[논문리뷰] MOSS-TTS Technical Report
링크: 논문 PDF로 바로 열기
저자: Yitian Gong, Botian Jiang, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- MOSS-TTS : Discrete audio tokens, autoregressive modeling, 및 대규모 사전 학습을 기반으로 구축된 Speech Generation Foundation Model입니다.
- MOSS-Audio-Tokenizer : 24 kHz 오디오를 12.5 fps로 압축하고 Variable-Bitrate RVQ 및 Unified Semantic-Acoustic Representations를 지원하는 Causal Transformer 기반의 Discrete Audio Tokenizer입니다.
- RVQ (Residual Vector Quantization) :
MOSS-Audio-Tokenizer에서 Discrete Tokenization을 수행하는 32-Layer Residual Vector Quantizer 메커니즘으로, 가변 비트레이트 Tokenization을 가능하게 합니다. - Delay Pattern :
MOSS-TTS모델의 아키텍처 중 하나로, 단일 Transformer backbone과 RVQ-aware Delay Schedule를 사용하여 Structural Simplicity, Scalability, 그리고 Long-Context Deployment에 중점을 둡니다. - Local Transformer :
MOSS-TTS모델의 또 다른 아키텍처로, Frame-Local Autoregressive Module을 도입하여 Modeling Efficiency를 높이고 Speaker Preservation을 강화하며, First Audio까지의 시간을 단축합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Text-to-Speech (TTS)는 이제 Foundation Model처럼 동작하며, 다양한 화자, 언어, 스타일, 음향 조건에 걸쳐 Generalize하고, Controllable하며 Low-Latency Synthesis를 지원하며, Long-Form 콘텐츠에 대해 Stable해야 하는 Speech Generation의 광범위한 패러다임으로 진화하고 있습니다. 기존 연구들은 종종 Multiple Intermediate Targets, External Semantic Teachers, Refinement Stages 또는 Post-Hoc Alignment에 의존하여 이러한 요구사항을 해결했지만, 각 추가 모듈이 새로운 Supervision Contract, Failure Modes 및 Latency Budgets를 도입하여 Scaling을 복잡하게 만들었습니다. 저자들은 충분히 유능한 Tokenizer가 Speech Generation을 단일하고 Universal Modeling Objective를 가진 Token Prediction 문제로 전환함으로써 데이터, Compute 및 Downstream Capabilities Scaling을 더 쉽게 만들 수 있다고 주장합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 Discrete Tokens + AR Modeling + Large-Scale Pretraining의 Scalable Recipe를 기반으로 MOSS-TTS 를 제안합니다. 핵심 방법론은 다음과 같습니다:
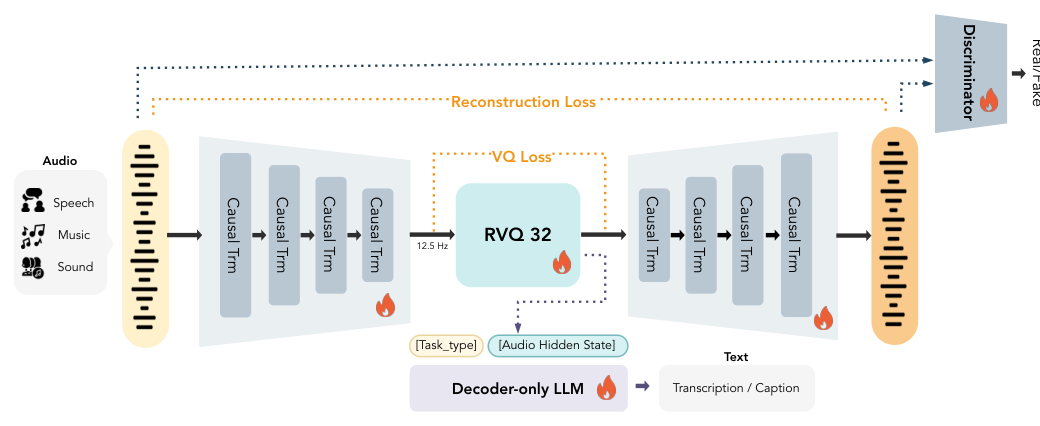
- MOSS-Audio-Tokenizer : 24 kHz 오디오를 12.5 fps로 압축하는 Causal Transformer 기반 Discrete Tokenizer로, Variable-Bitrate RVQ를 지원하고 Unified Semantic-Acoustic Representations를 사용합니다. Semantic Reconstruction과 Acoustic Alignment를 End-to-End로 최적화하며, 0.5B Decoder-Only LLM으로 ASR, Multi-Speaker ASR, Audio Captioning 등 Audio-to-Text Semantic Supervision을 수행하고, Multi-Period Discriminator 및 STFT Discriminator를 사용하여 Perceptual Quality를 향상시킵니다
- Large-Scale, High-Quality Pretraining Data : Millions of hours에 달하는 Raw Open-Domain Recordings를 Multi-Stage Data Pipeline (Preprocessing, Filtering, Data Synthesis)을 통해 Curated Trainable Single-Speaker Assets로 변환합니다 [Figure 3].
