[논문리뷰] Temporal Gains, Spatial Costs: Revisiting Video Fine-Tuning in Multimodal Large Language Models
링크: 논문 PDF로 바로 열기
저자: Linghao Zhang, Jungang Li, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MLLMs (Multimodal Large Language Models) : 텍스트 외에 이미지, 비디오 등 다양한 모달리티를 이해하고 처리할 수 있도록 설계된 대규모 언어 모델을 지칭합니다.
- Video-SFT (Video-based Supervised Fine-Tuning) : 비디오 데이터셋을 사용하여 모델의 시각적 이해 능력을 향상시키기 위한 지도 학습 방식의 Fine-tuning 과정을 의미합니다.
- Temporal Trap : Video-SFT 가 비디오 성능을 향상시키는 동시에 정적 이미지 벤치마크에서 제한적인 이득을 보이거나 성능 저하를 야기하는 현상을 지칭하며, 이는 시간적 적응과 공간적 시각 추론 간의 내재적 충돌을 반영합니다.
- Temporal Budget : Video-SFT 과정에서 비디오에서 샘플링되는 프레임의 수를 의미하며, 이 숫자가 이미지-비디오 성능 Trade-off에 중요한 영향을 미칩니다.
- Hybrid-Frame Strategy : 각 학습 샘플의 시공간적 요구에 따라 프레임 수를 적응적으로 할당하여 이미지-비디오 Trade-off를 부분적으로 완화하는 저자들이 제안하는 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 MLLMs 는 비디오-기반 Supervised Fine-tuning (Video-SFT) 을 통해 시각적 이해 능력을 크게 발전시켜왔습니다. 그러나 Video-SFT 가 시각적 능력의 미세한 진화, 특히 공간적 이해와 시간적 이해 사이의 균형에 미치는 영향은 아직 제대로 연구되지 않았습니다. 기존 연구들은 Video-SFT 가 시간적 모델링을 강화할 뿐만 아니라 통일된 시각 학습 전반에 걸쳐 긍정적인 영향을 미칠 것이라는 암묵적인 가정을 해왔습니다.
본 논문은 이러한 가정이 체계적으로 검증되지 않았으며, 비디오 이해의 발전이 MLLMs 에서 이미지 이해로 안정적으로 전이되는지에 대한 불확실성을 문제로 제기합니다. 저자들은 Video-SFT 가 비디오 성능을 향상시키지만, 종종 정적 이미지 벤치마크에서 제한적인 이득을 보이거나 심지어 성능을 저하시키는 일관된 패턴, 즉 Temporal Trap 현상
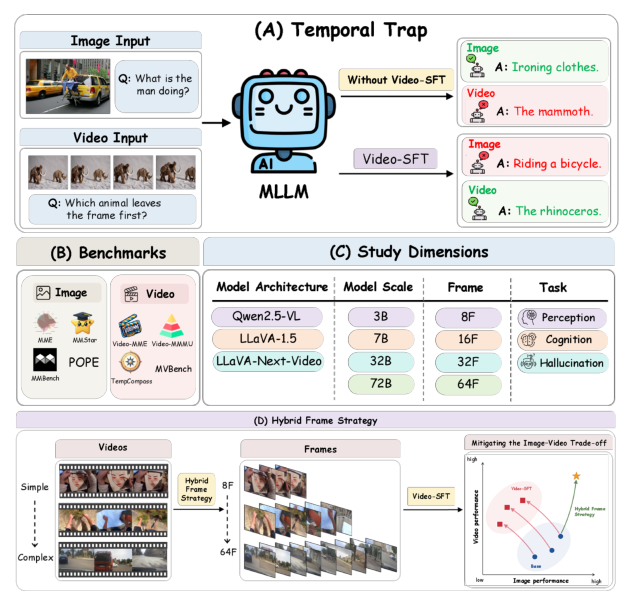 Figure 1: Overview of the temporal trap and our study.
Figure 1: Overview of the temporal trap and our study.
