[논문리뷰] Stereo World Model: Camera-Guided Stereo Video Generation
링크: 논문 PDF로 바로 열기
저자: Yang-Tian Sun, Zehuan Huang, Yan-Pei Cao, Yifan Niu, Lin Ma, Xiaojuan Qi
키워: Stereo World Model, Camera-Guided Video Generation, 3D Geometry, Rotary Positional Encoding, Attention Decomposition, VR/AR
1. Key Terms & Definitions
- StereoWorld : 본 논문에서 제안하는 카메라-conditioned stereo world model로, binocular 이미지 기반 탐색 및 view-consistent stereo video 생성을 목적으로 합니다.
- Unified Camera-Frame RoPE : RoPE(Rotary Positional Encoding)의 확장 버전으로, latent token에 camera-aware rotary positional encoding을 적용하여 relative, view- 및 time-consistent conditioning을 가능하게 하고, pretrained video prior를 보존합니다.
- Stereo-aware Attention Decomposition : 4D attention을 3D intra-view attention과 horizontal row attention으로 분해하는 메커니즘으로, epipolar prior를 활용하여 disparity-aligned correspondence를 효율적으로 처리하고 compute를 절감합니다.
- DiT (Diffusion Transformer) : Transformer 기반의 diffusion model로, StereoWorld의 video diffusion model backbone으로 사용됩니다.
- End-to-End Generation : 중간 단계의 depth estimation이나 inpainting 없이 stereo video를 직접적으로 생성하는 방식입니다.
2. Motivation & Problem Statement
기존의 generative world model은 주로 monocular video representation을 사용하며, 이는 implicit depth, ambiguous scale, 그리고 long-horizon camera trajectory에서 누적되는 3D error와 같은 근본적인 기하학적 한계를 가집니다. RGB-D world model은 auxiliary depth channel을 도입하지만, 예측된 depth는 scene-dependent하고 scale-ambiguous하며 불안정합니다. 이러한 한계는 embodied intelligence나 navigation과 같이 accurate geometry가 critical한 애플리케이션에 적용하기 어렵게 만듭니다.
저자들은 monocular motion에서 depth를 추론하거나 imperfect depth predictor에 의존하는 대신, binocular observation에서 직접 geometry를 grounding하는 stereo world model의 필요성을 제기합니다. 기존 stereo video generation 접근 방식들은 monocular video를 생성한 후 depth estimation과 warping, inpainting을 통해 stereo로 변환하는 post-hoc 파이프라인에 의존하는데, 이는 non-end-to-end 방식이며, computational inefficiency 와 fine-detail 영역에서 error accumulation 에 취약합니다 [Figure 2]. Stereo 기반의 접근 방식은 binocular observation에서 직접적인 기하학적 단서를 얻어 이러한 문제점을 해결할 수 있습니다. 하지만 stereo world model을 구축하는 것은 view-consistent 예측, 대규모 compute 문제, 그리고 pretrained video prior 유지와 같은 복합적인 도전 과제를 안고 있습니다.
3. Method & Key Results
저자들은 카메라-conditioned stereo world model인 StereoWorld 를 제안합니다. 이 방법론은 pretrained video diffusion model인 Wan2.2-TI2V-5B 를 기반으로 하며, 두 가지 핵심 디자인을 도입합니다.
첫째, Unified Camera-Frame RoPE 전략을 사용합니다. 이는 backbone의 latent token space를 확장하여 camera-aware rotary positional encoding으로 보강합니다. 기존 RoPE scheme을 변경하지 않고 token dimension을 확장함으로써, pretrained video prior를 보존하면서 relative, view- 및 time-consistent conditioning을 가능하게 합니다. 초기화 전략으로는 Copy Init 이 Zero Init 보다 training stability와 convergence 속도 면에서 우수한 것으로 나타났습니다 [Table 4, Figure 7].
둘째, Stereo-aware Attention Decomposition 메커니즘을 설계합니다. 이 방법은 full 4D spatiotemporal attention을 3D intra-view attention ( Attn3D )과 horizontal row attention ( Attnrow )으로 분해합니다. 이는 rectified stereo pair에서 epipolar line이 horizontal하게 정렬된다는 기하학적 prior를 활용하여 disparity-aligned correspondence를 효율적으로 캡처합니다. 이 디자인은 computational complexity 를 크게 줄여, 4D attention의 3.115 × 10^10 FLOPs 대비 stereo attention에서 1.561 × 10^10 FLOPs로 약 50% 의 감소를 달성하면서도 강력한 stereo consistency를 유지합니다 [Table 5, Figure 3].
