[논문리뷰] When Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
링크: 논문 PDF로 바로 열기
The tool code will continue if there is any left. 저자: Zhengxian Wu, Kai Shi, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Unsupervised Self-Evolution : 사람의 주석이 달린 답변이나 외부 보상 모델 없이 모델 성능을 개선하는 훈련 프레임워크입니다.
- Actor : 주어진 입력에 대해 여러 추론 궤적(reasoning trajectories)을 생성하는 멀티모달 모델입니다.
- Judge : 현재 Actor 정책의 구조적으로 동일한 복사본으로, 각 추론 궤적에 대한 연속적인 품질 신호(score)를 제공하며 훈련 동안 파라미터가 고정됩니다.
- Self-Consistency : 동일한 입력에 대해 여러 추론 궤적을 샘플링했을 때, 결과 답변들의 경험적 빈도에서 도출되는 신호입니다.
- Group Relative Policy Optimization (GRPO) : 변조된 보상(modulated rewards)을 그룹 수준 분포로 모델링하여, 각 그룹 내에서 절대 점수를 상대적 이점(relative advantages)으로 변환함으로써 더욱 견고한 정책 업데이트를 가능하게 하는 최적화 전략입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 멀티모달 대규모 언어 모델(MLLMs)은 추론 작업에서 강력한 성능을 보여주었지만, 이러한 발전은 주로 고품질의 주석 처리된 데이터나 교사 모델(teacher-model) 증류(distillation)에 의존하고 있어 비용이 많이 들고 확장이 어렵습니다. 기존의 비지도 자기 진화(unsupervised self-evolution) 접근 방식, 특히 다수결 투표(majority voting)를 사용하는 방법은 노이즈가 많고 편향된 훈련 신호로 인해 문제가 발생합니다. 다수결 투표는 일관성이 있지만 잠재적으로 부정확한 답변을 강화하고, 이는 정책 붕괴(policy collapse)로 이어져 효과적인 탐색(exploration)을 억제할 수 있습니다

따라서 본 연구는 고비용의 인간 감독 없이 안정적이고 효과적인 멀티모달 추론 성능 향상을 달성하고, 자기 생성된 훈련 신호의 노이즈, 편향 및 모드 붕괴(mode collapse) 문제를 완화하는 것을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 멀티모달 대규모 모델을 위한 비지도 자기 진화 프레임워크를 제안합니다. 이 프레임워크는 단일 멀티모달 모델에서 Actor 와 Judge 두 가지 역할을 인스턴스화합니다
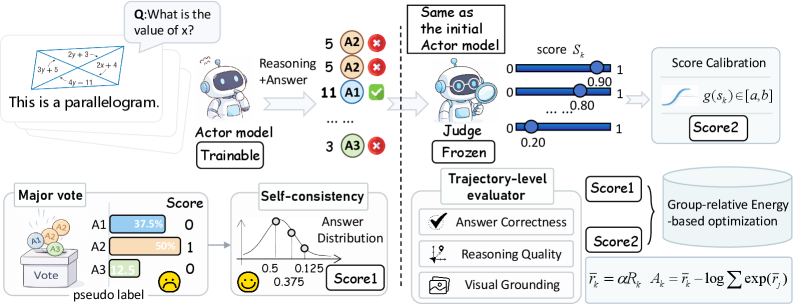
Actor 는 각 입력에 대해 여러 추론 궤적을 샘플링하며, 이 궤적들의 답변 빈도를 기반으로 초기 Self-Consistency Reward 를 할당합니다. 이후 고정된 Judge 모듈은 각 궤적에 대한 연속적이고 경계가 있으며 미분 가능한 변조(modulation) 신호를 제공하여 초기 보상을 보정합니다. 이 변조 기능은 시그모이드(sigmoid) 함수를 사용하여 높은/낮은 게이팅 임계값(gating thresholds)과 크기 제어를 통해 안정성을 보장합니다. 마지막으로, 변조된 보상에 Group Relative Policy Optimization (GRPO) 이 적용됩니다. 이는 보상을 그룹 단위 분포로 모델링하여, 절대 점수를 에너지 기반 스케일링(energy-based scaling)과 로그-합-지수(log-sum-exp) 기준선(baseline)을 통해 그룹 내 상대적 이점으로 변환합니다. 이 과정은 정책이 단일 모드로 급격히 붕괴하는 것을 방지하고, 더 나은 궤적으로 점진적으로 확률 질량(probability mass)을 재할당하도록 장려합니다.
