[논문리뷰] VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
링크: 논문 PDF로 바로 열기
The paper "VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions" introduces VISOR, a method to improve the efficiency of Large Vision-Language Models (LVLMs) without discarding visual information. Instead of visual token reduction, VISOR sparsifies the interaction between image and text tokens. It leverages a small set of strategically placed attention layers: cross-attention for general visual context and dynamically selected self-attention layers to refine visual representations for high-resolution reasoning. The authors train a universal network across various computational budgets and use a lightweight policy mechanism for dynamic computation allocation based on per-sample complexity. VISOR achieves significant computational cost reduction while maintaining or exceeding state-of-the-art performance on diverse benchmarks, particularly excelling in tasks requiring detailed visual understanding.
Here's the summary following the requested format:
Part 1: 요약 본문
저자: Adrian Bulat, Alberto Baldrati, Ioannis Maniadis Metaxas, Yassine Ouali, Georgios Tzimiropoulos
## 1. Key Terms & Definitions (핵심 용어 및 정의)
- Large Vision-Language Models (LVLMs) : Vision Encoder와 Large Language Model (LLM)을 결합하여 multimodal understanding 및 reasoning을 수행하는 시스템. 이미지와 텍스트 입력을 처리한다.
- Visual Token Reduction : LVLM의 computational cost를 줄이기 위해 이미지에서 추출된 visual token의 수를 줄이거나 압축하는 기존 방법론.
- Cross-Attention : Text token이 visual token을 query하는 메커니즘으로, visual representation을 수정하지 않고 효율적으로 visual context를 제공한다.
- Self-Attention : Visual token들 간의 interaction을 모델링하여 visual representation을 update하고 refine하는 메커니즘으로, fine-grained reasoning에 필수적이다.
- FLOPs (Floating Point Operations) : 모델의 computational cost를 측정하는 지표로, 연산량 절감 정도를 나타내는 데 사용된다.
## 2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Large Vision-Language Models (LVLMs) 효율성 개선 접근 방식은 주로 visual token reduction에 기반한다. 그러나 이러한 방식은 challenging tasks, 특히 fine-grained understanding 및 reasoning을 요구하는 경우, information bottleneck을 생성하여 성능 저하를 초래한다. 저자들은 기존 token reduction 방법들이 coarse visual understanding이 필요한 task에서는 잘 작동하지만, high-resolution tasks에서는 상당한 정보 손실을 야기한다고 지적한다. LVLM 내에서 이미지 처리 방식에 대한 분석 결과, image-text interaction이 task-dependent하며, coarse task에서는 static visual features에 의존하는 반면, complex task에서는 visual information의 dynamic refinement가 중요함을 발견했다
또한, visual processing budget이 sample/task에 따라 adaptive해야 함을 확인했다
이러한 기존 방법론의 한계점과 LVLM의 비효율성을 극복하기 위해, visual information을 버리지 않고 inference cost를 줄이는 새로운 접근 방식의 필요성을 제기한다.
## 3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 visual information을 폐기하지 않고 inference cost를 줄이기 위해 이미지와 text token 간의 상호작용을 sparsify하는 VISion On Request (VISOR) 방법을 제안한다. VISOR는 LLM이 전체 high-resolution visual token set에 소수의 strategically placed attention layers를 통해 접근하도록 한다
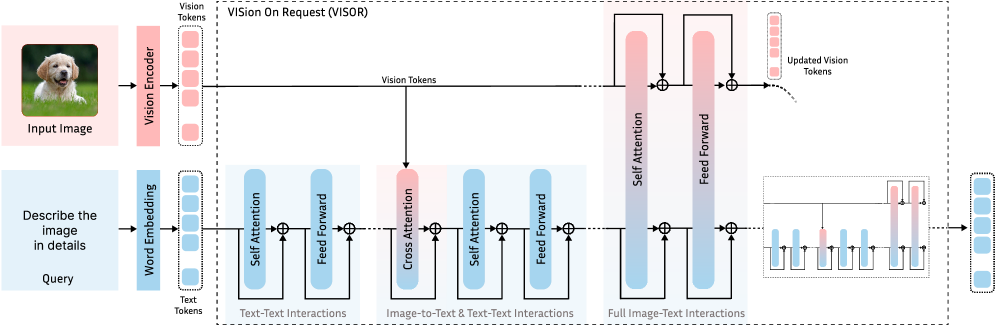
구체적으로, general visual context는 text-image 간의 efficient Cross-Attention 을 통해 제공되며, 몇 개의 well-placed 및 dynamically selected Self-Attention layers가 visual representation 자체를 refine하여 필요한 경우 complex, high-resolution reasoning을 가능하게 한다 [cite: 1, Figure 5].
