[논문리뷰] LASE: Language-Adversarial Speaker Encoding for Indic Cross-Script Identity Preservation
링크: 논문 PDF로 바로 열기
저자: Venkata Pushpak Teja Menta
1. Key Terms & Definitions (핵심 용어 및 정의)
- LASE (Language-Adversarial Speaker Encoder): 본 논문에서 제안하는 256차원 스피커 인코더로, 언어 정보에 독립적인 스피커 임베딩을 생성하기 위해
Gradient Reversal기법을 적용한 모델입니다. - WavLM-base-plus: LASE의 백본(backbone)으로 사용되는 사전 학습된 모델로, 본 논문에서는 동결(frozen) 상태로 사용됩니다.
- Gradient Reversal Layer (GRL): 언어 분류기(Language Classifier)의 그래디언트를 반전시켜, 인코더가 학습 과정에서 언어 정보를 제외하고 스피커 정체성 정보만을 유지하도록 유도하는 핵심 기법입니다.
- SupCon (Supervised Contrastive Loss): 스피커 정체성을 기준으로 같은 스피커의 오디오 쌍은 가깝게, 다른 스피커의 쌍은 멀게 배치하도록 학습하는 손실 함수입니다.
- Cross-script identity gap: 동일한 스피커가 언어(스크립트)를 변경할 때 발생하는 스피커 임베딩의 코사인 유사도 하락 현상을 의미합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 다국어 음성 합성 및 diarization 시스템에서 동일 화자가 언어(스크립트)를 전환할 때 발생하는 스피커 인식 오류 문제를 해결합니다. 기존의 WavLM-base-plus-sv나 ECAPA-TDNN과 같은 산업 표준 인코더들은 영어-유럽어 간에는 비교적 잘 일반화되나, 인도 언어(Indic scripts)의 스크립트 전환 시에는 상당한 성능 저하를 보입니다. 저자들은 이러한 현상이 스피커 임베딩에 언어 정보가 강하게 얽혀(entangled) 있기 때문임을 확인했습니다. 특히, Western-accented 음성 데이터에서 동일 화자가 스크립트를 바꿀 때 코사인 유사도가 최대 0.105만큼 하락하는 문제가 발생하며, 이는 실제 서비스에서 화자 오분류나 이질적인 목소리로 인식되는 원인이 됩니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 WavLM-base-plus 백본 위에 GRL이 결합된 작은 투영 헤드(projection head)를 얹어, 스피커 정체성은 유지하면서 언어 정보는 제거하는 LASE 모델을 설계했습니다. 학습 시에는 SupCon을 통해 스피커 정체성을 강화하고, 동시에 4개 언어를 분류하는 언어 분류기에 GRL을 적용하여 언어 정보를 무력화시켰습니다. [Figure 2]는 이러한 학습 과정에서 언어 손실이 일정한 수준으로 유지되면서 스피커 손실이 감소하는 성공적인 최적화 과정을 보여줍니다. 실험 결과, LASE는 Western-accented 평가셋에서 스크립트 간 유사도 하락 폭(Gap)을 기존 대비 84.3% 감소시켰으며, 이는 WavLM-SV와 ECAPA-TDNN 등 베이스라인 대비 압도적인 성능 우위를 보여줍니다 [Table 1]. 또한, 합성 다화자 diarization 벤치마크에서 LASE는 ECAPA-TDNN과 대등한 수준의 cross-script 화자 재현율(recall)을 달성하면서도, 학습 데이터 규모는 100배 적게 사용했습니다 [Table 2]. 특히 [Figure 1]은 LASE가 스크립트 간 임베딩 간극을 거의 제거하고, 화자 간 구분을 명확히 하는 효과를 시각적으로 잘 보여줍니다.
