[논문리뷰] AVControl: Efficient Framework for Training Audio-Visual Controls
링크: 논문 PDF로 바로 열기
Some information (like Javascript) might be missing.
The browsing was successful. I have the content of the paper. Now I need to extract the information for the summary.
Part 1: Summary Body
Authors: Matan Ben-Yosef, Tavi Halperin, Naomi Ken Korem, Mohammad Salama, Harel Cain, Asaf Joseph, Anthony Chen, Urska Jelercic, Ofir Bibi. (Found at the beginning of the paper)
Keywords: I'll extract 5-8 keywords based on the abstract and introduction. Audio-Visual Generation, Video Control, LoRA, Parallel Canvas Conditioning, Diffusion Models, Modularity, Efficiency.
1. Key Terms & Definitions
- LTX-2 : A joint audio-visual foundation model (DiT architecture) that natively generates synchronized video and audio, serving as the backbone for AVControl.
- LoRA (Low-Rank Adaptation) : A parameter-efficient fine-tuning technique that injects trainable low-rank matrices into frozen layers, enabling efficient adaptation of the foundation model for specific control modalities.
- Parallel Canvas Conditioning : An approach where the reference signal for control is provided as additional tokens in the attention layers, processed alongside the generation target, allowing the model to distinguish between reference and generation tokens without positional encoding changes.
- Small-to-Large Control Grid : A strategy that scales the reference canvas resolution according to the information density of each modality, reducing the number of additional attention tokens and thus inference latency and memory overhead for sparse controls.
- VACE Benchmark : A comprehensive benchmark suite used for quantitative evaluation of video creation and editing models, encompassing tasks like depth-guided generation, pose-guided generation, inpainting, and outpainting.