- Refined Discrete-Token Modeling : 두 가지 Autoregressive (AR) 아키텍처를 탐구합니다.
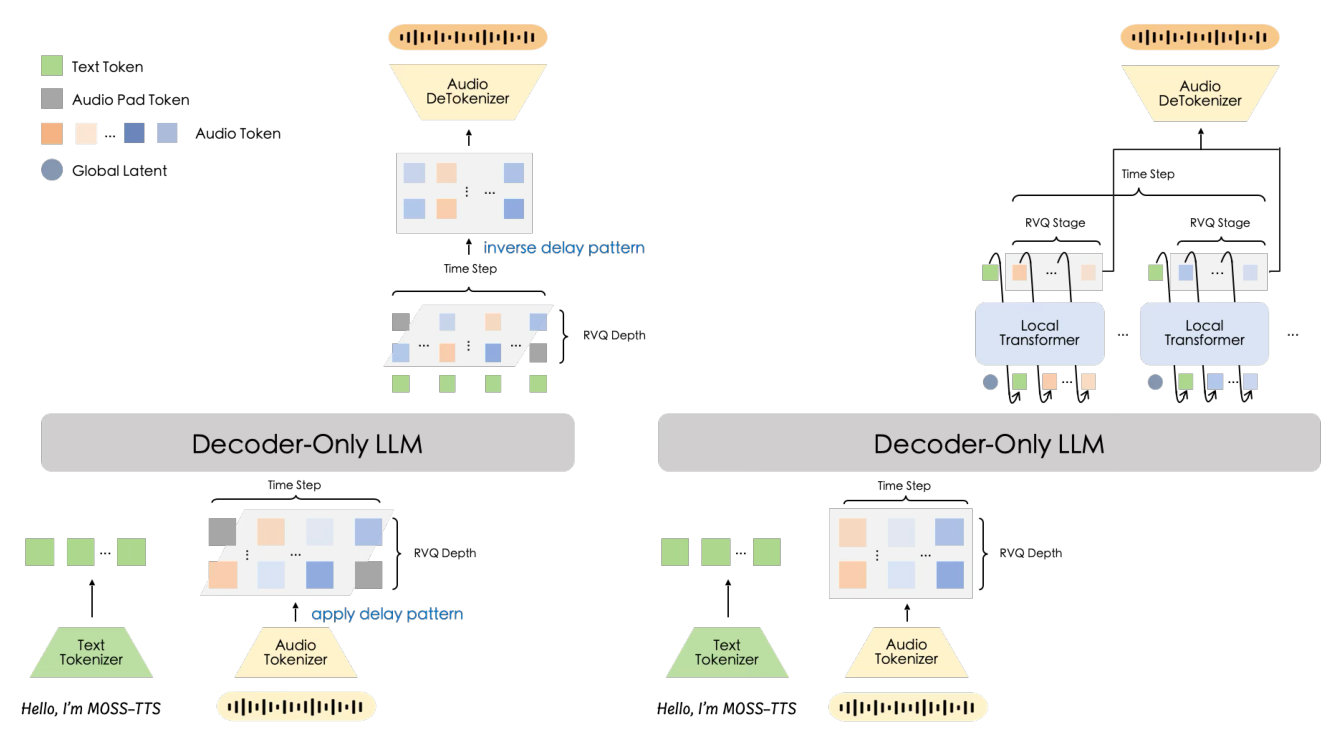
- MOSS-TTS (Delay Pattern) : 단일 Transformer backbone을 사용하여 Structural Simplicity, Scalability, Long-Context Deployment에 중점을 둡니다 [Figure 2, 왼쪽].
