[논문리뷰] Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
링크: 논문 PDF로 바로 열기
저자: Jiacheng Hua, Yishu Yin, Yuhang Wu, Tai Wang, Yifei Huang, Miao Liu et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Large Language Models (MLLMs) : 텍스트와 비전과 같은 여러 모달리티를 동시에 처리하고 추론할 수 있는 대규모 언어 모델입니다.
- Spatial Reasoning : 3D 환경과 객체 간의 관계를 이해하고 추론하는 능력입니다.
- Allocentric Context : 관찰자의 위치와 독립적으로 공간을 표현하는 방식, 즉 장면의 전반적인 레이아웃이나 글로벌 맵과 같은 개념을 의미합니다.
- Egocentric Video : 사용자 또는 에이전트의 관점에서 촬영되어 그들의 직접적인 시야를 보여주는 비디오 입력입니다.
- TRACE (Textual Representation of Allocentric Context from Egocentric Video) : MLLM이 3D 환경에 대한 텍스트 기반 표현을 중간 추론 trace로 생성하도록 유도하여 공간 질문 응답 성능을 향상시키는 프롬프트 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
기존의 Multimodal Large Language Models (MLLMs)는 2D 시각 신호에 과도하게 고정되어 3D 환경에 대한 구조화된 추상화를 구축하지 못함으로써 3D 공간 추론(spatial reasoning)에서 어려움을 겪습니다. 이러한 MLLM은 방대한 비디오 데이터셋으로 사전 학습되었음에도 불구하고, 장면의 3D 계층적 추상화 대신 2D 사전 학습에서 파생된 shortcut correlation에 의존하는 경향이 있습니다. 기존 연구들은 공간 추론 QA를 위한 대규모 supervised fine-tuning 데이터 큐레이션이나 MLLM에 기하학적 또는 스테레오 모달리티를 통합하는 방향으로 진행되었으나, 이는 확장성 및 일반화 제한, 시스템 복잡성 증가 등의 한계점을 가집니다. 이에 본 연구는 2D egocentric video observation으로부터 3D 공간 환경의 구조화된 allocentric representation을 명시적으로 구축하고 추론하도록 MLLM을 안내하는 방법을 모색하며, 이를 통해 기존 MLLM의 공간 추론 능력을 향상시키고자 합니다.
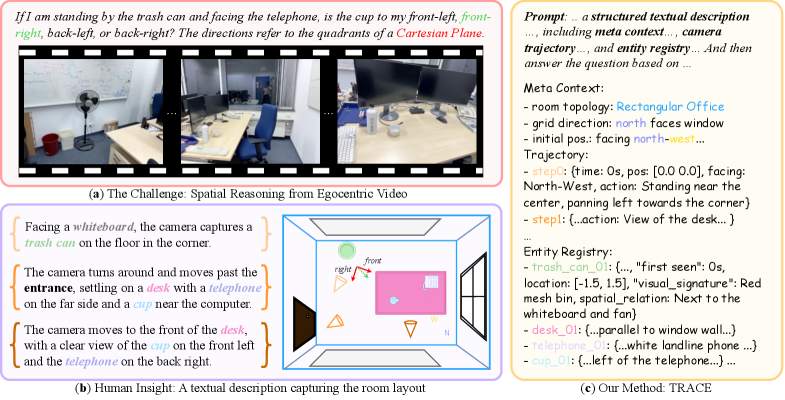
은 egocentric video와 holistic spatial reasoning이 필요한 질문을 보여주며, TRACE를 통해 메타 컨텍스트, 카메라 궤적 및 엔티티 정보를 인코딩하여 MLLM의 공간 QA를 위한 중간 추론 trace로 활용하는 동기를 설명합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 연구는 MLLM이 egocentric video 입력으로부터 3D 환경의 텍스트 기반 allocentric representation을 생성하도록 유도하는 프롬프트 방법론인 TRACE (Textual Representation of Allocentric Context from Egocentric Video) 를 제안합니다. TRACE는 인간의 인지 과정에서 영감을 받아 3D 장면의 글로벌 표현을 명시적으로 추론하도록 MLLM을 유도합니다. 제안된 TRACE는 구조화된 디자인을 채택하며, Meta Context , Camera Trajectory , 그리고 Entity Registry 의 세 가지 핵심 구성 요소로 이루어진 튜플(G = <M, T, E>)로 정의됩니다.
