[논문리뷰] Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
링크: 논문 PDF로 바로 열기
The browsing was successful. I have the content of the paper. Now I need to extract the information and structure the output according to the given format.
Part 1: Summary
- Authors : Xianjin Wu, Dingkang Liang, Tianrui Feng, Kui Xia, Yumeng Zhang, Xiaofan Li, Xiao Tan, Xiang Bai
- Keywords : I'll pick 5-8 relevant technical terms from the abstract and introduction.
Video Generation Models3D PriorsScene UnderstandingSpatial ReasoningMultimodal Large Language Models (MLLMs)Latent World SimulatorAdaptive Gated FusionGenerative AI
- Key Terms & Definitions : I need to find 3-5 crucial terms and define them based on the paper.
- Spatial Blindness : MLLMs' struggle with fine-grained geometric reasoning and physical dynamics.
- Implicit 3D Priors : Video generation models' inherent understanding of 3D structure and physical laws, learned to synthesize temporally coherent videos, without explicit 3D supervision.
- VEGA-3D (Video Extracted Generative Awareness) : The proposed plug-and-play framework that repurposes a pre-trained video diffusion model as a Latent World Simulator to enrich MLLMs with dense geometric cues.
- Latent World Simulator : A pre-trained video diffusion model (e.g., Wan2.1) re-purposed to extract spatiotemporal features from intermediate noise levels, providing 3D world knowledge.
- Adaptive Gated Fusion : A token-level mechanism to integrate generative features with semantic representations, dynamically weighing the importance of each.
- Multi-view Correspondence Score : A metric introduced to quantitatively verify the correlation between multi-view feature consistency and 3D geometric capability, by measuring cosine similarity of feature vectors for the same 3D point across different views.
- Motivation & Problem Statement : What problem are they solving? What are the limitations of existing methods?
- MLLMs have strong semantic capabilities but suffer from "spatial blindness" for geometric reasoning.
- Existing solutions (explicit 3D modalities, geometric scaffolding) are limited by data scarcity and generalization.
- Video generation models implicitly learn 3D structural priors, which are underexplored for downstream 3D visual understanding.
- Method & Key Results : Explain the proposed method and key quantitative results.
- Methodology : VEGA-3D framework.
- Dual-branch visual encoding: Discriminative encoder (e.g., SigLIP) for high-level semantics and a generative video diffusion model (e.g., Wan2.1) as a Latent World Simulator for dense 3D structure priors.
- 3D Awareness via Multi-view Feature Consistency: Use Multi-view Correspondence Score to identify geometric capability, finding DiT-based models superior.
- Latent World Simulation: Perturb clean latent representations with noise (Flow Matching noising path) and extract features from intermediate DiT layers (e.g., k=300 , 20th DiT layer ) using an empty text prompt.
- Adaptive Gated Fusion: Projects generative and semantic features into LLM's hidden dimension, then uses a token-level gated mechanism to dynamically combine them, prioritizing semantic for recognition and generative for spatial reasoning.
- Key Results :
- 3D Scene Understanding : VEGA-3D consistently improves over Video-3D LLM baseline. For example, it boosts ScanRefer Acc@0.5 from 51.7 to 56.2 and SQA3D EM from 58.6 to 61.3 .
- Spatial Reasoning (VSI-Bench) : Augments Qwen2.5VL-7B baseline, achieving consistent gains across overall average and sub-categories.
- Robotic Manipulation (LIBERO) : Injects generative priors into OpenVLA-OFT , enhancing baseline performance with specific breakthroughs in complex object interactions and long-horizon tasks, achieving 97.3% average success rate.
- Ablation Studies : Performance peaks at intermediate noise levels (e.g., k=300 ). Intermediate DiT layers (e.g., 20th layer ) provide optimal abstraction. Adaptive Gated Fusion outperforms other fusion mechanisms. DiT-based generative models show significantly higher multi-view consistency than UNet-based models and traditional discriminative models.
- Methodology : VEGA-3D framework.
- Conclusion & Impact : Summarize the conclusion and impact.
- VEGA-3D effectively addresses spatial blindness in MLLMs by leveraging implicit 3D priors from video generation models.