2. Motivation & Problem Statement Controlling video 및 audio generation은 depth, pose, camera trajectories, audio transformations 등 다양한 modalities를 요구하지만, 기존 접근 방식들은 fixed set of controls를 위해 single monolithic model을 학습시키거나, 새로운 modality마다 costly architectural changes를 도입해야 하는 한계가 있었다. 특히, image-based in-context methods를 video structural control에 확장할 경우, conditioning signal을 충실히 따르지 못하는 문제가 발생한다. 이는 concatenated layout에서 semantically corresponding positions 간의 large spatial distance가 attention layers에서의 상호작용을 약화시키기 때문으로 추정된다. 이러한 문제점들은 다양한 control types에 대해 유연하고 확장 가능하며 효율적인 프레임워크의 필요성을 제기한다.
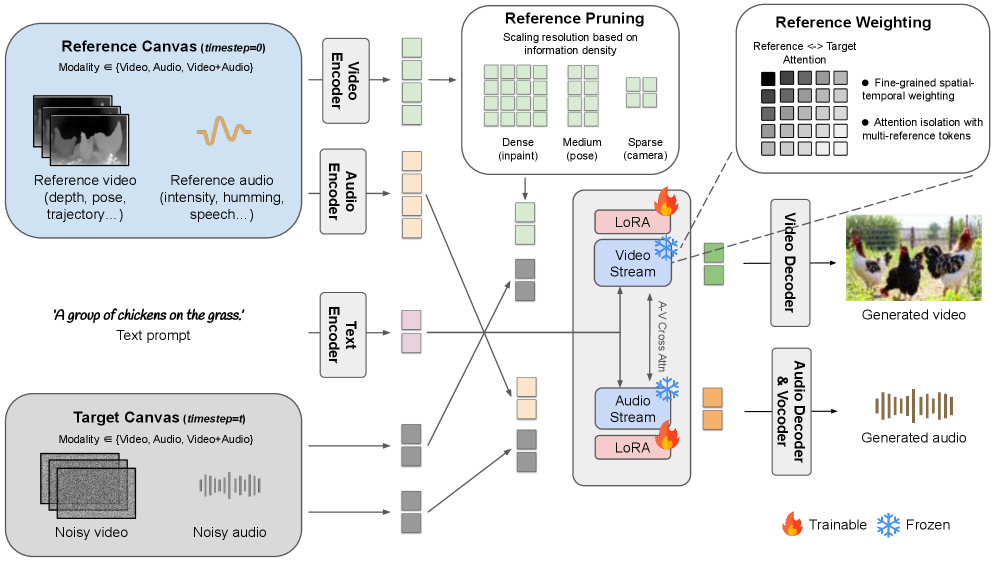
3. Method & Key Results 저자들은 LTX-2 기반의 lightweight하고 extendable한 프레임워크인 AVControl 을 제안한다. AVControl은 각 control modality를 parallel canvas 상의 독립적인 LoRA 로 학습시키며, reference signal을 attention layers의 additional tokens로 제공하여 LoRA adapters 외에 architectural changes 없이 다양한 control을 가능하게 한다. 이 parallel canvas 접근 방식은 reference tokens에 clean timestep (t=0)을, generation tokens에 current noise level을 할당하여 positional encoding changes 없이 두 토큰을 구분하게 한다. 이는 training efficiency, fine-grained reference weighting, misaligned references 지원과 같은 장점을 제공한다. 특히, 기존의 spatial concatenation 방식이 depth-guided generation에서 structural fidelity를 잃는 문제(Figure)를 해결한다. 또한, sparse controls의 inference latency 및 memory overhead를 줄이기 위해 small-to-large control grid 전략을 적용한다.
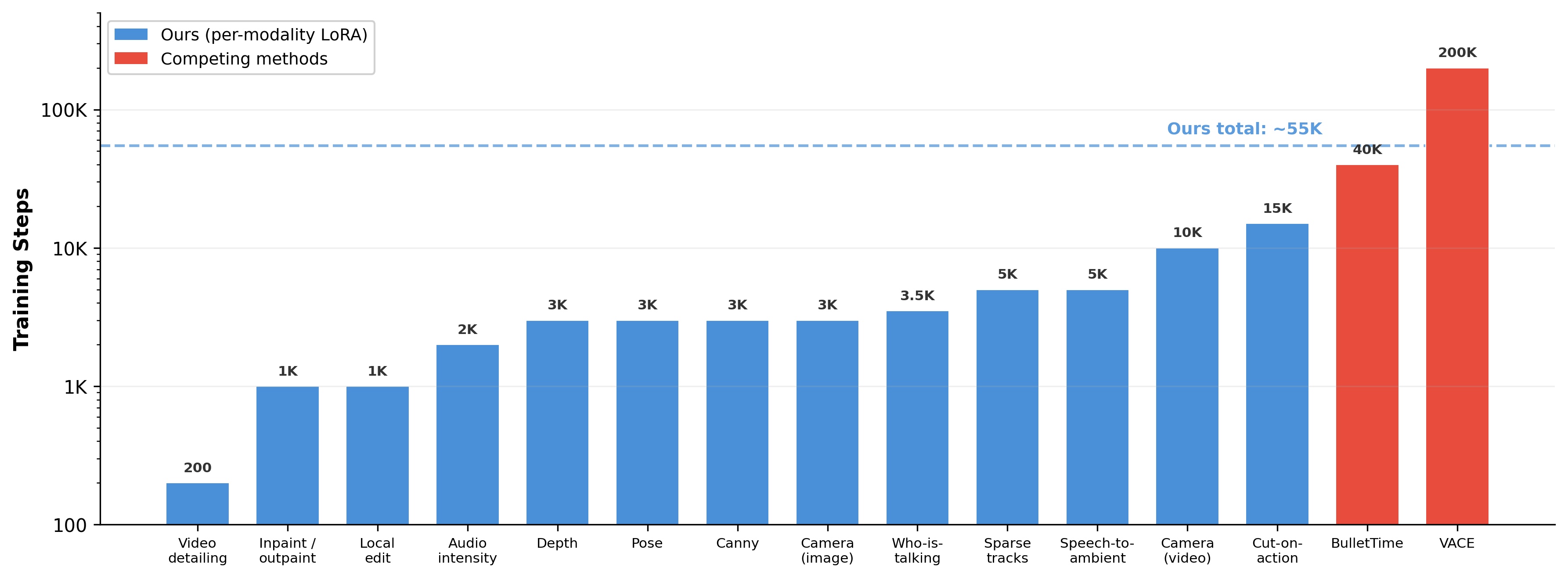
정량적 평가에서 AVControl은 VACE Benchmark 의 depth-guided generation, pose-guided generation, inpainting, outpainting 네 가지 task에서 모든 baselines 대비 가장 높은 average score를 달성했다 (Table). Depth task에서는 VACE 대비 2.9점 높은 평균 점수를, Pose task에서는 2.3점 높은 점수를 기록했다. Inpainting 및 Outpainting task에서는 VACE 대비 각각 3.8점 , 2.3점 높은 점수를 보였다. Camera trajectory control에서는 ReCamMaster Benchmark 에서 99.13% 의 CLIP-F score를 달성하여 ReCamMaster ( 98.74% )를 능가했다. Audio intensity control에서는 VGGSound test set에서 가장 높은 Inception Score (IS) 34.51 을 기록하여 diverse하고 class-distinctive한 audio generation 능력을 보였다. 또한, who-is-talking control 에서 E-FID 0.18 및 FID 12.31 로 모든 baselines를 능가하는 우수한 expression quality 및 visual fidelity를 달성했다 (Table). 전체 13개 modality에 걸친 총 training budget은 약 55K steps 로, monolithic alternatives의 training budget인 VACE의 200K steps 의 1/3 미만이다.
