[논문리뷰] RAMP: Reinforcement Adaptive Mixed Precision Quantization for Efficient On Device LLM Inference
링크: 논문 PDF로 바로 열기
저자: Arpit Singh Gautam, Saurabh Jha
1. Key Terms & Definitions (핵심 용어 및 정의)
- PTQ (Post-Training Quantization) : LLM의 weights와 activations를 낮은 bit-width로 변환하여 memory footprint를 줄이는 기법으로, retraining 없이 calibration을 통해 성능을 최적화합니다.
- Mixed-Precision Quantization : 모델 내 각 layer에 서로 다른 bit-width를 할당하여 accuracy와 efficiency 간의 trade-off를 최적화하는 advanced quantization 전략입니다.
- Scale Folding : Sub-4-bit quantization을 안정화하기 위한 preconditioning technique입니다. Activation outliers를 weights로 migrates하고, per-channel scaling 및 normalization-layer compensation을 통해 activation 분포를 안정화합니다.
- SAC (Soft Actor-Critic) : Off-policy reinforcement learning algorithm으로, entropy regularization을 통해 exploration과 exploitation의 균형을 맞추고 높은 sample efficiency를 제공합니다.
- HALO (Hardware-Aware Deployment) : RAMP의 학습된 bit allocation을
llama.cpp가 natively 지원하는 standardized GGUF quantization type으로 mapping하여 kernel fragmentation 없이 다양한 하드웨어에서 효율적인 inference를 가능하게 하는 deployment pipeline입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Large Language Models (LLMs)는 자연어 처리 분야를 혁신했지만, FP16 포맷의 Llama-2-13B 모델이 26GB 의 memory를 요구하는 등 막대한 memory requirement로 인해 consumer GPU나 edge device에 배포하는 데 어려움을 겪는 Memory Wall 문제가 존재합니다. 기존의 PTQ 방법론들은 이러한 문제를 해결하기 위한 주요 기술이지만, 몇 가지 중요한 한계를 가집니다. 첫째, 대부분의 PTQ 방법은 모든 layer에 uniform한 bit-width를 적용하여 layer별 quantization sensitivity 차이를 무시함으로써 suboptimal한 accuracy-efficiency trade-off를 야기합니다. 둘째, GPTQ 나 AWQ 와 같은 기존 방법들은 model-specific optimization과 costly한 recalibration을 필요로 하며, Llama-2-7B 에서 학습된 전략이 Mistral-7B 나 Llama-2-13B 와 같은 다른 모델로 zero-shot transfer 되지 않아 반복적인 최적화 비용이 발생합니다. 셋째, mixed-precision quantization은 이론적으로 우수하지만, inference 시 kernel fragmentation 을 유발하여 uniform quantization 대비 1.2-1.5배 느릴 수 있으며, 표준화된 mixed-precision 패턴을 지원하는 배포 포맷이 부족합니다. 이러한 한계점들은 LLM의 광범위한 배포를 저해하는 주요 요인으로 작용합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제들을 해결하기 위해 RAMP (Reinforcement Adaptive Mixed-Precision) 프레임워크를 제안합니다. RAMP 는 quantization을 sequential decision-making task 로 재정의하고, Soft Actor-Critic (SAC) 이라는 off-policy Reinforcement Learning (RL) algorithm을 사용하여 per-layer bit-width 할당 정책을 학습합니다
