[논문리뷰] Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
링크: 논문 PDF로 바로 열기
Here's the summary of the paper "Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models" based on the browsed content.
Part 1: 요약 본문
저자: Kevin Qu, Haozhe Qi, Mihai Dusmanu, Mahdi Rad, Rui Wang, Marc Pollefeys
1. Key Terms & Definitions (핵심 용어 및 정의)
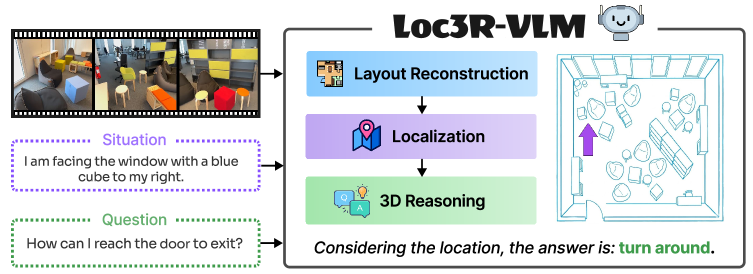
- Vision-Language Model (VLM) : 2D 이미지와 언어 간의 연결에 특화된 모델로, 본 논문에서는 여기에 3D 공간 이해 능력을 부여하는 것을 목표로 합니다.
- Language-based Localization : 자연어 상황 설명을 기반으로 에이전트의 3D 공간 내 위치(Position)와 방향(Orientation)을 추론하는 태스크입니다.
- Global Layout Reconstruction : 영상 프레임들을 Bird’s-Eye-View (BEV) 공간으로 통합하여 장면의 전역적인 구조와 객체 배치, 시점 간 공간 관계를 파악하는 객관식 학습입니다.
- Situation Modeling : 에이전트의 위치(
토큰)와 방향( 토큰)을 명시적으로 표현하고 추론하여, 주어진 상황 설명으로부터 스스로를 장면 내에 정위시키고 시점(viewpoint)을 인지하는 추론을 가능하게 하는 메커니즘입니다. - Camera Pose Prior : 사전에 훈련된 3D Foundation Model인 CUT3R 에서 추출한 Latent 카메라 토큰으로, 모노큘러 비디오의 스케일 모호성을 완화하고 VLM이 Metric space에서 Localization을 수행하도록 돕는 기하학적 단서입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal Large Language Models (MLLMs)는 Vision과 Language를 연결하는 데 상당한 발전을 이루었지만, 공간 이해와 시점 인지(viewpoint-aware) 추론 능력은 여전히 부족합니다. 기존 연구들은 3D Ground-truth 데이터에 대한 의존성이나, Global scene understanding 및 Situational awareness를 명시적으로 학습하지 않고 단순한 부산물로 취급하는 한계점을 가집니다. 특히, MLLMs는 여러 프레임의 관측값을 통합하여 일관된 Global context를 형성하는 데 어려움을 겪으며, 카메라의 Ego-centric view를 넘어서는 시점 독립적인 공간 관계를 추론하지 못하는 경향이 있습니다. 이러한 한계는 로봇 공학이나 자율 주행과 같은 분야에서 안전한 탐색 및 의사 결정에 필수적인 상황 이해를 저해합니다. 본 논문은 이러한 한계를 극복하고, 2D VLM이 모노큘러 비디오 입력만으로도 고급 3D 이해 능력을 갖추도록 하는 것을 목표로 합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
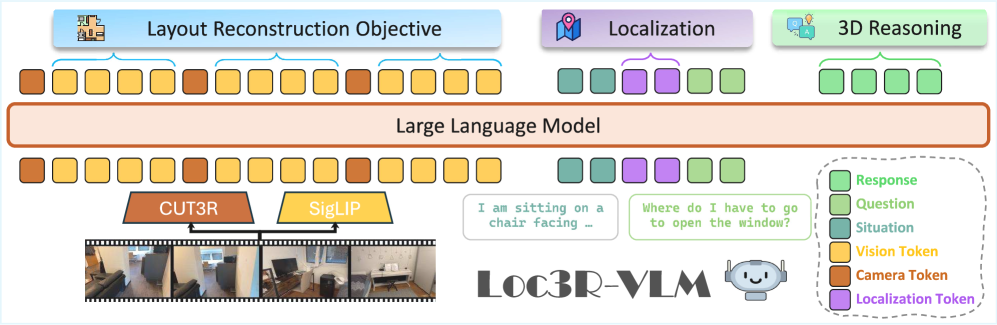
저자들은 2D VLM에 고급 3D 이해 능력과 Situational awareness를 부여하기 위해 인간의 인지에서 영감을 받은 Loc3R-VLM 프레임워크를 제안합니다. 이 프레임워크는 모노큘러 비디오를 입력으로 받아, Pre-trained 3D Foundation Model인 CUT3R 에서 추출한 프레임별 Latent camera pose prior를 활용합니다 [Figure 2, cite: 1].