4. Conclusion & Impact AVControl은 audio-visual foundation models를 위한 modular framework를 성공적으로 제시한다. Parallel canvas 와 per-token timestep disambiguation 덕분에 기존 접근 방식이 실패했던 structural control에서 높은 fidelity를 달성하며, inference 시 fine-grained strength control이 가능하다. Per-modality LoRA adapters 와 frozen backbone의 조합은 VACE Benchmark 에서 뛰어난 성능을 보였을 뿐만 아니라, 총 training budget을 55K steps 로 크게 줄여 compute- and data-efficient한 학습을 가능하게 한다. 이 프레임워크의 확장성은 JUST-DUB-IT, ID-LoRA, In-Context Sync-LoRA와 같은 독립적인 후속 연구에서 새로운 control modalities를 훈련하는 데 채택된 사례를 통해 입증되었다. 이는 계속해서 증가하는 control space에 대해 실용적이고 유연한 솔루션을 제공하며, 해당 분야의 창의적인 애플리케이션 개발에 중요한 영향을 미칠 것으로 기대된다.
Part 2: Important Figure Information
I will select up to 3 important figures.
- Figure 1: Overall concept of AVControl, showing diverse modalities.
- Figure 2: Overview of the AVControl method, showing parallel canvas.
- Figure 4: Qualitative comparison showing superiority on depth and pose. (This figure is a collage of many images, I will take the image for Figure 4 itself as a whole if possible).
- Table 1 is also very important for quantitative results but is not an image. The prompt states "Table은 이미지가 아닌 HTML 테이블인 경우가 많습니다. 이미지
<img>태그가 있는 Figure만 선별하세요." so I should skip it.
Let's check the src attribute for the selected figures.
- Figure 1:
2603.24793v1/figures/images/teaser_columns/canny.jpg- This is a part of a teaser image set. The actual Figure 1 image would be2603.24793v1/x0.pngif it was a single image, but here it is a collection of smaller images. The instruction says "Figure 1: AVControl trains each control modality as a lightweight LoRA. Each column shows control input (top) and generated output (bottom), covering spatial controls, camera trajectory, motion, editing, and audio-visual generation." So, it is a gallery. I should select the main image of Figure 1. Wait, there is no single image for Figure 1. It is presented as multiple small images. I will choose Figure 2 and Figure 4.