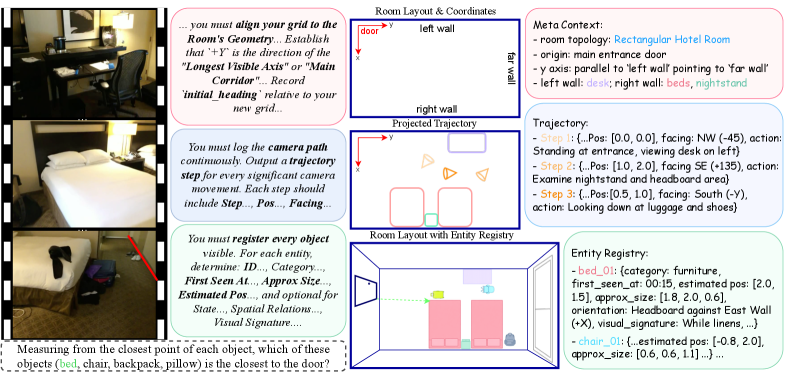
는 TRACE의 구체적인 구성 요소를 시각적으로 보여줍니다.
- Meta Context : 방 레이아웃과 좌표계를 정렬하는
Room Aligned Coordinate System을 포함하며, 관찰자의 초기 heading을 설정합니다. - Camera Trajectory : 설정된 좌표계를 사용하여 관찰자의 경로를 시간 단계별로
[x,y]위치와 카메라의facing방향(예: Cardinal Directions)을 기록한 이산적인 sequence로 재구성합니다. - Entity Registry : 시간 순서에 따라 관찰된 객체(
entities)에 대한 상세한 속성을 유지합니다. 여기에는Temporal Stamping,Visual Signature,Metric Estimation([x,y]미터 단위 좌표), 자연어 기반Spatial Relations, 그리고Strict Serialization이 포함됩니다. TRACE의 추론 메커니즘은 단일 패스로 수행되며, MLLM이 질문에 대한 최종 응답 전에schema-compliant representation G를 명시적으로 생성하도록 조건화합니다. 이는Chain-of-Thought의 한 형태로,G는 환경에 대한 "spatial cache"로 context window를 채우고, 최종 답변은TRACE조건부 추론을 통해 생성됩니다.
실험은 VSI-Bench와 OST-Bench 두 가지 공간 지능 벤치마크에서 수행되었습니다. TRACE는 Gemini 3 Pro, Qwen2.5-VL-72B-Instruct, MiMo-VL-7B-SFT, o3, GLM-4.5V 등 다양한 MLLM 백본에서 기존 프롬프트 전략(Direct, CoT, ToT, LtM, CM) 대비 일관되고 주목할 만한 성능 향상을 보였습니다. 특히, VSI-Bench에서는 Gemini에서 +7.54% , Qwen에서 +3.10% , MiMo에서 +1.63% 의 성능 향상을 달성했습니다. OST-Bench에서도 Gemini에서 +1.2% , MiMo에서 +2.4% 의 절대적인 성능 향상을 기록했습니다. [Table 1], [Table 2]는 이러한 정량적 결과를 자세히 보여줍니다.