- MOSS-TTS-Local-Transformer : Frame-Local Autoregressive Module을 추가하여 Modeling Efficiency를 높이고 Speaker Preservation을 강화합니다 [Figure 2, 오른쪽].
- 사전 학습은 Warmup-Stable-Decay (WSD) 패턴의 4단계 학습 스케줄 [Table 1]을 따릅니다.
핵심 결과:
- Audio Tokenizer 성능 : MOSS-Audio-Tokenizer 는 LibriSpeech test-clean (English) 및 AISHELL-2 (Chinese)에서 테스트한 결과, 4000 bps 비트레이트에서 SIM 0.97/0.93 , STOI 0.97/0.96 를 달성하여 비교 Open-Source Baseline들을 일관되게 능가했습니다 [Table 2, Figure 5].
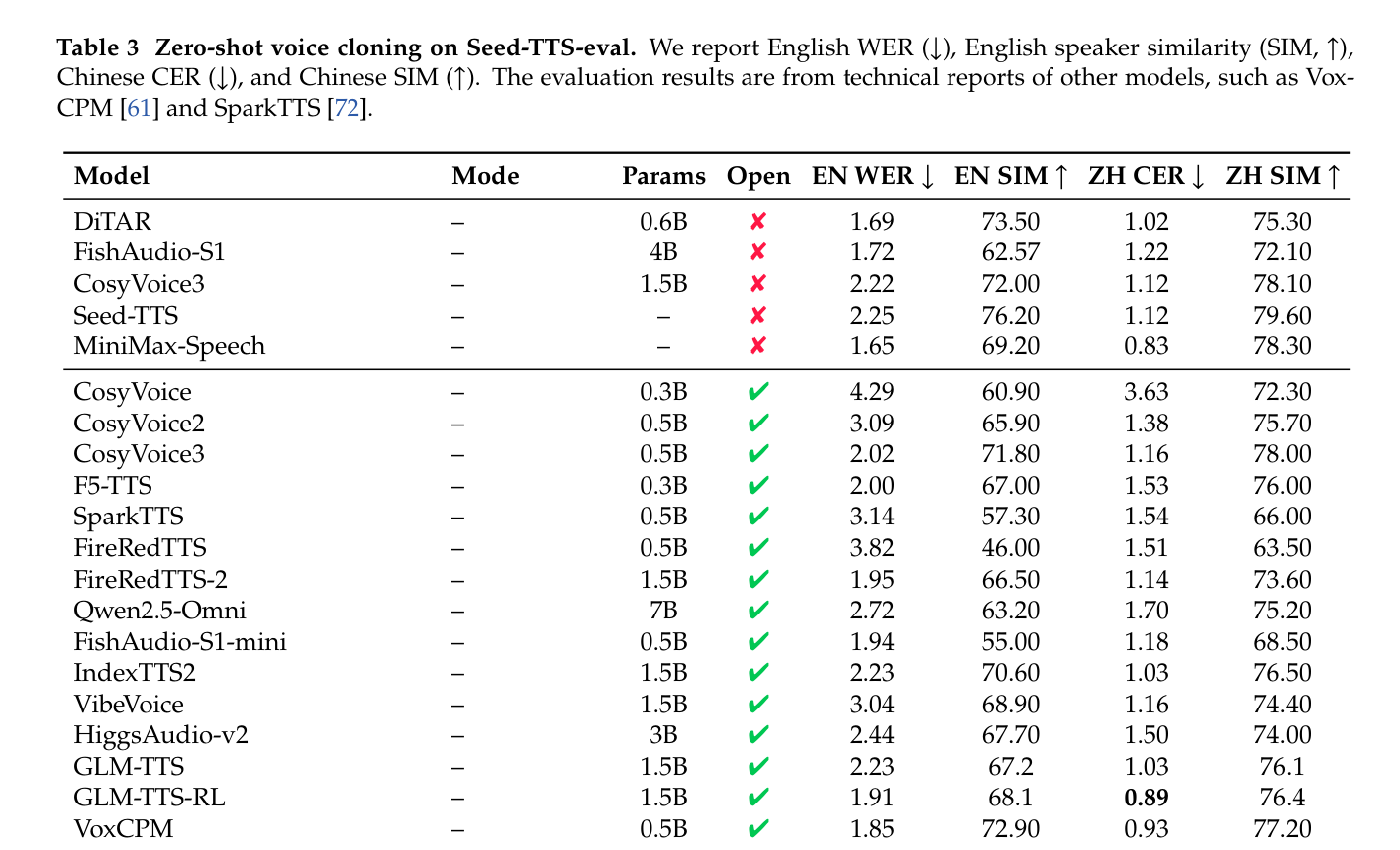
- Voice Cloning 성능 : Seed-TTS-eval에서 MOSS-TTS-Local-Transformer 는 Continuation 모드에서 다른 Open-Source 모델보다 높은 Speaker Similarity 점수(English 73.28% SIM , Chinese 79.62% SIM )를 기록하여 더 나은 Speaker Preservation 능력을 보여주었습니다
- Duration Control : MOSS-TTS 는 Target Token Count를 통한 Duration Control에서 Short에서 Long Utterance까지 일관되게 낮은 Relative Duration Error (Overall AbsErr Mean 약 0.7% )를 달성했습니다 [Table 5].
- Ultra-Long Speech Generation : MOSS-TTS 는 Ultra-Long Speech Generation에서 Content Fidelity는 유지되지만, 특히 English에서 Elapsed Time에 따른 Cumulative Speaker Drift가 주요 Bottleneck임을 보여주었습니다 [Figure 6, Table 6].
- Pronunciation Control : MOSS-TTS 는 Phoneme-/Pinyin-Level Pronunciation Control에서 낮은 Span Error를 달성하여 Partial-Replace (Chinese 1.00% CER , English 4.32% WER ) 및 Full-Replace 시나리오 모두에서 실용적인 Controllable Pronunciation Editing이 가능함을 입증했습니다 [Table 7].
4. Conclusion & Impact (결론 및 시사점)