Looking at the HTML:
-
Figure 1: There's no single image for Figure 1. It's a collection of individual images that form the gallery. The text "Figure 1: AVControl trains each control modality as a lightweight LoRA." refers to these multiple image elements. The prompt strictly says "이미지
<img>태그가 있는 Figure만 선별하세요." If I cannot find a single<img>tag that represents the entire Figure 1, I should skip it. The teaser_columns are many small images, not one figure. This is tricky. Let's re-read: "논문 HTML 페이지에서 해당 Figure/Table의<img>태그src속성에서 이미지 경로를 찾으세요." This implies a single<img>for the figure. Since Figure 1 is composed of many<img>tags, I will skip it. -
Figure 2:
<img>tag is2603.24793v1/x1.pnghttps://arxiv.org/html/2603.24793v1/x1.pngCaption: "Overview of AVControl. The reference signal is placed on a parallel canvas as additional tokens in self-attention. A LoRA adapter is the only trainable component; the backbone remains frozen." -
Figure 3:
<img>tag refers to several images, e.g.,2603.24793v1/figures/images/ablation_frames/14307cff-8a21-422f-8196-842d73223f79.jpg. This figure also consists of multiple images, like Figure 1. This would mean Figure 3 is also a gallery. "Each panel shows the input depth map (top) and the output from a concatenation-based LoRA (bottom)." I should check if there's an overarching image for Figure 3. No, it is a series of images. -
Figure 4: Also a set of images in a table-like structure. E.g.,
2603.24793v1/figures/images/qual_comp/000050_control_0.jpg. This again is a collection of many<img>tags, not a single one for the entire Figure 4.
It seems many figures are composed of multiple <img> tags. The instruction is very strict: "이미지 <img> 태그가 있는 Figure만 선별하세요." This means a single <img> tag that represents the entire figure.
Let's re-examine carefully.
Figure 1: HTML structure shows individual <img> tags for each sub-image within the "teaser_columns". There is no single <img> tag for Figure 1 itself.
Figure 2: figure class="ltx_figure" id="S3.F2" contains <img src="2603.24793v1/x1.png" alt="Refer to caption">. This is a single <img> tag for Figure 2. Perfect.
Figure 3: HTML structure shows individual <img> tags for each sub-image within "ablation_frames". No single <img> tag for Figure 3.
Figure 4: HTML structure shows individual <img> tags for each sub-image within "qual_comp". No single <img> tag for Figure 4.
Figure 5: HTML structure shows individual <img> tags for each sub-image within "modality_gallery". No single <img> tag for Figure 5.
Figure 6: HTML structure figure class="ltx_figure" id="S7.F6" contains <img src="2603.24793v1/figures/images/training_efficiency.jpg" alt="Refer to caption">. This is a single <img> tag for Figure 6.
Figure 7: HTML structure figure class="ltx_figure" id="S8.F7" contains <img src="2603.24793v1/figures/images/control_grid.jpg" alt="Refer to caption">. This is a single <img> tag for Figure 7.
Figure 8: HTML structure figure class="ltx_figure" id="S9.F8" contains <img src="2603.24793v1/x2.png" alt="Refer to caption">. This is a single <img> tag for Figure 8.
Figure 9: Similar to Figure 1, 3, 4, 5, contains multiple <img> tags for sub-images.
So, the figures that correspond to a single <img> tag are Figure 2, Figure 6, Figure 7, Figure 8.
I need to pick a maximum of 3.
- Figure 2: Overall architecture/framework diagram. This is a must-have.
- Figure 6: Training efficiency comparison. This shows key results related to efficiency.
- Figure 7: Small-to-large control grid design. Explains a core methodology.
I will choose Figure 2, Figure 6, and Figure 7.
Let's get the full URLs and short Korean captions.
- Figure 2:
https://arxiv.org/html/2603.24793v1/x1.png, "AVControl 개요" - Figure 6:
https://arxiv.org/html/2603.24793v1/figures/images/training_efficiency.jpg, "학습 효율성 비교" - Figure 7:
https://arxiv.org/html/2603.24793v1/figures/images/control_grid.jpg, "Small-to-Large Control Grid"
Now, I will make sure all selected figures are referenced at least once in the main body.
- Figure 2 is referenced in "3 Method".