- The framework offers a scalable, data-efficient paradigm for 3D spatial awareness, without explicit 3D supervision, suggesting future advances in 3D understanding can stem from generative foundations.
- Impact: Provides a new direction for grounding MLLMs in physical world understanding, potentially reducing reliance on costly 3D datasets.
Part 2: Important Figure Information (JSON)
I need to select up to 3 important figures, get their URLs and write a short Korean caption. Looking at the figures in the paper:
- Figure 1: Comparison of existing paradigms. Good for motivation.
- Figure 2: Visualization of implicit 3D priors. Shows consistency and improved attention. Good for understanding the core idea.
- Figure 3: Feature Analysis. Shows complementarity and correlation. Also good.
- Figure 4: Overview of the VEGA-3D framework. This is the main architecture diagram, very important.
- Figure 5: Adaptive Gated Fusion. Explains a key component of the method.
- Figure 6: Ablation studies on noise injection and DiT depth. Shows experimental insights.
- Figure 7: Inference overhead. Shows a limitation.
- Figure 8-12: Qualitative comparisons and failure cases. Good for results but not as central as architecture or core concept figures.
I will choose:
- Figure 4: Overall framework.
- Figure 2: Visualization of implicit 3D priors and improved attention.
- Figure 1: Comparison of paradigms, setting the motivation.
Let's gather the URLs and write captions.
- Figure 1:
https://arxiv.org/html/2603.19235v1/x1.png- "기존 패러다임 비교" - Figure 2:
https://arxiv.org/html/2603.19235v1/x2.png- "내재적 3D Priors 시각화" - Figure 4:
https://arxiv.org/html/2603.19235v1/x4.png- "VEGA-3D 프레임워크 개요"
Now I will structure the response. 저자: Xianjin Wu, Dingkang Liang, Tianrui Feng, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Spatial Blindness : Multimodal Large Language Models (MLLMs)가 미세한 기하학적 추론(fine-grained geometric reasoning) 및 물리적 동역학(physical dynamics)에 어려움을 겪는 현상.
- Implicit 3D Priors : 비디오 생성 모델(video generation models)이 시간적으로 일관된 비디오를 합성하기 위해 명시적인 3D Supervision 없이 내재적으로 학습하는 견고한 3D 구조적 Prior 및 물리 법칙.
- VEGA-3D (Video Extracted Generative Awareness) : 사전 학습된 비디오 Diffusion 모델(pre-trained video diffusion model)을 Latent World Simulator로 재활용하여 MLLM을 Dense geometric cue로 강화하는 Plug-and-play 프레임워크.
- Latent World Simulator : 비디오 Diffusion 모델의 중간 Noise Level에서 시공간 특징(spatiotemporal features)을 추출하여 3D World Knowledge를 제공하도록 재활용된 구성 요소.
- Adaptive Gated Fusion : 생성 특징(generative features)과 Semantic Representation을 Token-level에서 동적으로 통합하여 각 정보의 중요도를 조절하는 메커니즘.
- Multi-view Correspondence Score : 3D Scene에서 동일한 물리적 3D Point가 서로 다른 View에서 얼마나 일관된 Latent Representation을 유지하는지를 측정하는 지표로, 3D 기하학적 Capability와 Downstream 성능 간의 Correlation을 정량적으로 평가하는 데 사용됨.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
최근 Multimodal Large Language Models (MLLMs)는 인상적인 Semantic Capability를 보여주지만, Fine-grained geometric reasoning 및 Physical dynamics와 관련된 "Spatial blindness" 문제를 겪고 있습니다. 기존 연구들은 Explicit 3D Modality(예: Point cloud, Depth)를 직접 사용하거나, 2D Feature를 3D 공간으로 Lifting하기 위한 복잡한 Geometric scaffolding (예: Reconstruction, Distillation)에 의존합니다. 이러한 접근 방식들은 데이터 희소성(data scarcity)과 일반화(generalization)의 한계에 직면합니다.