실험 결과, StereoWorld 는 post-hoc stereo conversion 방식과 비교하여 탁월한 성능을 보였습니다. 특히, generation speed 면에서 3배 더 빠르며, ViewCrafter 의 0.13 FPS 대비 0.49 FPS 를 달성했습니다
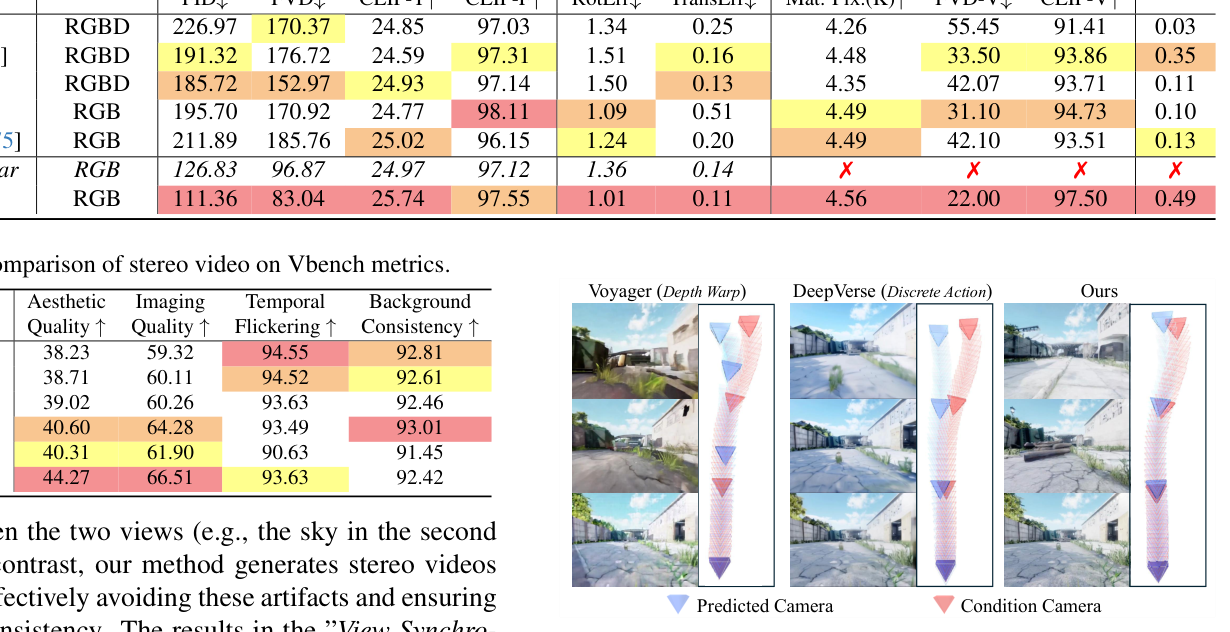 Table 2: Comparison of stereo video with SOTA methods on visual quality, camera accuracy, view synchronization and FPS.
Table 2: Comparison of stereo video with SOTA methods on visual quality, camera accuracy, view synchronization and FPS.
. Viewpoint consistency 는 CLIP-V 지표에서 97.50% 를 기록하며 기존 SOTA 방법론들( SEVA 94.73% )보다 약 5% 높은 성능을 보였습니다 [Table 2]. 또한, FID ( 111.36 ) 및 FVD ( 83.04 ) 지표에서 DeepVerse ( FID 191.32, FVD 176.72 ) 등 모노큘러 기반 모델 대비 현저히 낮은 수치를 보여 시각적 품질과 일관성에서 우위를 입증했습니다 [Table 2]. 생성된 disparity map 또한 기존 RGB-D world model에서 나타나는 artifacts 없이 깨끗하고 기하학적으로 일관된 결과를 보여주었습니다 [Figure 6].
4. Conclusion & Impact
본 논문은 camera-conditioned stereo vision model인 StereoWorld 를 통해 binocular visual appearance와 explicit geometry grounding을 공동으로 모델링하는 첫 번째 시스템을 제시합니다. 제안된 Unified Camera-Frame RoPE 는 pretrained prior에 대한 간섭을 최소화하며 relative camera parameter를 효과적으로 인코딩하고, Stereo-aware Attention Decomposition 은 epipolar constraint를 활용하여 computational complexity를 줄이면서 disparity-aligned correspondence를 유지합니다.
StereoWorld 의 개발은 해당 분야에 상당한 시사점을 제공합니다. 첫째, depth estimation이나 inpainting 파이프라인 없이 end-to-end binocular VR rendering 을 가능하게 하여 VR/AR 애플리케이션의 몰입감을 향상시킵니다. 둘째, metric-scale depth grounding을 통해 embodied agents의 spatial awareness를 개선하고, embodied policy learning을 강화합니다. 셋째, long-range monocular video generation 방법과의 호환성을 통해 extended interactive stereo scene synthesis를 위한 장기 비디오 증류(distillation)를 지원합니다. 궁극적으로 이 연구는 geometry-aware generative world representation을 향한 새로운 길을 열어주며, 가상 현실, embodied AI, long-horizon video synthesis와 같은 분야에 강력한 잠재력을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] RAMP: Reinforcement Adaptive Mixed Precision Quantization for Efficient On Device LLM Inference
- 현재글 : [논문리뷰] Stereo World Model: Camera-Guided Stereo Video Generation
- 다음글 [논문리뷰] Temporal Gains, Spatial Costs: Revisiting Video Fine-Tuning in Multimodal Large Language Models
댓글