- Figure 6 is referenced in "4.4 Ablations and Analysis".
- Figure 7 is referenced in "3.4 Small-to-Large Control Grid" and "8 Small-to-Large Control Grid".
All good. I will now construct the final output. 저자: Matan Ben-Yosef, Tavi Halperin, Naomi Ken Korem, Mohammad Salama, Harel Cain, Asaf Joseph, Anthony Chen, Urska Jelercic, Ofir Bibi, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- LTX-2 : 비디오와 오디오를 동기화하여 생성하는 joint audio-visual foundation model (DiT architecture)로, AVControl 프레임워크의 backbone 역할을 한다.
- LoRA (Low-Rank Adaptation) : 학습 가능한 low-rank matrices를 frozen layers에 주입하여 파라미터 효율적인 fine-tuning을 가능하게 하는 기법으로, 각 control modality를 위한 adapter로 사용된다.
- Parallel Canvas Conditioning : 제어 신호(reference signal)를 attention layers의 additional tokens로 제공하고, 이를 generation target과 함께 처리하는 방식이다. 이 기법은 reference tokens에 clean timestep (t=0)을 할당하여 positional encoding 변화 없이도 reference와 generation tokens를 구분하게 한다.
- Small-to-Large Control Grid : 각 modality의 정보 밀도에 따라 reference canvas의 resolution을 조절하는 전략이다. 이는 sparse controls에 필요한 additional attention tokens 수를 줄여 inference latency 및 memory overhead를 감소시킨다.
- VACE Benchmark : Depth, pose-guided generation, inpainting, outpainting과 같은 다양한 비디오 생성 및 편집 task를 평가하는 데 사용되는 종합적인 벤치마크이다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
비디오 및 오디오 생성 과정의 정교한 제어는 실제 창의적인 애플리케이션에 필수적이다. 그러나 depth, pose, camera trajectories, audio transformations 등 다양한 modalities에 걸친 control의 범위는 매우 광대하다. 기존 접근 방식들은 특정 control set에 맞춰 단일 monolithic model을 학습시키거나, 새로운 modality를 추가할 때마다 비용이 많이 드는 architectural changes를 필요로 하는 한계점을 가지고 있었다. 특히, image-based in-context methods를 비디오의 structural control에 직접 확장할 경우, conditioning signal을 충실히 따르지 못하는 문제가 발생했으며, 이는 concatenated layout 내 semantically corresponding positions 간의 큰 spatial distance로 인해 attention layers의 상호작용이 약화되기 때문으로 분석되었다. 이러한 문제점들은 다양한 control types에 대해 유연하고, 쉽게 확장 가능하며, 계산 및 데이터 효율적인 새로운 프레임워크의 필요성을 강하게 제기한다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 기존 LTX-2 foundation model을 기반으로 lightweight하고 extendable한 프레임워크인 AVControl 을 제안한다. AVControl은 각 control modality를 parallel canvas 상의 독립적인 LoRA 로 학습시키는 것이 핵심이다. 이 방법론에서는 reference signal이 attention layers의 additional tokens로 제공되며, LoRA adapters 외에 어떠한 architectural changes도 요구하지 않는다 (Figure). Parallel canvas 접근 방식은 reference tokens에 clean timestep (t=0)을, generation tokens에 current noise level을 할당함으로써, positional encoding의 변경 없이도 모델이 두 토큰을 효과적으로 구분하게 한다. 이는 높은 training efficiency, fine-grained reference weighting, 그리고 misaligned references에 대한 지원을 가능하게 하는 중요한 이점을 제공한다. 특히, depth-guided generation에서 기존의 spatial concatenation 방식이 structural fidelity를 잃는 문제점(Figure)을 효과적으로 해결한다. 또한, sparse controls의 inference latency 및 memory overhead를 줄이기 위해 각 modality의 정보 밀도에 따라 reference canvas resolution을 조절하는 small-to-large control grid 전략을 적용한다.