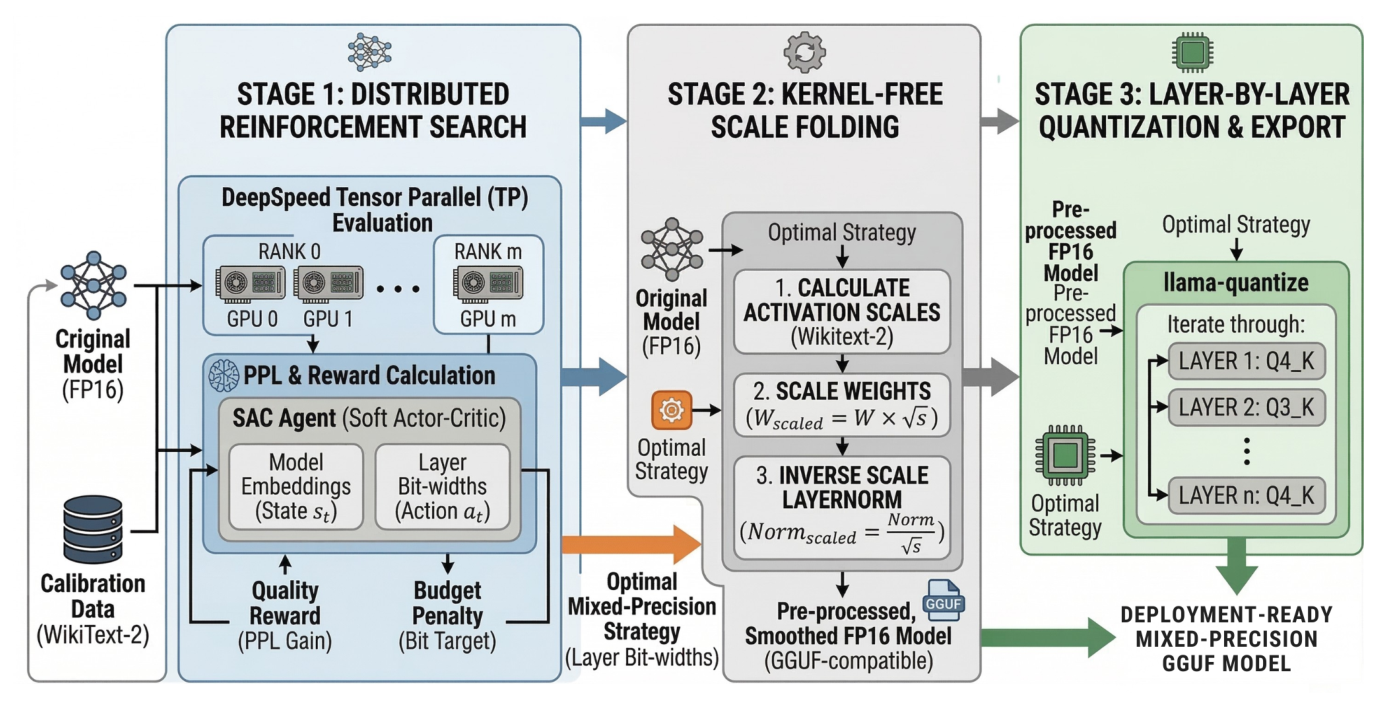 Figure 1: Overview of the RAMP pipeline. Stage 1 uses a Soft Actor-Critic agent in a distributed multi-GPU setting to discover a mixed-precision strategy. Stage 2 performs kernel-free compilation via scale folding. Stage 3 quantizes the model layer-by-layer and exports it in GGUF format for deployment.
Figure 1: Overview of the RAMP pipeline. Stage 1 uses a Soft Actor-Critic agent in a distributed multi-GPU setting to discover a mixed-precision strategy. Stage 2 performs kernel-free compilation via scale folding. Stage 3 quantizes the model layer-by-layer and exports it in GGUF format for deployment.
. 이 정책은 raw parameter values 대신 activation statistics, weight properties, structural descriptors, contextual features를 포함하는 11차원 layer embedding에 조건화됩니다 [Table 24]. 이는 모델 스케일에 invariant하며, zero-shot transfer 를 가능하게 합니다.
RAMP 는 품질을 우선시하면서도 bit budget을 유연하게 제약하는 Quality-Prioritized Reward Function 을 사용합니다. 이는 PPL degradation에 대한 asymmetric penalty와 budget cliff를 포함하는 tiered reward structure로 구성됩니다 [Figure 2]. 또한, Scale Folding 이라는 preconditioning technique를 도입하여 activation outliers를 weights로 migrates하고 normalization-layer compensation을 통해 activation 분포를 안정화합니다 [Algorithm 2]. 이 기술은 안정적인 sub-4-bit quantization을 가능하게 하여, Scale Folding 적용 시 Llama-2-7B 의 PPL 이 5.58 에서 5.54 로 개선되고 모델 크기가 3.80GB 에서 3.68GB 로 줄어드는 효과를 보였습니다 [Table 4].
RAMP 의 핵심 결과는 다음과 같습니다. Llama-2-7B 에서 RAMP 는 5.54 PPL (3.68 GB)을 달성하여, uniform 4-bit baseline 인 AWQ (5.60 PPL at 3.90 GB)보다 6% 작은 크기와 1% 높은 quality를 보이며 명확한 Pareto frontier 를 형성했습니다
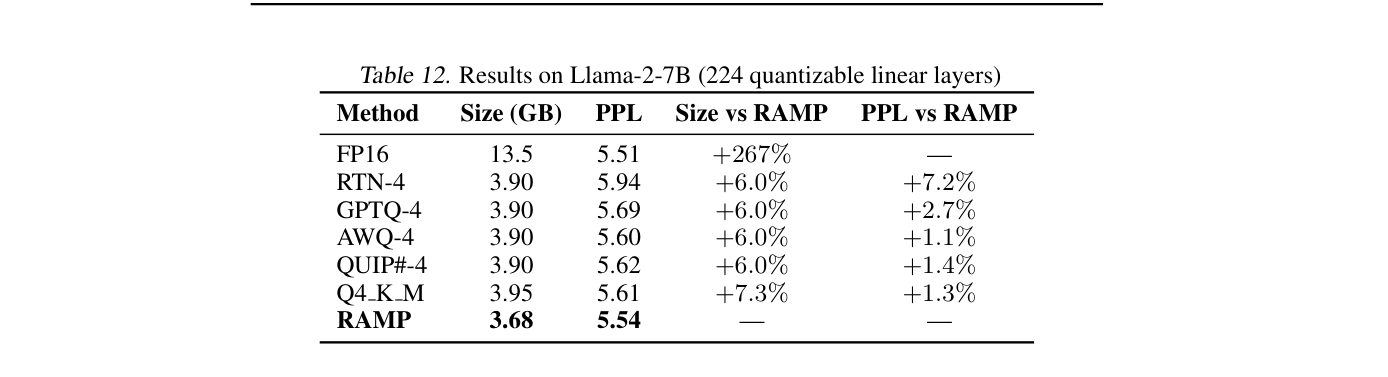 Table 12: Results on Llama-2-7B (224 quantizable linear layers)
Table 12: Results on Llama-2-7B (224 quantizable linear layers)
,
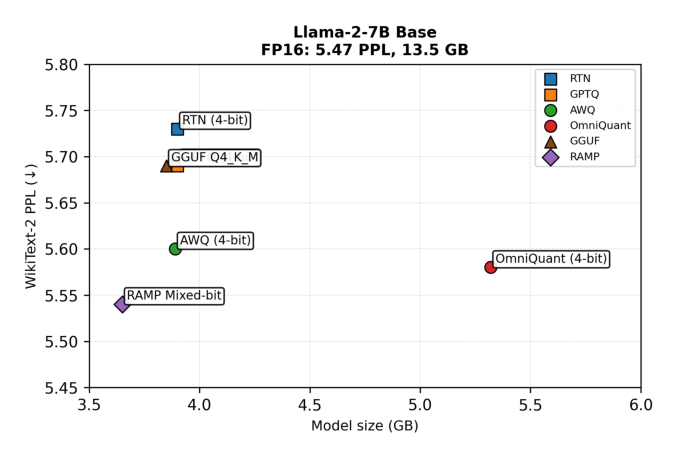 Figure 5: Perplexity vs. model size on Llama-2-7B. RAMP dominates uniform 4-bit baselines.
Figure 5: Perplexity vs. model size on Llama-2-7B. RAMP dominates uniform 4-bit baselines.
