[논문리뷰] ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
링크: 논문 PDF로 바로 열기
저자: Huanxuan Liao, Zhongtao Jiang, Yupu Hao, Yuqiao Tan, Shizhu He, Jun Zhao, Kun Xu, Kang Liu, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Input-side Adaptation : 시각적 인코딩 이전에 입력 프레임의 해상도나 프레임 선택을 조정하여 모델의 연산 비용을 최적화하는 기법입니다.
- CAPO (Cost-Aware Policy Optimization) : sparse한 rollout 피드백을 안정적인 정확도-비용 학습 신호로 변환하여 Allocator를 학습시키는 방법론입니다.
- Allocator : 입력된 비디오의 각 프레임에 대해 시각적 중요도를 예측하고, 이를 바탕으로 최적의 시각적 예산(visual budget)을 할당하는 경량화된 모듈입니다.
- Retention Ratio (R) : 전체 비디오 입력 대비 인코딩된 시각적 토큰의 비율을 의미하며, 추론 효율성을 평가하는 핵심 지표입니다.
- MLLM Backbone : ResAdapt 프레임워크가 수정 없이 그대로 사용하는 기존의 Multimodal Large Language Models를 지칭합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
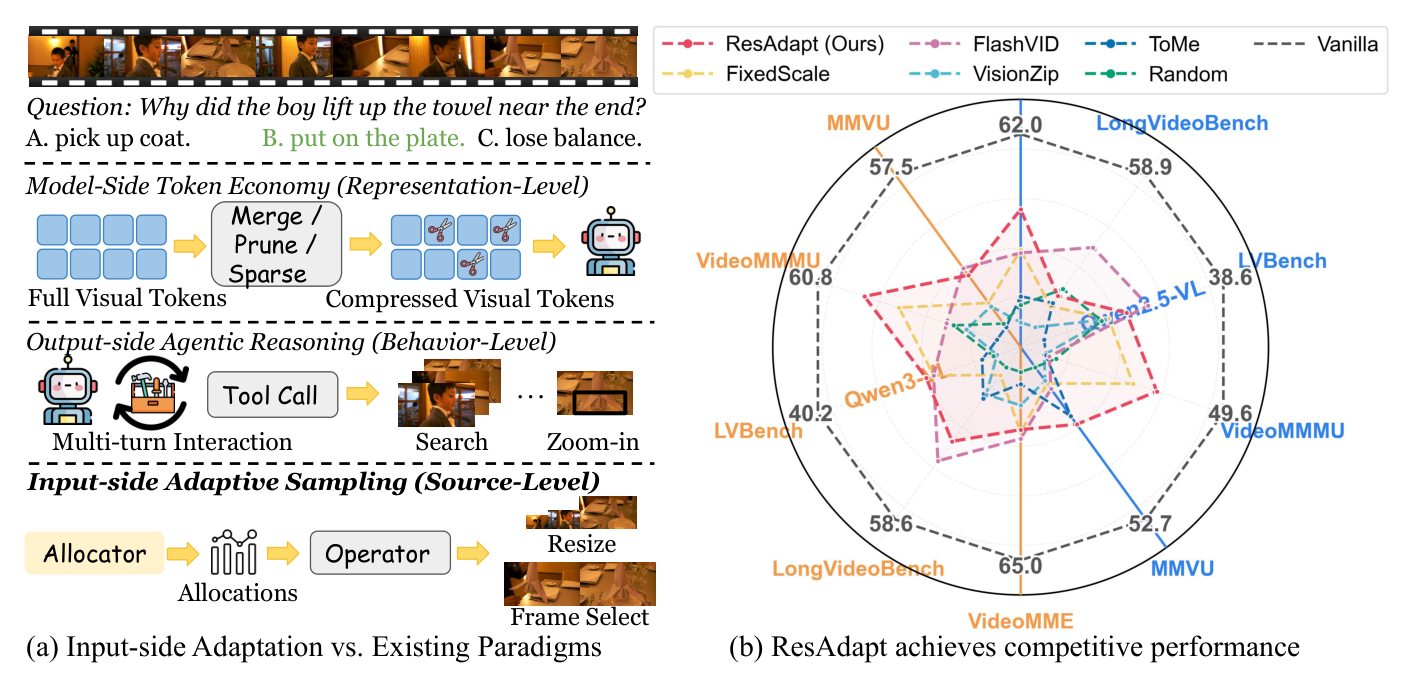
최근의 MLLMs 는 입력 정보의 정밀도(fidelity)를 높여 성능을 향상시키지만, 이는 과도한 visual token의 증가로 이어져 고해상도와 긴 시간적 맥락(long temporal context)을 동시에 유지하는 것을 불가능하게 만듭니다. 기존 연구들은 인코딩 이후 모델 내부에서 토큰을 압축하는 Model-side 전략이나, 반복적인 호출로 시각적 정보를 획득하는 Output-side 전략을 사용하지만, 이는 정보 손실이나 지연 시간 문제를 유발합니다. 저자들은 bottleneck이 인코딩 후 표현 압축이 아니라 인코더가 받는 초기 픽셀 볼륨에 있다고 판단했습니다. 이를 해결하기 위해 입력 단계에서부터 최적의 시각적 예산을 동적으로 할당하는 ResAdapt 를 제안합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
ResAdapt 는 Allocator 라는 경량 모듈을 통해 각 프레임의 중요도를 평가하고, 사전에 정의된 연산자(bilinear resize 등)를 적용하여 MLLM Backbone 으로 전달합니다. CAPO 는 Lagrangian relaxation을 확장하여, 정확도와 비용의 trade-off를 최적화하면서도 정책이 최소 비용으로 붕괴(collapse)하지 않도록 안정적인 학습 신호를 제공합니다. 또한, temporal-similarity regularizer를 도입하여 인접한 프레임들 간의 중복된 고비용 할당을 억제합니다.