VISOR는 먼저 다양한 computational budgets에 걸쳐 단일 universal network를 훈련한다. 이는 self-attention layer의 수를 조절하여 이루어진다. 그 다음, per-sample complexity에 기반하여 visual computation을 동적으로 할당하는 lightweight policy mechanism을 도입한다. Cross-attention layers는 computationally inexpensive하며 visual context를 효율적으로 제공하지만 visual token을 업데이트하지는 않는다. Fine-grained reasoning을 위해, VISOR는 소수의 full self-attention layers를 추가하여 visual token을 업데이트하고 계층적 visual representation을 구축한다. Adaptive inference는 routing token과 MLP layer를 통해 최적의 self-attention layer 구성을 예측함으로써 per-sample adaptation을 가능하게 한다.
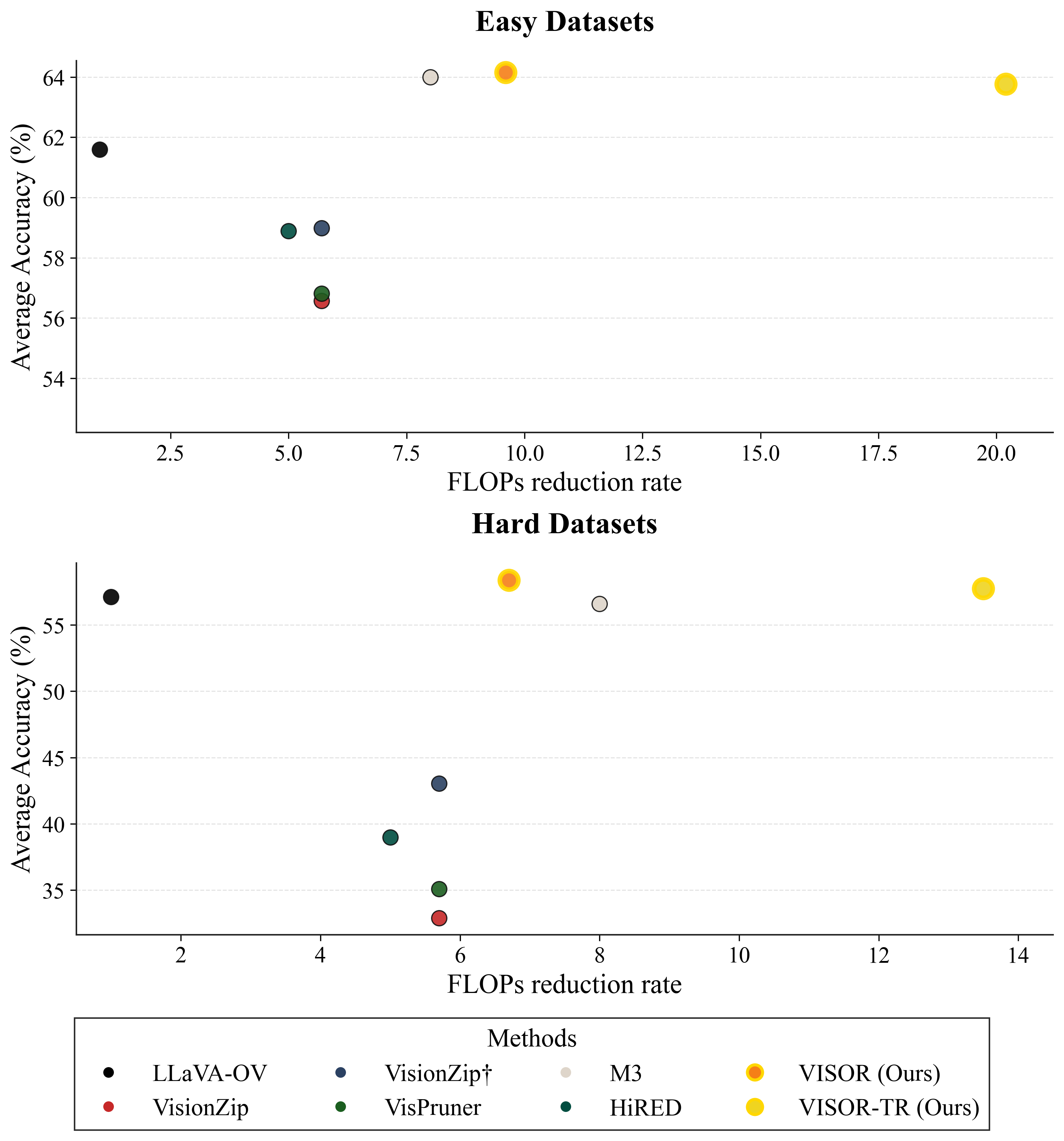
실험 결과, VISOR는 baseline LLaVA-OV 모델 대비 최대 8.6배의 FLOPs savings 를 달성하면서도 정확도를 유지하거나 향상시켰다 [cite: 1, Table 1]. 특히, VisionZip, HiRED, M^3^와 같은 기존 token reduction methods가 정보 병목 현상으로 어려움을 겪는 challenging tasks에서 모든 baseline을 능가하는 성능을 보였다 [cite: 1, Table 1]. VISOR는 coarse visual context를 요구하는 task에서는 기존 방법론과 유사하거나 더 높은 성능을 보이면서도 높은 효율성을 달성했다 [cite: 1, Table 1]. 더 나아가, 기존 token reduction 기법과 결합된 VISOR-TR 은 최대 18배의 FLOPs savings 를 달성하며 state-of-the-art 정확도를 유지했다 [cite: 1, Table 1]. 이는 VISOR가 token reduction 패러다임과 orthogonal하게 작동하며 추가적인 효율성 증대를 가져올 수 있음을 보여준다.