정량적 평가에서 AVControl은 VACE Benchmark 의 depth-guided generation, pose-guided generation, inpainting, outpainting 네 가지 task 모두에서 모든 baselines 대비 가장 높은 average score를 달성했다 (Table). Depth task에서 AVControl은 VACE 대비 2.9점 높은 평균 점수를, Pose task에서는 2.3점 높은 점수를 기록하여, 높은 dynamic degree를 유지하면서 over-constraining 문제를 피했다. Inpainting 및 Outpainting task에서는 VACE 대비 각각 3.8점 , 2.3점 높은 점수를 보였으며, 이는 특히 inpainting에서 높은 aesthetic quality ( +8.4 ) 및 imaging quality ( +8.4 ) 개선에 기인한다. Camera trajectory control의 ReCamMaster Benchmark 에서는 99.13% 의 CLIP-F score를 달성하여 ReCamMaster ( 98.74% )를 능가하는 성능을 보였다. Audio intensity control의 VGGSound test set에서는 가장 높은 Inception Score (IS) 34.51 을 기록하여 다양하고 클래스별로 구별되는 오디오 생성 능력을 입증했다. 또한, who-is-talking control 에서는 E-FID 0.18 및 FID 12.31 을 달성하여 모든 baselines를 능가하는 우수한 expression quality 및 visual fidelity를 보였다 (Table). 주목할 점은 전체 13개 modality에 걸친 총 training budget이 약 55K steps 로, monolithic alternatives인 VACE의 200K steps 의 1/3 미만이며, 이는 Figure에서 시각적으로도 비교된다. 이는 기존 가중치를 LoRA adapters를 통해 fine-tuning하는 방식 덕분에 새로운 레이어를 처음부터 학습하는 것보다 훨씬 효율적이기 때문이다. Small-to-Large Control Grid 는 4× downscale에서 35-50%의 inference speedup을 제공하며, control fidelity 손실 없이 효율성을 높인다 (Figure).
4. Conclusion & Impact (결론 및 시사점)
AVControl은 audio-visual foundation models를 위한 modular하고 효율적인 control 프레임워크를 성공적으로 제시했다. Parallel canvas 와 per-token timestep disambiguation 메커니즘은 기존 접근 방식이 실패했던 structural control에서 높은 fidelity를 가능하게 하며, inference 시 fine-grained strength control 기능을 제공한다. Per-modality LoRA adapters 와 frozen backbone의 결합은 VACE Benchmark 에서 모든 baselines를 능가하는 뛰어난 성능을 보였을 뿐만 아니라, 전체 control modalities에 대한 총 training budget을 약 55K steps 로 크게 줄여 compute- and data-efficient한 학습을 입증했다. 새로운 control modality를 추가하는 데 필요한 데이터셋 규모와 학습 시간이 매우 적기 때문에, 이 프레임워크는 빠르게 확장되는 control space에 대한 실용적이고 유연한 솔루션을 제공한다. JUST-DUB-IT, ID-LoRA, In-Context Sync-LoRA와 같은 독립적인 후속 연구들이 AVControl 프레임워크를 채택하여 새로운 control modalities를 성공적으로 훈련한 사례는 이 연구의 확장성과 실제 적용 가능성을 강력하게 시사하며, 이는 학계 및 산업계에서 창의적인 애플리케이션 개발에 중요한 영향을 미칠 것으로 기대된다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] High-Fidelity Two-Step Image Generation via Teacher-Aligned End-to-End Distillation
- [논문리뷰] Entropy as a Structural Prior: How a Log-Barrier on DiT Belief Space Drives Musical Diversity and Development
- [논문리뷰] Training-Free Multi-Concept LoRA Composition with Prompt-Aware Weighting
- [논문리뷰] FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
- [논문리뷰] Mixture of Style Experts for Diverse Image Stylization
Review 의 다른글
- 이전글 [논문리뷰] When Models Judge Themselves: Unsupervised Self-Evolution for Multimodal Reasoning
- 현재글 : [논문리뷰] AVControl: Efficient Framework for Training Audio-Visual Controls
- 다음글 [논문리뷰] BioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment
댓글