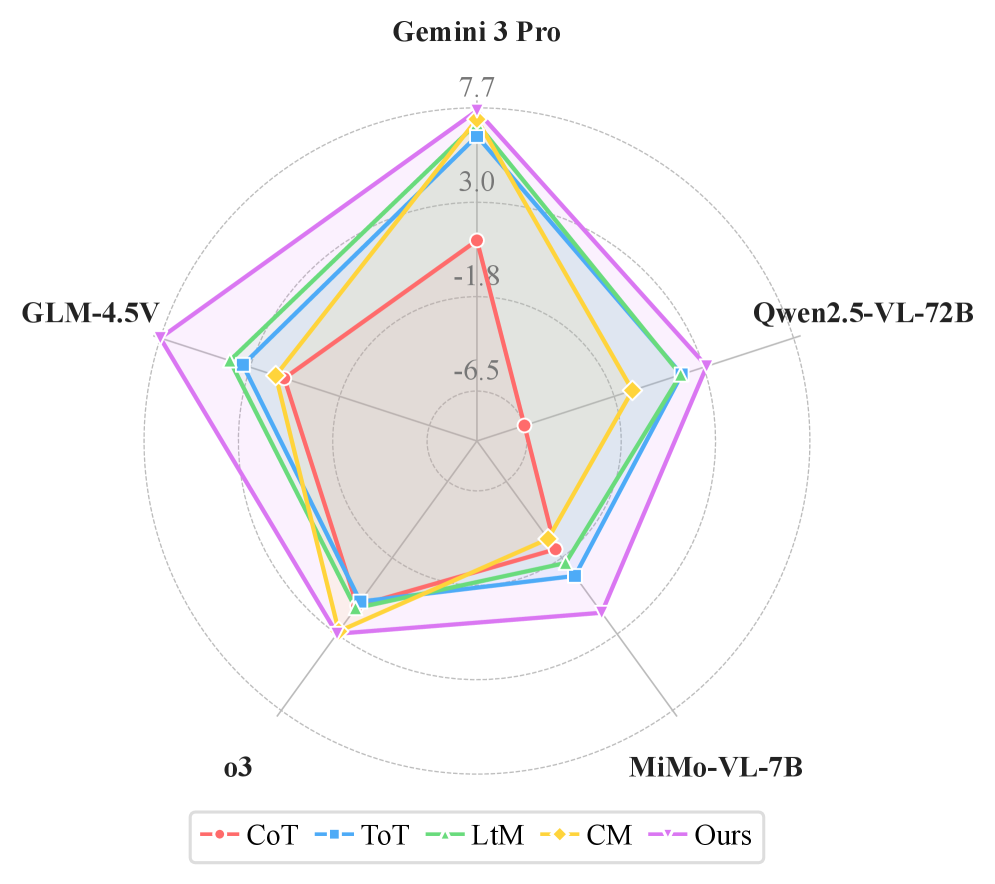
은 VSI-Bench에서 TRACE가 다양한 모델 아키텍처 및 파라미터 스케일에 걸쳐 일관된 SOTA 성능 향상을 제공함을 시각적으로 보여줍니다. Ablation study 결과, Camera Trajectory와 Entity Registry가 모두 중요한 역할을 하며, 특히 Entity Registry 제거 시 5.24% 의 더 큰 성능 하락을 보였습니다. One-Stage Inference가 Two-Stage 및 Text-Only inference보다 우수한 성능을 보여, TRACE 생성 과정 자체의 추론 효과를 입증했습니다. 또한, TRACE는 Text-Only Inference 설정에서 Cognitive Map보다 9.7% , Spatial Caption보다 3.53% 더 높은 성능을 기록했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 MLLM이 Textual Representation of Allocentric Context from Egocentric Video를 중간 추론 trace로 활용하여 공간 이해 능력을 향상시키는 프롬프트 접근 방식인 TRACE를 제안했습니다. TRACE는 meta-context, camera trajectory, 그리고 entity-level grounding을 통해 장면 구조를 명시적으로 모델링함으로써, 다양한 proprietary 및 open-source 모델 백본에서 VSI-Bench 및 OST-Bench 모두에서 일관된 성능 향상을 입증했습니다. 기존 linguistic prompting methods 및 다른 텍스트 기반 공간 표현과의 비교, 그리고 상세한 ablation study는 제안된 디자인 선택의 효과를 검증했습니다. 이 연구는 텍스트 기반 표현을 효과적으로 활용하는 방법과 MLLM 공간 추론의 병목 현상을 밝히는 decompositional analysis에 대한 통찰력을 제공합니다. 궁극적으로 TRACE는 off-the-shelf MLLM에서 구조화된 공간 추론을 연구하기 위한 간단하고 광범위하게 적용 가능한 인터페이스 역할을 할 것이며, MLLM의 공간 추론 발전을 위한 유망한 방향을 제시하고 인지적으로 영감을 받은 표현에 대한 추가 탐구를 장려합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
- [논문리뷰] COOPER: A Unified Model for Cooperative Perception and Reasoning in Spatial Intelligence
- [논문리뷰] MentalThink: Shaping Thoughts in Mental SVG World
- [논문리뷰] The Surprising Effectiveness of Video Diffusion Models for Hand Motion Reconstruction
- [논문리뷰] Thinking with Visual Grounding
Review 의 다른글
- 이전글 [논문리뷰] UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
- 현재글 : [논문리뷰] Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
- 다음글 [논문리뷰] When Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
댓글