[논문리뷰] UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
링크: 논문 PDF로 바로 열기
저자: Zichuan Lin, Feiyu Liu, Yijun Yang, Jiafei Lyu, Yiming Gao, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- Multimodal Large Language Models (MLLMs) : GUI Agent 개발에 활용되는, 텍스트와 이미지(GUI 스크린샷)와 같은 다양한 모달리티의 데이터를 처리하고 이해할 수 있는 대규모 언어 모델.
- GUI Agent : Graphical User Interface Agent의 약자로, GUI를 자율적으로 인식, 이해, 계획, 추론 및 조작할 수 있는 지능형 시스템을 의미합니다.
- Rejection Fine-Tuning (RFT) : UI-Voyager의 첫 번째 학습 단계로, 에이전트가 여러 궤적(trajectory)을 생성하고, 규칙 기반 검증기를 통해 성공적인 궤적을 필터링한 후, 고품질 샘플을 사용하여 모델을 반복적으로 미세 조정하여 데이터와 모델의 동시 발전을 가능하게 하는 자가 진화(self-evolving) 훈련 전략입니다.
- Group Relative Self-Distillation (GRSD) : UI-Voyager의 두 번째 학습 단계로, 동일한 태스크에 대해 성공한 궤적과 실패한 궤적 간의 'fork point'를 식별하고, 성공적인 궤적에서 얻은 단계별(step-level) 교정 감독(supervision) 신호를 실패한 궤적에 전달하여 학습을 개선하는 방법론입니다.
- Credit Assignment : 특히 긴 호라이즌(long-horizon)의 태스크에서 희소한 보상(sparse rewards)이 주어질 때, 일련의 행동 중 어떤 특정 행동이 최종 성공 또는 실패에 기여했는지 파악하기 어려운 Reinforcement Learning(RL)의 근본적인 문제점입니다.
- Fork Point : 동일한 태스크를 수행하는 두 궤적(성공 궤적과 실패 궤적)이 동일한 화면 상태(screen state)에 도달했지만, 이후 서로 다른 행동을 선택하여 궤적이 분기되는 결정적인 지점을 의미합니다.
- Structural Similarity Index (SSIM) : 두 이미지 간의 유사성을 측정하는 지표로, UI-Voyager에서는 궤적 간의 화면 상태 일치 여부(cross-trajectory state matching)를 판단하는 데 사용됩니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
Multimodal Large Language Models (MLLMs)의 발전과 함께 자율 모바일 GUI Agent에 대한 관심이 증가하고 있지만, 기존 방법론들은 비효율적인 실패 궤적(failed trajectory) 학습과 장기(long-horizon) GUI 태스크에서 희소한 보상(sparse rewards)에 따른 모호한 Credit Assignment 문제에 직면하고 있습니다. 모바일 환경의 다양하고 동적인 UI 특성으로 인해 에이전트 경험의 상당 부분을 실패 궤적이 차지함에도 불구하고, 전통적인 훈련 파이프라인에서는 이러한 실패 궤적이 제대로 활용되지 못하여 데이터 효율성(data efficiency)이 저하되는 문제가 발생합니다. 또한, 성공/실패와 같은 거시적인 궤적 수준(trajectory-level)의 보상은 에이전트가 특정 실패 원인 단계를 식별하지 못하게 하여 안정적인 정책 최적화(policy optimization)를 방해합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 UI-Voyager 라는 두 단계의 자가 진화(self-evolving) 최적화 파이프라인을 제안합니다
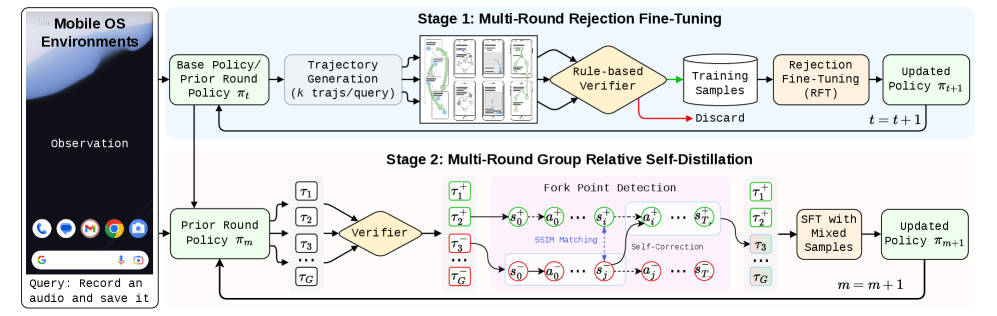
첫 번째 단계는 Rejection Fine-Tuning (RFT) 입니다. 이는 베이스 정책(base policy)이 여러 궤적을 생성하고, 규칙 기반 검증기(rule-based verifier)가 이 궤적들을 필터링하여 고품질의 성공적인 샘플만을 수집하는 반복적인 메커니즘을 사용합니다. 이 과정을 통해 훈련 데이터와 모델 역량이 자동으로 상호 발전(co-evolution)합니다. 실험 결과, RFT는 Pass@1 성능을 37% 에서 73% 로 크게 향상시키는 일관된 개선을 보였습니다 [Figure 4].