을 발견했습니다. 이러한 Temporal Trap 은 Temporal Budget 과 밀접하게 연관되어 있으며, 불필요한 시간적 정보가 모델의 정적 시각 표현을 방해하여 이미지 작업에 대한 일반화 능력을 약화시키는 것으로 나타났습니다. 이에 저자들은 Temporal Trap 을 완화하기 위한 새로운 전략의 필요성을 제기합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Video-SFT 가 MLLMs 의 시각적 능력에 미치는 영향을 모델 아키텍처 , 파라미터 스케일 , 프레임 샘플링 설정 이라는 세 가지 핵심 차원을 중심으로 체계적으로 분석합니다. 이들은 Temporal Trap 현상이 Video-SFT 이후 비디오 벤치마크에서는 성능이 향상되지만, 대부분의 이미지 벤치마크에서는 성능 저하가 나타나는 일관된 패턴임을 확인했습니다
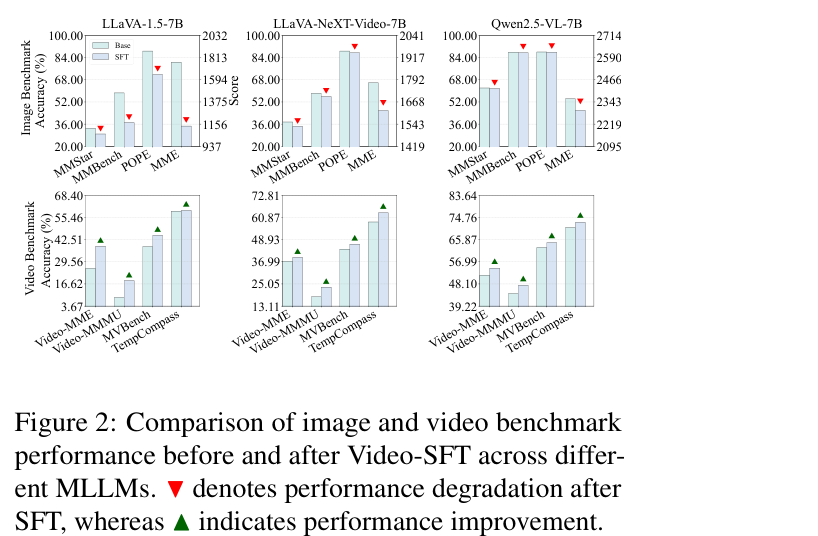 Figure 2: Comparison of image and video benchmark performance before and after Video-SFT across different MLLMs.
Figure 2: Comparison of image and video benchmark performance before and after Video-SFT across different MLLMs.
. 특히 LLaVA-1.5 에서 가장 큰 이미지 성능 저하를 보였고, Qwen2.5-VL 이 상대적으로 안정적인 모습을 보였습니다.
이러한 Temporal Trap 에 대한 이론적 설명을 위해, 저자들은 Video-SFT 가 비디오 성능을 향상시키면서도 통일된 MLLMs 의 공간적 능력을 저하시킬 수 있는 이유를 보수적인 이론적 모델로 제시합니다. 그들은 Video-SFT 가 L_vid 를 최적화하지만 L_img 를 직접 최적화하지 않으며, 비디오 기울기가 이미지 기울기와 음의 정렬(negatively aligned)될 때 이미지 손실이 증가할 수 있음을 보입니다. 또한, Temporal Budget (m) 의 증가가 기울기 편향의 원천이 되어 공유 파라미터 공간에서 정렬을 협력적에서 충돌적으로 변화시킬 수 있음을 설명합니다.