Loc3R-VLM은 세 가지 핵심 구성 요소로 이루어져 있습니다:
- Integration of Camera Pose Priors : CUT3R 에서 추출된 Latent camera token을 VLM의 Vision token sequence에 추가하여, 모노큘러 비디오의 본질적인 스케일 모호성을 완화하고 Metric space에서의 Localization을 지원합니다.
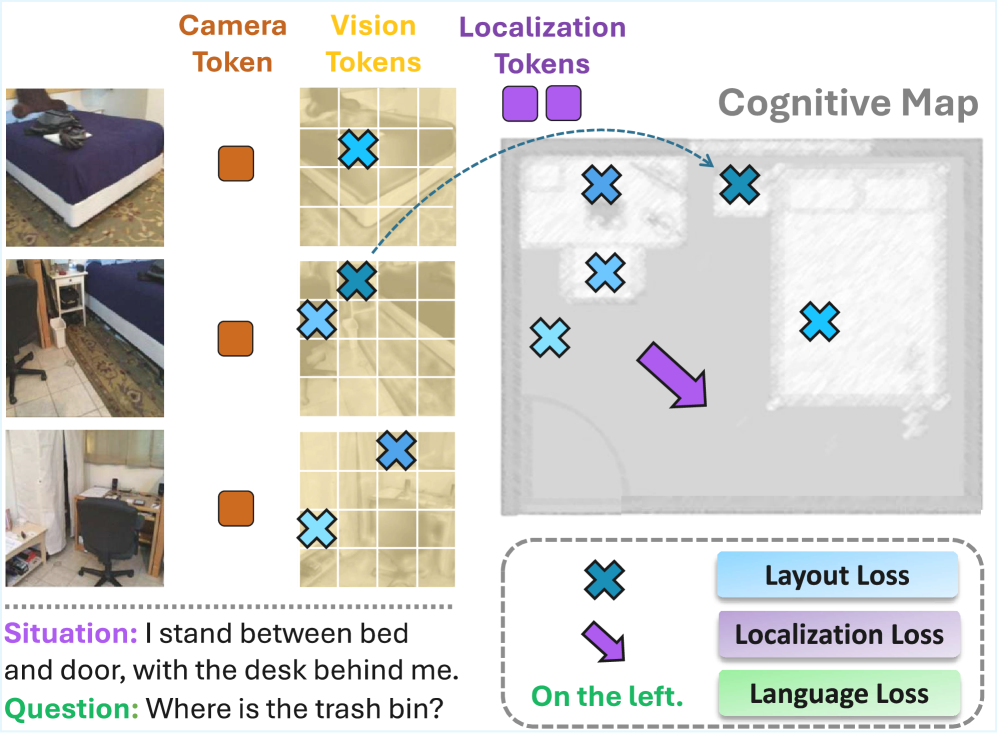
- Global Layout Reconstruction : 보조 학습 목표로, Vision patch token을 Bird’s-Eye-View (BEV) 공간에 매핑하여 장면의 Global scene structure를 형성하고, 여러 프레임의 관측을 일관된 Global context로 통합합니다 [Figure 3, cite: 1]. 이 과정에서 Gaussian negative log-likelihood (GNLL) loss를 사용하여 BEV Position과 Uncertainty를 추정합니다.