본 Technical Report는 MOSS-TTS 가 고품질 Audio Tokenizer, Autoregressive Next-Token Modeling 및 대규모 Multilingual Pretraining을 기반으로 하는 Open Speech Generation Foundation Model로서 Scalable한 Recipe를 통해 Strong Quality와 Controllability를 제공함을 성공적으로 입증했습니다. MOSS-Audio-Tokenizer 는 다양한 비트레이트에서 강력한 Discrete Audio Tokens를 제공하며, MOSS-TTS (Delay Pattern) 는 Structural Simplicity와 Scalability를, MOSS-TTS-Local-Transformer 는 High Modeling Efficiency와 Stronger Speaker Preservation을 강조하며 두 아키텍처 간의 명확한 Tradeoff를 보여줍니다. 이 연구는 Speech Generation 분야가 Data Quality, Scale, Architectural Simplicity와 같은 LLM의 성공 원칙을 통해 발전할 수 있음을 시사합니다. MOSS-Audio-Tokenizer , MOSS-TTS , MOSS-TTS-Local-Transformer 의 공개는 Reproducible한 Current Release Account를 제공하며, Open Speech Foundation Models에 대한 Clean Baseline으로서 향후 연구에 중요한 기여를 할 것으로 기대됩니다. 미래 연구 방향으로는 Long-Context Speaker Anchoring 강화, Low-Resource Language Coverage 확대, 그리고 Fine-Grained Controllability 개선이 제시되었습니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Accurate, Interdisciplinary and Transparent Structure-property Understanding with Deep Native Structural Reasoning
- [논문리뷰] MuSViT: A Foundation Vision Model for Sheet Music Representation
- [논문리뷰] Qwen-AgentWorld: Language World Models for General Agents
- [논문리뷰] DREAM: Dense Retrieval Embeddings via Autoregressive Modeling
- [논문리뷰] Unified Multimodal Autoregressive Modeling with Shared Context-Visual Tokenizer is Key to Unification
Review 의 다른글
- 이전글 [논문리뷰] Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
- 현재글 : [논문리뷰] MOSS-TTS Technical Report
- 다음글 [논문리뷰] Matryoshka Gaussian Splatting
댓글