajectory Error ( ATE )를 Baseline 대비 2.61 감소시키고 Relative Pose Error ( RPE )를 0.05 감소시켰습니다.
- 스켈레톤 비디오를 조건부 입력으로 사용하는 SkelCtrl 은 Action Following 및 State Alignment에서 Baseline 대비 거의 100% 의 평균 개선을 달성했습니다.
- 명시적인 이산 및 연속 상태 정보를 직접 조건으로 사용하는 StateCtrl 및 StateCtrl-AR 은 세 가지 메트릭(Action Following, State Alignment, Camera Control) 전반에서 성능 향상을 보였습니다. 특히 StateCtrl 은 Camera Control 의 ATE 에서 0.94 , RPE 에서 0.07 을 기록하며 Baseline 대비 가장 우수한 성능을 보였습니다.
- SkelCtrl 은 Action Following 에서 92.81% 로 가장 높은 점수를, State Alignment 에서 22.03% 로 가장 높은 점수를 달성했습니다.
- 기존 VBench 메트릭(Motion Smoothness, Dynamic Degree)은 WildWorld에서 95% 이상으로 포화되어, 대화형 월드 모델 평가에는 Action Following 및 State Alignment와 같은 더 세분화되고 미묘한 평가 메트릭이 필요함을 시사했습니다.
4. Conclusion & Impact (결론 및 시사점)
이 연구는 명시적 상태 주석을 포함하는 대규모 비디오 데이터셋인 WildWorld를 제시하여 액션-조건부 월드 모델링 연구를 촉진했습니다. WildWorld는 photorealistic한 AAA ARPG에서 확장 가능한 데이터 수집 파이프라인을 통해 자동으로 수집되었으며, 450개 이상의 풍부하고 의미 있는 액션 공간과 프레임 수준의 캐릭터 스켈레톤, 월드 상태, 카메라 포즈, 깊이 등 다양한 주석을 제공합니다 [cite: 1, Figure 3]. 또한, WildBench 벤치마크를 통해 Action Following 및 State Alignment를 정량적으로 평가할 수 있는 프레임워크를 제공합니다. 실험 결과는 기존 모델들이 의미론적으로 풍부한 액션을 모델링하고 장기적인 상태 일관성을 유지하는 데 여전히 상당한 어려움을 겪고 있음을 보여주었습니다. 이러한 결과는 액션-조건부 비디오 생성 및 월드 모델링 발전을 위해 명시적 상태 정보 통합의 중요성을 강조하며, 향후 연구 방향에 대한 중요한 통찰을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] DreamWorld: Unified World Modeling in Video Generation
- [논문리뷰] EgoEdit: Dataset, Real-Time Streaming Model, and Benchmark for Egocentric Video Editing
- [논문리뷰] CVD-STORM: Cross-View Video Diffusion with Spatial-Temporal Reconstruction Model for Autonomous Driving
- [논문리뷰] X-Streamer: Unified Human World Modeling with Audiovisual Interaction
- [논문리뷰] RynnWorld-Teleop: An Action-Conditioned World Model for Digital Teleoperation
Review 의 다른글
- 이전글 [논문리뷰] VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
- 현재글 : [논문리뷰] WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
- 다음글 [논문리뷰] 6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models
댓글