- Situation Modeling :
와 라는 전용 토큰을 도입하여 에이전트의 Position과 Orientation을 명시적으로 예측합니다. Position은 GNLL loss로, Orientation은 KL-divergence loss로 감독되며, 이 두 objective는 Joint situation objective로 결합됩니다. 이 모듈은 상황 설명으로부터 에이전트를 Localization하고 Viewpoint-aware 추론을 수행하도록 훈련합니다 [Figure 3, cite: 1].
이 모든 구성 요소는 LLaVA-Video-7B 를 기반으로 한 Joint training objective (ℒtotal = ℒCE + λBEVℒBEV + λsitℒsit)를 통해 End-to-end로 최적화됩니다. 훈련 시에는 데이터셋에서 제공하는 Depth와 Camera pose를 사용하여 Ground-truth BEV 좌표를 계산하지만, 추론 시에는 원시 모노큘러 비디오만 필요하며 3D 주석은 필요 없습니다.
실험 결과, Loc3R-VLM은 Language-based localization 벤치마크인 SQA3D 에서 기존 Point-cloud 기반 방법론들을 크게 능가했습니다 [Table 1, cite: 1]. 특히, View2Cap 대비 Position estimation에서 Acc@0.5m 는 +25.2% , Acc@1.0m 는 +39.0% 향상되었고, Orientation prediction에서 Acc@15° 는 +14.3% , Acc@30° 는 +34.5% 향상되었습니다 [Table 1, cite: 1]. 3D Question Answering 벤치마크인 VSI-Bench 에서는 Relative Direction (+36.1%) , Relative Distance (+10.8%) , Route Planning (+8.8%) 과 같은 Viewpoint understanding이 필요한 태스크에서 가장 높은 성능을 달성했습니다 [Table 2, cite: 1]. ScanQA , SQA3D , MSQA , Beacon3D 등 다른 3D QA 벤치마크에서도 기존 2D MLLMs 및 대부분의 3D MLLMs를 뛰어넘는 State-of-the-art 성능을 보여주었습니다 [Table 3, Table 4, Table 5, cite: 1]. Ablation study는 Global layout reconstruction과 Situation modeling, Camera pose prior 각 구성 요소가 Localization 및 3D QA 성능 향상에 기여함을 입증했습니다 [Table 6, Table 7, cite: 1].
4. Conclusion & Impact (결론 및 시사점)
Loc3R-VLM은 2D VLM에 고급 3D 이해 능력을 부여하는 프레임워크로, 명시적인 공간 Supervision과 기하학적 Prior를 결합하여 모노큘러 비디오 입력만으로 Language-based localization 및 Spatial reasoning을 수행합니다. 인간 인지에서 영감을 받은 Global layout reconstruction과 Explicit situation modeling 모듈은 전역적인 장면 이해와 상황 인식을 동시에 강화하며, CUT3R 기반의 Camera pose prior는 Metric-scale 일관성을 보장합니다.
이 연구는 모델이 시각 정보를 전역적이고 시점 인지적인 표현으로 조직하도록 유도함으로써, 견고한 3D 이해가 비디오 입력으로부터 직접적으로 나타날 수 있음을 강조합니다. Loc3R-VLM은 Language-driven localization, Situated reasoning, General 3D question-answering 태스크에서 상당한 성능 향상을 달성하며, Strong spatial 및 Embodied understanding을 가진 3D-aware VLM 연구에 중요한 영향을 미칠 것으로 기대됩니다. 향후 연구는 Vertical granularity의 한계, Scene coverage의 확장, Dynamic scenes 및 Outdoor environments로의 적용 가능성을 탐색할 수 있습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Spatial-SSRL: Enhancing Spatial Understanding via Self-Supervised Reinforcement Learning
- [논문리뷰] Rank-Then-Act: Reward-Free Control from Frame-Order Progress
- [논문리뷰] Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
- [논문리뷰] DataComp-VLM: Improved Open Datasets for Vision-Language Models
- [논문리뷰] InstanceControl: Controllable Complex Image Generation without Instance Labeling
Review 의 다른글
- 이전글 [논문리뷰] Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
- 현재글 : [논문리뷰] Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
- 다음글 [논문리뷰] MOSS-TTS Technical Report
댓글