[논문리뷰] UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
링크: 논문 PDF로 바로 열기
저자: Jie Liu, Zilyu Ye, Linxiao Yuan, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- UniGRPO : Reasoning-driven Visual Generation을 위한 Unified Policy Optimization 프레임워크로, interleaved multimodal generation에서 텍스트와 이미지 생성 정책을 Jointly 최적화합니다.
- Interleaved Generation : 텍스트와 이미지 같은 여러 모달리티의 콘텐츠를 교차(alternating)하거나 반복적(iterative)으로 생성할 수 있는 모델 패러다임을 의미합니다.
- GRPO (Group Relative Policy Optimization) : Group-relative baseline을 사용하여 value model 없이 정책을 효율적으로 최적화하는 Reinforcement Learning 알고리즘입니다.
- Flow Matching : 생성 프로세스를 deterministic Ordinary Differential Equation (ODE) 또는 Stochastic Differential Equation (SDE)으로 공식화하여 시각적 합성을 수행하는 generative modeling 기법입니다.
- Classifier-Free Guidance (CFG) : Diffusion model에서 프롬프트 준수(prompt adherence)를 강화하기 위해 조건부(conditional) 및 무조건부(unconditional) score를 결합하는 기법이지만, multi-condition 또는 multi-round generation에서 계산 비용과 복잡성을 증가시키는 한계가 있습니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
생성형 AI는 Interleaved Generation이 가능한 unified multimodal model로 빠르게 발전하고 있으며, 이는 반복적인 추론(iterative reasoning)을 통해 복잡한 이미지 합성(image synthesis) 작업을 해결할 잠재력을 제공합니다. 이러한 발전을 위해서는 텍스트 및 이미지 생성 정책을 Jointly 최적화하는 Unified Reinforcement Learning (RL) Framework가 필수적입니다. 기존 연구들은 multi-turn generation으로의 확장 가능성을 보였지만, 텍스트와 이미지를 Jointly 최적화하는 RL Framework의 부재가 주요 한계점으로 지적됩니다. 특히, 표준 Flow Matching RL 훈련 방식은 Classifier-Free Guidance (CFG) 사용 시 분기형(branched) 계산 그래프와 높은 연산 비용으로 인해 복잡한 multi-round 및 multi-condition 시나리오로의 확장이 어렵습니다. 또한, 시각적 생성 RL에서 Reward Hacking을 효과적으로 완화하는 것 또한 중요한 도전 과제입니다. 본 연구는 이러한 문제들을 해결하기 위해, Prompt → Thinking → Image로 이어지는 단일 라운드의 Reasoning-Driven Image Generation을 핵심 단위로 삼아 새로운 프레임워크를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
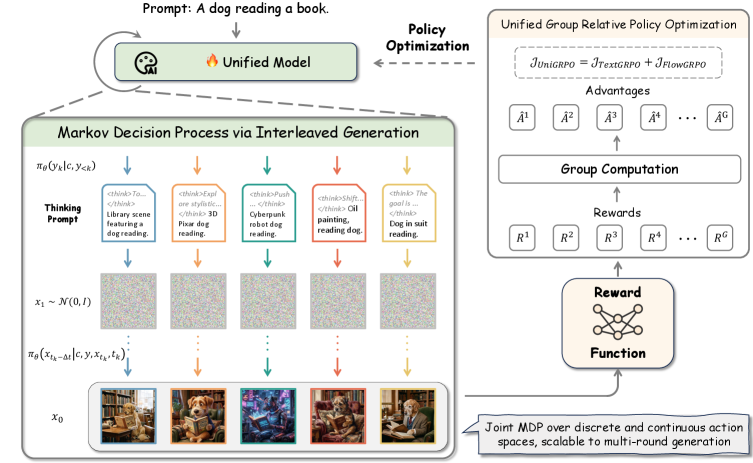
저자들은 UniGRPO를 제안하며, 이는 전체 "Prompt → Thinking → Image" 시퀀스를 단일 Markov Decision Process (MDP)로 공식화하는 Unified RL Framework입니다 [cite: 1, Figure 1]. 이 프레임워크는 Reasoning을 위한 표준 Text GRPO 와 Visual Synthesis를 위한 FlowGRPO 를 통합합니다. UniGRPO는 sparse terminal reward로부터 파생된 group-relative advantage를 사용하여 텍스트 및 이미지 생성 정책을 Jointly 최적화하여 모델이 더 유익한 추론 텍스트를 생성하고 동시에 시각적 합성 프로세스를 개선하도록 유도합니다.
확장성(scalability)을 위해 기존 FlowGRPO 훈련 방식에 두 가지 중요한 수정을 도입했습니다.
- Eliminating Classifier-Free Guidance (CFG) : 훈련 중에 CFG를 제거하여 생성 프로세스가 선형적이고 분기되지 않는(unbranched) rollout을 유지하도록 합니다. 이는 multi-turn 및 multi-condition 시나리오로의 확장에 필수적이며, 보상 최대화를 통해 정렬(alignment) 기능을 정책 가중치에 내재화합니다.