. 또한, Llama-2-7B 에서 훈련된 정책이 Llama-2-13B 및 Mistral-7B 에 zero-shot transfer 되어 종종 target-specific training보다 우수한 PPL 을 달성했습니다 [Table 16]. 이는 quantization sensitivity가 주로 architectural하다는 가설을 뒷받침합니다. 배포 측면에서, HALO pipeline은 학습된 bit allocation을 llama.cpp가 지원하는 GGUF format으로 export하여 CPU, GPU, Apple Silicon 등 다양한 하드웨어에서 kernel-free inference 를 가능하게 합니다. RAMP 는 FP16 baseline 대비 평균 99.5% 의 commonsense reasoning accuracy를 유지하면서도 높은 압축률을 달성합니다 [Table 17].
4. Conclusion & Impact (결론 및 시사점)
RAMP 는 Reinforcement Learning (RL) 을 활용하여 LLM의 transferable mixed-precision quantization 정책을 학습하는 최초의 프레임워크입니다. 이는 기존 PTQ 방법론들의 한계인 uniform bit-width 할당, 모델 간 비전이성, 그리고 하드웨어 배포의 어려움을 효과적으로 해결합니다. Scale Folding 기법과 HALO deployment pipeline을 통해 sub-4-bit quantization의 안정성을 확보하고, llama.cpp와 같은 표준화된 백엔드를 활용하여 다양한 하드웨어에서 kernel fragmentation 없이 효율적인 on-device inference 를 가능하게 합니다.
이 연구는 LLM 배포에 있어 중요한 시사점을 제공합니다. 첫째, quantization sensitivity가 모델 인스턴스보다는 Transformer 아키텍처의 구조적 특성에 기인한다는 가설을 강력히 뒷받침하며, 이는 향후 다른 압축 기법(pruning, sparsity, distillation)에도 일반화될 수 있는 quantization agent 개발의 가능성을 열어줍니다. 둘째, RAMP 는 Llama-2-7B 모델을 RTX 3090 에 배포할 경우 Cloud A100 대비 연간 탄소 배출량을 66-75% 절감할 수 있다는 추정치 [Table 23]를 통해 경제적, 환경적 이점을 제시합니다. 궁극적으로 RAMP 는 LLM의 광범위하고 효율적인 배포를 가능하게 하여, 연구 프로토타입과 실제 서비스 간의 간극을 줄이고 AI 기술의 접근성을 높이는 데 기여할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] When LLMs Read Tables Carelessly: Measuring and Reducing Data Referencing Errors
- [논문리뷰] Learning User Simulators with Turing Rewards
- [논문리뷰] AdaSR: Adaptive Streaming Reasoning with Hierarchical Relative Policy Optimization
- [논문리뷰] N-GRPO: Embedding-Level Neighbor Mixing for Enhanced Policy Optimization
- [논문리뷰] How Does Reasoning Flow? Tracing Attention-Induced Information Flow for Targeted RL in LLMs
Review 의 다른글
- 이전글 [논문리뷰] MosaicMem: Hybrid Spatial Memory for Controllable Video World Models
- 현재글 : [논문리뷰] RAMP: Reinforcement Adaptive Mixed Precision Quantization for Efficient On Device LLM Inference
- 다음글 [논문리뷰] Stereo World Model: Camera-Guided Stereo Video Generation
댓글