이러한 분석을 바탕으로, 저자들은 Temporal Trap 을 완화하기 위한 instruction-aware Hybrid-Frame Strategy 를 제안합니다 [Figure 1(D)]. 이 전략은 각 인스트럭션의 시공간적 요구에 따라 프레임 수를 적응적으로 할당하여 필요한 시간적 증거를 보존하면서 불필요한 시간적 노출을 피하는 것을 목표로 합니다. 실험 결과
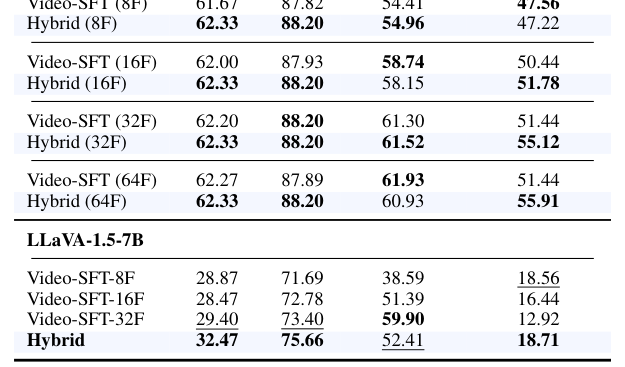 Table 2: Unified comparison of Video-SFT strategies across model architectures and frame budgets. For Qwen2.5-VL-7B, training and inference frame counts follow the settings in parentheses, while LLaVA-1.5-7B are evaluated with a fixed 8-frame inference.
Table 2: Unified comparison of Video-SFT strategies across model architectures and frame budgets. For Qwen2.5-VL-7B, training and inference frame counts follow the settings in parentheses, while LLaVA-1.5-7B are evaluated with a fixed 8-frame inference.
, Hybrid-Frame Strategy 는 Qwen2.5-VL-7B 모델에서 MMStar 정확도 62.33% (vs. Video-SFT(8F)의 61.67% ) 및 POPE 정확도 88.20% (vs. Video-SFT(8F)의 87.82% )를 달성하여 이미지 벤치마크에서 가장 높은 정확도를 보였습니다. 동시에 비디오 성능에서도 Video-MME 54.96% 로 강력한 이득을 유지했습니다. 이는 고정된 대규모 프레임 예산(예: 32 또는 64 프레임)으로 학습된 모델보다 이미지 작업에서 우수한 성능을 보였으며, LLaVA-1.5-7B 와 같은 다른 아키텍처에도 효과적임을 입증하여, 적응형 프레임 할당이 image-video trade-off 를 줄이는 데 널리 유용한 메커니즘임을 시사합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MLLMs 에서 Video-SFT 가 시각적 능력에 미치는 영향을 체계적으로 분석했으며, 비디오 이해를 향상시키는 동시에 공간적 이해를 약화시키는 일관된 Temporal Trap 현상을 발견했습니다. 이러한 Trade-off 는 Temporal Budget 과 밀접하게 연관되어 있으며, 불필요하게 많은 프레임을 사용하는 것이 모델의 정적 시각 표현을 손상시킬 수 있음을 이론적 및 실험적으로 입증했습니다.
저자들이 제안한 instruction-aware Hybrid-Frame Strategy 는 이러한 Temporal Trap 을 부분적으로 완화하고 image-video trade-off 를 줄이는 효과적인 개입 방법임을 보여주었습니다. 이 연구는 현재 MLLMs 의 통합 훈련 파이프라인이 진정한 image-video synergy 를 아직 달성하지 못했음을 시사하며, Video-SFT 과정에서 공간적 이해를 보존하는 것이 공동 이미지-비디오 훈련의 핵심 과제임을 강조합니다. 이는 멀티모달 학습에서 모달리티 간의 충돌을 이해하고 해결하기 위한 중요한 통찰력을 제공하며, 향후 보다 효율적이고 효과적인 통합 시각-언어 모델 개발에 기여할 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
- [논문리뷰] World Models Meet Language Models: On the Complementarity of Concrete and Abstract Reasoning
- [논문리뷰] ESARBench: A Benchmark for Agentic UAV Embodied Search and Rescue
- [논문리뷰] ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
- [논문리뷰] Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
Review 의 다른글
- 이전글 [논문리뷰] Stereo World Model: Camera-Guided Stereo Video Generation
- 현재글 : [논문리뷰] Temporal Gains, Spatial Costs: Revisiting Video Fine-Tuning in Multimodal Large Language Models
- 다음글 [논문리뷰] Unified Spatio-Temporal Token Scoring for Efficient Video VLMs
댓글