저자들은 대규모 비디오 생성 모델(large-scale video generation models)이 시간적으로 일관된 비디오를 합성하기 위해 Implicit 3D structural priors 및 Physical laws를 내재적으로 학습한다는 점에 주목합니다. 이러한 Implicit physical priors가 3D Visual Understanding 성능을 향상시키는 데 활용될 수 있는지에 대한 연구 질문을 제기하며, 기존 Explicit한 3D 의존적 패러다임의 한계를 극복하고 새로운 접근 방식이 필요함을 강조합니다
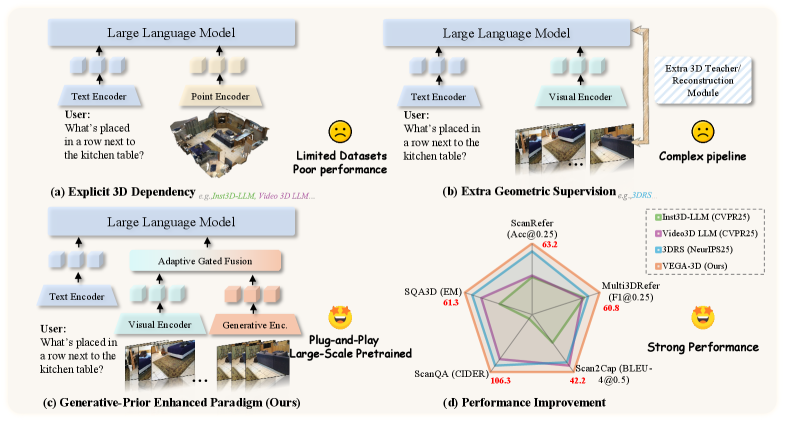
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 MLLM에 비디오 생성 모델의 내재된 Generative prior를 부여하기 위해 VEGA-3D 라는 Plug-and-play 프레임워크를 제안합니다. 이 프레임워크는 Discriminative encoder (예: SigLIP )의 High-level semantic capability와 Generative video diffusion model (예: Wan2.1 )의 Dense 3D structural prior를 결합하는 Dual-branch visual encoding 메커니즘을 사용합니다
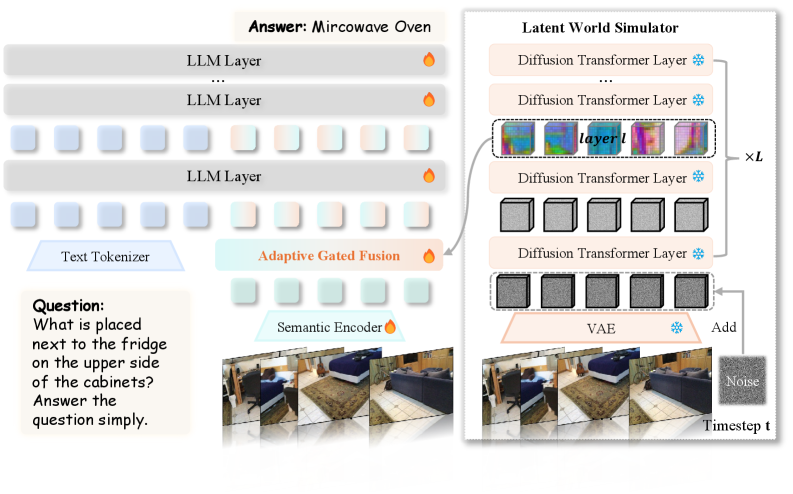
VEGA-3D 의 방법론은 세 가지 주요 단계로 구성됩니다. 첫째, 3D Awareness via Multi-view Feature Consistency 분석을 통해 Multi-view feature consistency가 기하학적 Capability의 핵심 지표임을 확인하고, 이를 정량화하기 위한 Multi-view Correspondence Score 를 도입합니다. 이 분석은 DiT-based 아키텍처(예: Wan2.1 )가 UNet-based 모델보다 훨씬 높은 Consistency score (예: >96% )를 보여주며, 더 우수한 Downstream 3D understanding을 달성함을 입증합니다. 둘째, Video Generative Model as a Latent World Simulator 로 사전 학습된 Wan2.1-T2V 1.3B 모델을 활용합니다. 정적인 Latent representation 대신, Flow Matching noising path를 따라 Clean latent를 교란하고, Empty text prompt를 사용하여 중간 DiT layer (기본적으로 20번째 Layer 에서 k=300 의 Noise Level)에서 Feature를 추출하여 Implicit 3D Knowledge를 활성화합니다. 셋째, Bridging the Generative and Semantic Gap 을 위해 Adaptive Gated Fusion 메커니즘을 설계합니다 [Figure 5]. 이 모듈은 Generative Feature와 Semantic Feature를 LLM의 Hidden dimension으로 Projection한 후, Token-level Gating mechanism을 통해 동적으로 통합하여, 인식 작업에는 Semantic prior를, Spatial reasoning에는 Generative world knowledge를 우선시합니다.