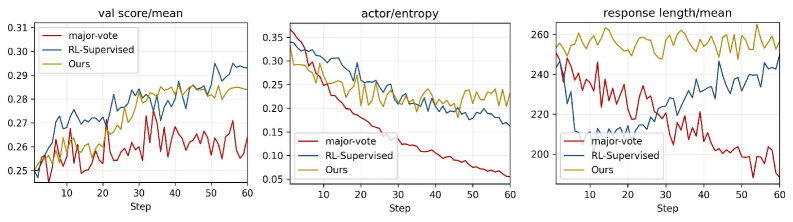
핵심 결과로, 제안된 방법은 MathVision , MathVerse , WeMath , LogicVista , DynaMath 등 5가지 수학 추론 벤치마크에서 추론 성능과 일반화 능력을 일관되게 향상시켰습니다. 특히, MathVision 에서 비지도 방식으로 Geo3K 데이터셋으로 훈련했을 때, 기존 모델 대비 정확도를 최대 5.9 절대 포인트 향상( 30.9% 대 25.0% )을 달성했습니다. 기존의 비지도 자기 진화 방법론들(예: VisionZero , EvoLMM , MM-UPT )과 비교하여, 본 연구의 접근 방식은 동일한 훈련 설정 하에서 일관되게 우수한 성능을 보였습니다. 예를 들어, MathVision 에서 MM-UPT 의 27.5% 또는 VisionZero 의 27.6% 대비 30.9% 의 정확도를 기록했습니다. 또한, 본 방법은 다수결 투표가 정책 엔트로피(policy entropy)를 급격히 감소시키는 것과 달리, Actor 엔트로피와 응답 길이 궤적(response-length trajectories)을 건강하게 유지함으로써 더 안정적인 훈련 동작을 보여줍니다
수학 추론 외에 ChartQA 및 MMVP 와 같은 비수학적, 시각 중심 작업에서도 일반화 능력을 입증했습니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 멀티모달 대규모 모델을 위한 비지도 자기 진화 훈련 프레임워크를 제안합니다. 이 방법은 동일한 입력에서 여러 추론 궤적을 공동으로 모델링함으로써, Actor의 Self-Consistency 신호와 Judge 기반 변조를 활용합니다. 나아가, 그룹 단위의 분포형 보상 모델링(group-wise distributional reward modeling)을 적용하여 장기 훈련 중 모드 붕괴(mode collapse)를 줄입니다. 여러 수학 추론 벤치마크에 대한 실험 결과는 제안된 접근 방식이 안정적인 성능 향상을 달성함을 보여줍니다. 이 연구는 고가의 인간 주석이나 외부 보상 모델에 대한 의존도를 크게 줄임으로써 자기 진화하는 멀티모달 모델을 향한 확장 가능한 경로를 제공합니다. 기존 비지도 방법의 한계점인 모드 붕괴 및 오류 패턴의 강화 문제를 해결하여 멀티모달 추론의 자기 개선에 있어 더욱 견고하고 효과적인 기여를 합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] PluraMath: Extending Mathematical Reasoning Evaluation Beyond High-Resource Languages
- [논문리뷰] OPRD: On-Policy Representation Distillation
- [논문리뷰] Off-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
- [논문리뷰] Joint Training of Multi-Token Prediction in Reinforcement Learning via Optimal Coefficient Calibration
- [논문리뷰] Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
- 현재글 : [논문리뷰] When Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
- 다음글 [논문리뷰] AVControl: Efficient Framework for Training Audio-Visual Controls
댓글