## 4. Conclusion & Impact (결론 및 시사점)
본 연구는 Large Vision-Language Models (LVLMs)의 inference cost를 줄이기 위한 새로운 방법론인 VISOR를 제안한다. VISOR는 visual information을 폐기하는 대신 image-text 및 image-image 상호작용을 sparsify하여 효율성을 높인다. 이를 통해 효율적인 cross-attention으로 text-image 상호작용을 모델링하고, 소수의 선택적인 self-attention layers로 fine-grained visual understanding 및 reasoning에 필요한 visual feature refinement를 수행한다.
VISOR는 단일 universal network를 다양한 computational budgets에 맞춰 훈련하고, 추론 시에는 per-task 또는 per-sample complexity에 기반하여 visual computation을 동적으로 할당하는 lightweight policies를 활용한다. 이 연구는 LVLMs의 효율성을 획기적으로 개선하며, 특히 detailed visual understanding이 요구되는 challenging tasks에서 state-of-the-art token compression methods를 뛰어넘는 성능을 입증했다 [cite: 1, Figure 1]. 이는 해당 분야에서 효율성과 성능 간의 trade-off를 새로운 관점에서 해결하고, 더욱 경제적이면서도 강력한 multimodal AI 시스템 개발에 중요한 시사점을 제공한다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RaysUp: Ultra-light Universal Feature Upsampling via Geometry-Aware Ray Representation
- [논문리뷰] LayerRoute: Input-Conditioned Adaptive Layer Skipping via LoRA Fine-Tuning for Agentic Language Models
- [논문리뷰] LongAttnComp: Cross-Family Context Compression for Long-Context Reasoning
- [논문리뷰] ReactiveGWM: Steering NPC in Reactive Game World Models
- [논문리뷰] LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
- 현재글 : [논문리뷰] VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
- 다음글 [논문리뷰] WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
댓글