실험 결과, VEGA-3D 는 다양한 벤치마크에서 SOTA Baseline을 능가하는 성능을 보여줍니다.
- 3D Scene Understanding : ScanRefer Acc@0.5 에서 Video-3D LLM Baseline의 51.7% 를 56.2% 로, SQA3D EM 에서 58.6% 를 61.3% 로 향상시키는 등 Localization-centric Task에서 특히 강세를 보였습니다 [Table 1].
- Spatial Reasoning : VSI-Bench 에서 Qwen2.5VL-7B Baseline 대비 Overall average 및 여러 Sub-category에서 일관된 성능 향상을 달성했습니다 [Table 2].
- Robotic Manipulation : LIBERO 벤치마크에서 OpenVLA-OFT Baseline의 97.0% Average success rate를 97.3% 로 소폭 향상시키며, Complex object interaction 및 Long-horizon task에서 탁월한 robustness를 입증했습니다 [Table 3].
- Ablation Studies : Generative prior가 Diffusion process의 Intermediate Noise Levels (예: k=300 )와 Intermediate DiT layers (예: 20번째 Layer )에서 가장 효과적이며, Adaptive Gated Fusion 이 다른 Fusion 메커니즘보다 우수함을 확인했습니다 [Figure 6].
이러한 결과는 대규모 비디오 생성 모델이 Temporal synthesis를 통해 견고한 3D World Model을 내재화했음을 강력히 시사하며, VEGA-3D 가 Explicit 3D Annotation 없이도 MLLM에 Dense geometric cue를 효과적으로 주입할 수 있음을 보여줍니다.
4. Conclusion & Impact (결론 및 시사점)
본 연구는 현대 비디오 생성 모델을 Latent World Simulator로 재활용하는 VEGA-3D 프레임워크를 제안하여 MLLM의 Spatial blindness 문제를 해결합니다. Noise injection을 통해 Implicit 3D priors를 활성화하고 Adaptive Gated Fusion을 통해 Semantic token과 정렬함으로써, VEGA-3D 는 MLLM에 Dense geometric anchor를 주입하며, 추가적인 3D Supervision 없이도 Scene understanding, Spatial reasoning, Manipulation 성능을 일관되게 향상시킵니다.
이 연구는 해당 분야에 두 가지 중요한 시사점을 제공합니다. 첫째, 대규모 비디오 생성 모델의 Latent physical priors가 MLLM의 3D Spatial awareness를 위한 확장 가능한(scalable) 기반을 제공하며, 3D 관련 데이터 희소성 병목 현상을 우회할 수 있음을 보여줍니다. 둘째, 3D Spatial awareness의 다음 Frontier는 더 많은 3D 데이터가 아닌, Generative foundation 모델 내부에 잠재된 Latent physical priors를 활용하는 데 있을 수 있음을 제안합니다. 이는 학계 및 산업계에서 3D Understanding 시스템 개발의 새로운 패러다임을 제시하며, 비용이 많이 드는 3D 데이터셋 구축의 필요성을 줄일 수 있는 잠재력을 가집니다.

⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
- [논문리뷰] COOPER: A Unified Model for Cooperative Perception and Reasoning in Spatial Intelligence
- [논문리뷰] RiddleBench: A New Generative Reasoning Benchmark for LLMs
- [논문리뷰] LTD-Bench: Evaluating Large Language Models by Letting Them Draw
- [논문리뷰] Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Review 의 다른글
- 이전글 [논문리뷰] FASTER: Rethinking Real-Time Flow VLAs
- 현재글 : [논문리뷰] Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
- 다음글 [논문리뷰] Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
댓글