- Velocity-Based Regularization : Latent KL penalty 대신 velocity field에 직접 Mean Squared Error (MSE) penalty를 적용합니다. 이는 Reward Hacking을 효과적으로 완화하기 위한 보다 강력하고 직접적인 regularization signal을 제공하여, 모든 노이즈 수준에서 RL-tuned vector field가 사전 훈련된 참조 모델에 균일하게 가깝게 유지되도록 합니다. [Figure 5]
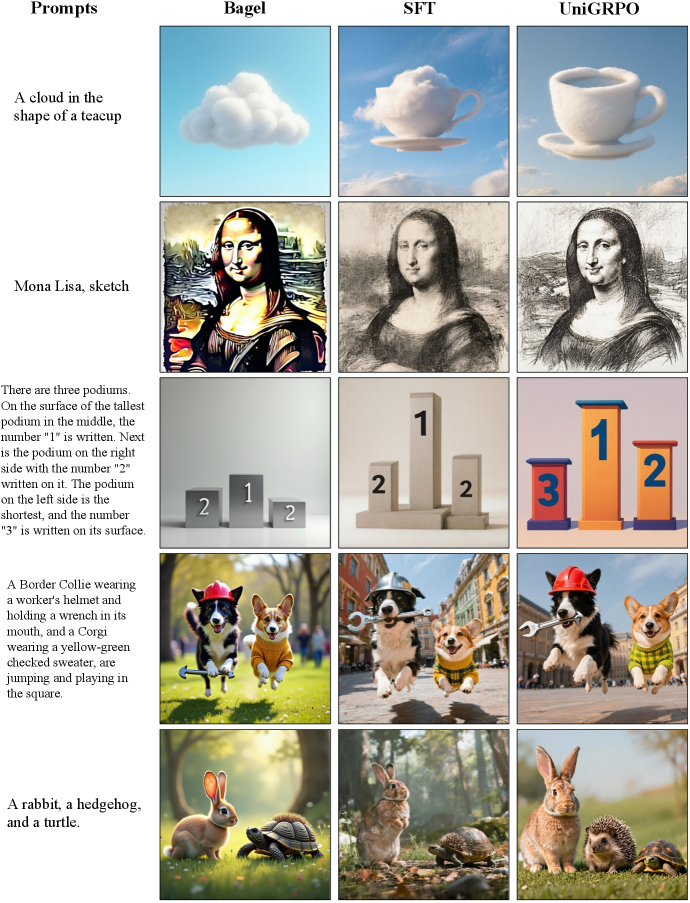
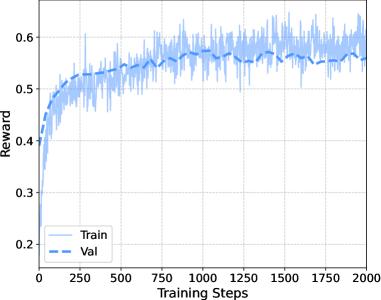
실험 결과, UniGRPO는 Text Alignment (TA) 벤치마크에서 0.8381 [cite: 1, Table 1], GenEval 벤치마크에서 0.90 [cite: 1, Table 1]의 최고 성능을 달성하여, SFT, ReFL, FPO, FlowGRPO, TextGRPO를 포함한 기존 baseline들을 능가했습니다. UniFPO는 수렴에 실패하여 GRPO 기반 공식의 안정성을 입증했습니다. 또한, UniGRPO는 기존 Bagel 모델의 과포화된 색상(oversaturated colors)과 인공물(synthetic artifacts) 문제를 해결하고, SFT 모델의 흐릿함(blurriness)을 개선하여 미학적 품질(aesthetic quality)과 Text-Image Alignment를 크게 향상시켰습니다 [cite: 1, Figure 2]. 추론 과정 또한 task-oriented하게 최적화되어 최종 시각적 결과와 긴밀하게 연동됩니다 [cite: 1, Figure 6]. CFG-free 훈련에 대한 Ablation Study는 CFG가 RL 기반 정렬에 불필요하며, 평가 시 CFG를 적용할 경우 비교 가능한 성능을 보임을 확인했습니다 [cite: 1, Figure 4]. 또한, Velocity MSE Regularization이 Reward Hacking 방지 및 안정적인 훈련 역학 유지에 가장 효과적임을 입증했습니다 [cite: 1, Figure 5]. 학습 과정에서 UniGRPO는 지속적인 reward 증가를 보여줍니다 [cite: 1, Figure 3].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 Interleaved Text-and-Image Generation 모델을 정렬하기 위한 Unified Reinforcement Learning Framework인 UniGRPO를 제안합니다. multimodal generation 프로세스를 MDP로 공식화함으로써, autoregressive reasoning과 flow-based visual synthesis를 단일 최적화 루프에 성공적으로 통합했습니다. CFG를 제거하여 선형 rollout을 강제하고 velocity-based regularization을 통해 Reward Hacking을 완화하는 minimalist 접근 방식은 확장 가능한(scalable) 훈련 레시피를 구축합니다. 경험적으로, UniGRPO는 Chain-of-Thought reasoning을 통해 이미지 생성 품질을 효과적으로 향상시키며, 미래의 Fully Interleaved Model의 Post-Training을 위한 강력하고 확장 가능한 baseline을 제공합니다. 이는 interactive image editing, visual storytelling, multi-turn dialogue와 같은 복잡한 multi-round 시나리오에서 이 프레임워크를 적용할 수 있는 길을 열어줄 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Optimizing Visual Generative Models via Distribution-wise Rewards
- [논문리뷰] Illuminating Unified Multimodal Model for Free-form Interleaved Text-Image Generation
- [논문리뷰] InterleaveThinker: Reinforcing Agentic Interleaved Generation
- [논문리뷰] Reproducing, Analyzing, and Detecting Reward Hacking in Rubric-Based Reinforcement Learning
- [논문리뷰] Small RL Controller, Large Language Model: RL-Guided Adaptive Sampling for Test-Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] Uncertainty-guided Compositional Alignment with Part-to-Whole Semantic Representativeness in Hyperbolic Vision-Language Models
- 현재글 : [논문리뷰] UniGRPO: Unified Policy Optimization for Reasoning-Driven Visual Generation
- 다음글 [논문리뷰] VISion On Request: Enhanced VLLM efficiency with sparse, dynamically selected, vision-language interactions
댓글