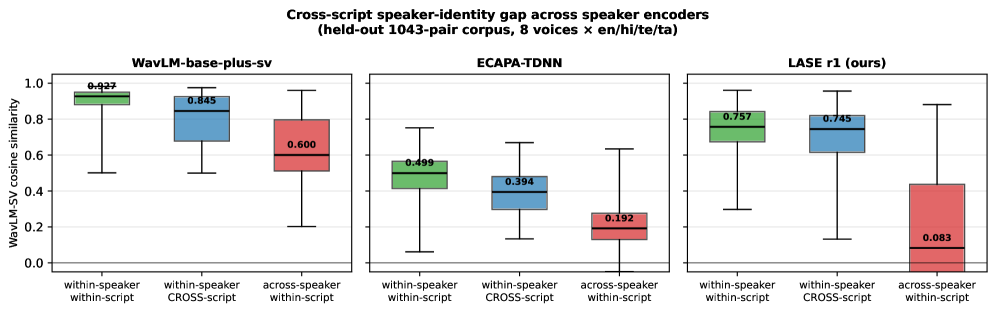
Figure 1 — 스피커 인코더별 유사도 분포 비교
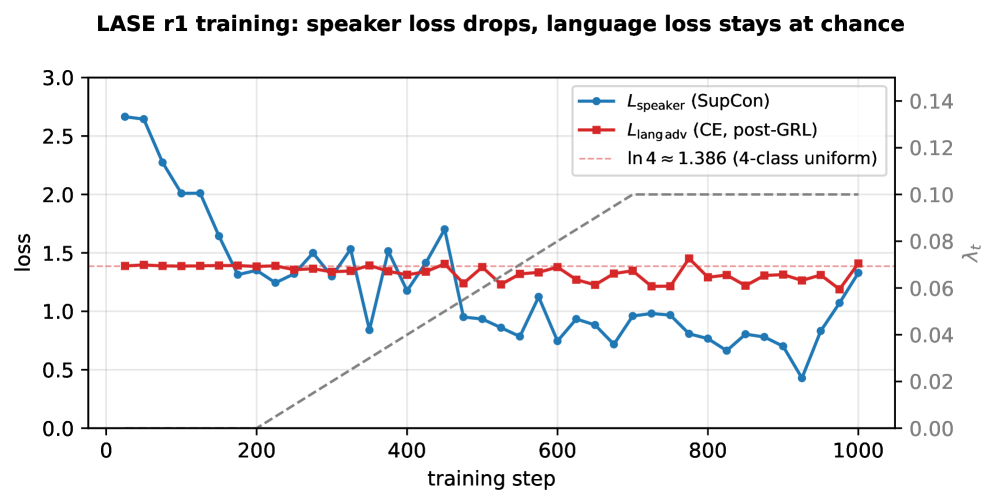
Figure 2 — LASE 모델 학습 손실 곡선
4. Conclusion & Impact (결론 및 시사점)
본 연구는 도메인 적대적 학습을 통해 인도 언어 스크립트 전환 시 발생하는 스피커 임베딩의 왜곡을 성공적으로 해결했습니다. LASE는 단순한 기법임에도 불구하고 데이터 효율성과 강력한 정체성 유지 능력을 입증하여, 다국어 환경에서의 음성 합성 및 diarization 서비스 품질을 크게 향상시킬 것으로 기대됩니다. 본 논문에서 공개한 학습 데이터셋과 모델 가중치는 해당 분야 연구자들에게 유용한 참조점이 될 것입니다. 이번 결과는 대규모 데이터셋 구축 없이도 특정 도메인의 불변성을 확보할 수 있는 적대적 학습의 실용성을 다시 한번 확인시켜 줍니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] MOSS-TTS Technical Report
- [논문리뷰] Qwen3-TTS Technical Report
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] Marco-Voice Technical Report
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
Review 의 다른글
- 이전글 [논문리뷰] From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills
- 현재글 : [논문리뷰] LASE: Language-Adversarial Speaker Encoding for Indic Cross-Script Identity Preservation
- 다음글 [논문리뷰] Learning to Act and Cooperate for Distributed Black-Box Consensus Optimization
댓글