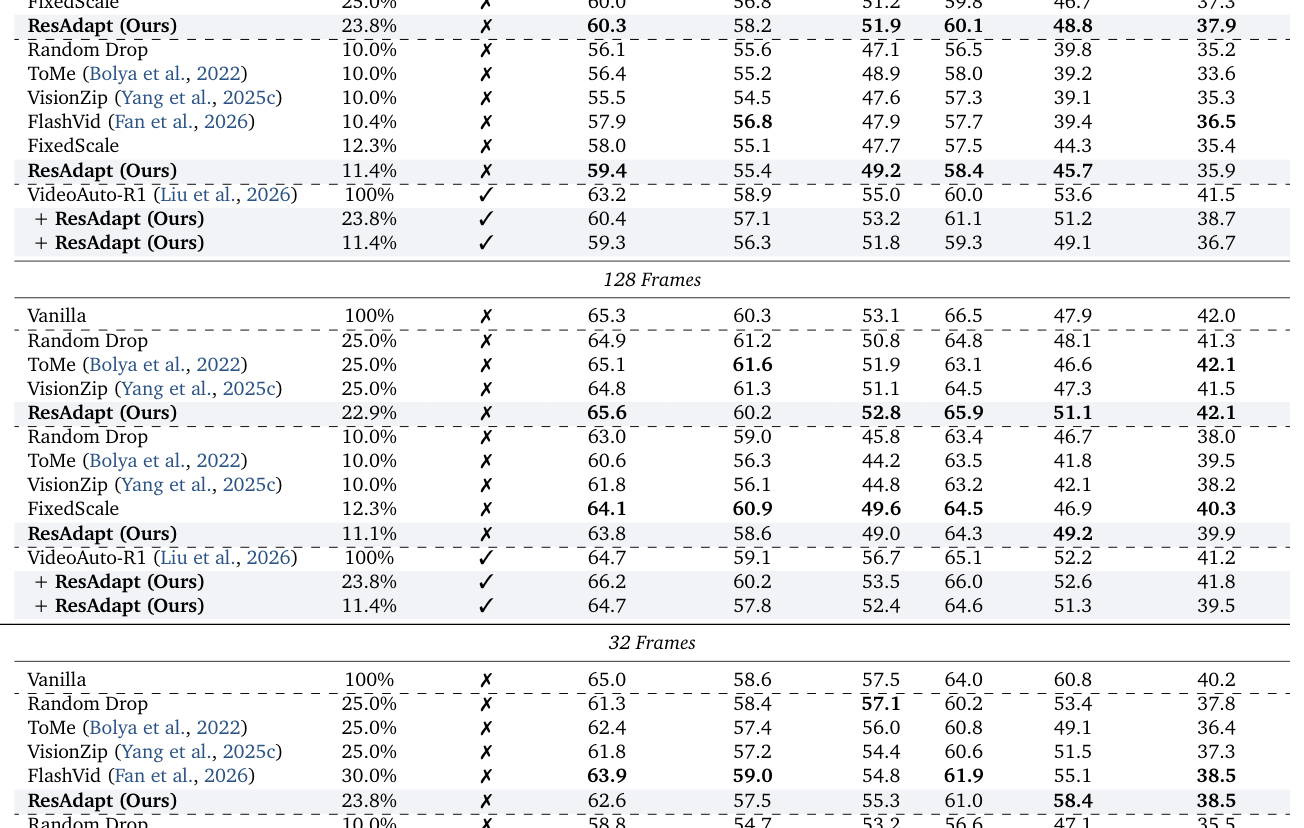
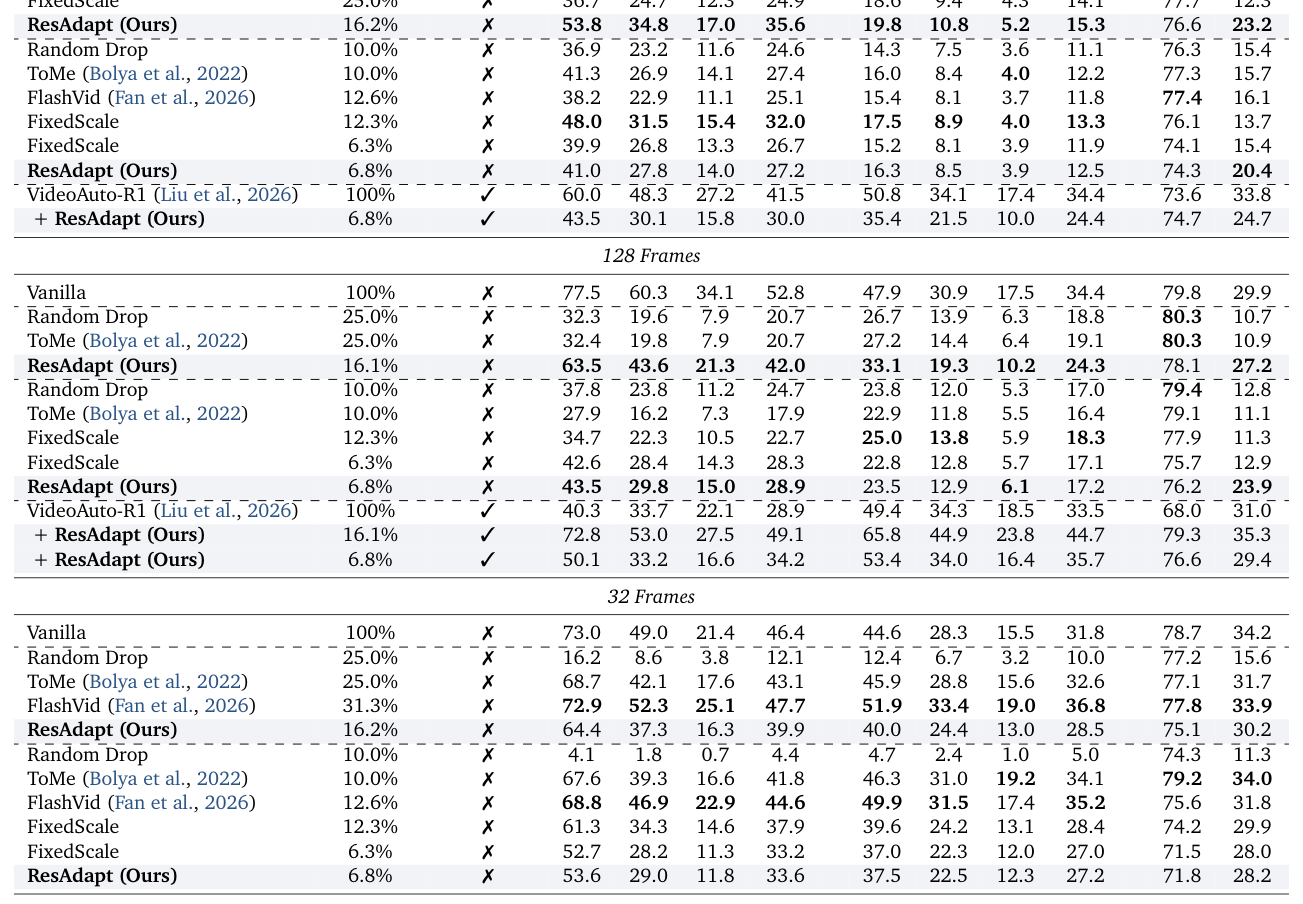
에서 볼 수 있듯, ResAdapt 는 32 frames 및 128 frames 설정에서 기존의 Random Drop , ToMe , VisionZip 보다 뛰어난 efficiency–accuracy Pareto frontier를 보여줍니다. 특히, 16배 더 많은 프레임을 처리하면서도 15% 이상의 성능 향상을 기록했습니다. 이는 고정된 해상도보다 훨씬 효율적으로 시각적 예산을 재배분하여 중요한 순간에 집중하는 open-loop active perception 을 가능하게 합니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 입력 단계에서의 동적 해상도 할당이 MLLMs 의 효율성을 확보하는 데 매우 효과적인 전략임을 입증했습니다. 특히, 제안된 CAPO 와 temporal-similarity regularization은 손으로 설계한 휴리스틱 없이도 모델이 콘텐츠 중심적인 할당 정책을 학습할 수 있게 합니다. 이 연구는 긴 시간의 비디오를 다루는 영상 이해(video reasoning) 분야에서 연산 비용을 획기적으로 줄이면서도 추론 성능을 보존하는 실용적인 방법론을 제시했다는 점에 큰 의의가 있습니다. 향후 시각적 정보가 제한된 상황에서의 더 정교한 적응형 할당이나 closed-loop으로의 확장은 영상 이해 모델의 차세대 표준이 될 것으로 기대됩니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] One Forward Beats Two: InnerZoom for Accurate and Efficient GUI Grounding
- [논문리뷰] Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
- [논문리뷰] ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
- [논문리뷰] OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
- [논문리뷰] Light-WAM: Efficient World Action Models with State-Fusion Action Decoding
Review 의 다른글
- 이전글 [논문리뷰] PRBench: End-to-end Paper Reproduction in Physics Research
- 현재글 : [논문리뷰] ResAdapt: Adaptive Resolution for Efficient Multimodal Reasoning
- 다음글 [논문리뷰] SEAR: Schema-Based Evaluation and Routing for LLM Gateways
댓글