두 번째 단계는 Group Relative Self-Distillation (GRSD) 입니다. 이는 장기 GUI 태스크에서 심각한 Credit Assignment 문제를 완화하기 위해 고안되었습니다. GRSD는 동일한 태스크에 대한 그룹 롤아웃(group rollouts) 내에서 성공 궤적과 실패 궤적 간의 "fork point"를 식별합니다
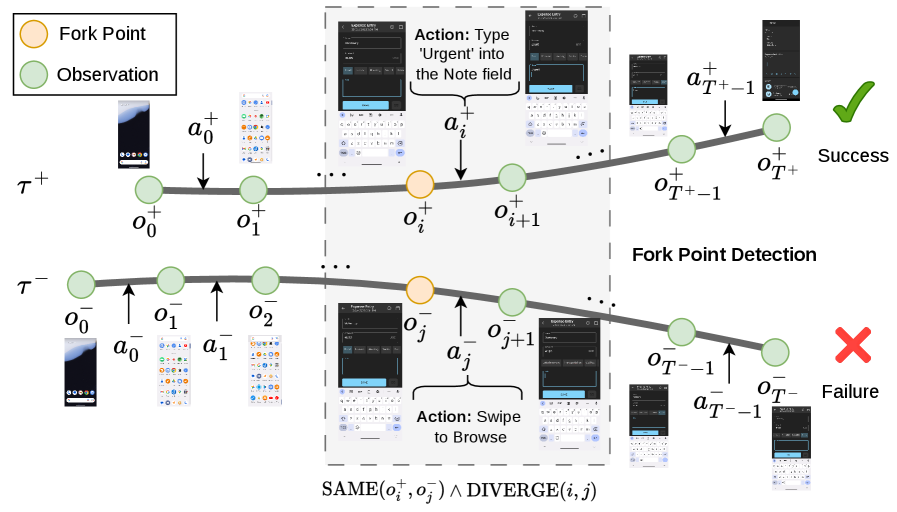
이는 SSIM (Structural Similarity Index) 기반의 교차 궤적 상태 매칭(cross-trajectory state matching)을 통해 이루어지며, 동일한 화면 상태에서 에이전트의 행동이 달라지는 결정적인 순간을 찾아냅니다. GRSD는 성공 궤적에서 얻은 정확한 단계별(step-level) 감독 신호를 실패 궤적의 해당 "fork point"에 적용하여, 희소한 궤적 수준 보상(sparse trajectory-level rewards)을 정확한 자가 증류(self-distillation) 학습 신호로 대체합니다. 이 방법은 실패 궤적을 재활용하고 Credit Assignment 문제를 효과적으로 완화합니다. GRSD는 기존 GRPO 및 PPO 와 같은 RL 방법론들이 76% 수준에서 정체되는 것과 달리, RFT로 초기화된 모델의 Pass@1 성공률을 73.2% 에서 81% 로 크게 향상시켰습니다 [Figure 8].
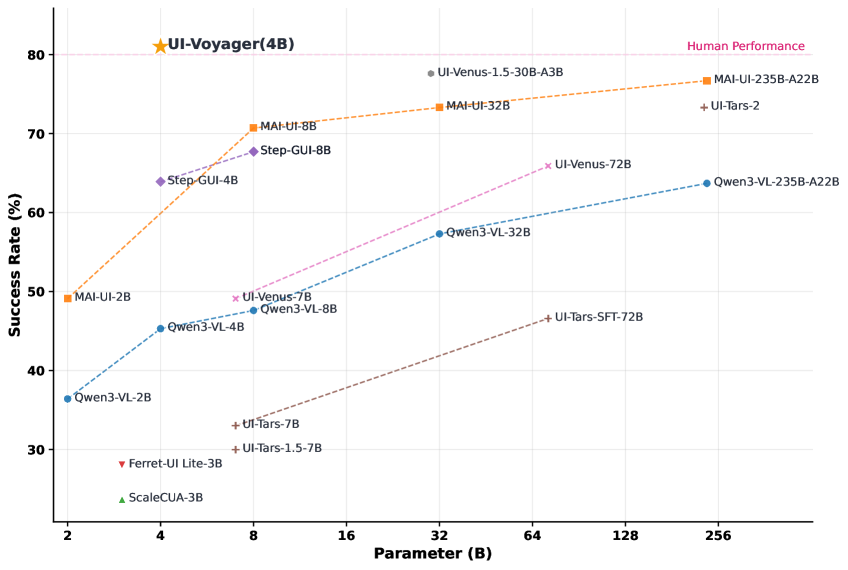
최종적으로, UI-Voyager 는 AndroidWorld 벤치마크에서 Qwen3-VL-4B-Instruct 를 백본으로 사용하여 81.0% 의 Pass@1 성공률을 달성했습니다 [Table 2]. 이는 훨씬 더 큰 모델을 포함한 모든 기준선(baseline) 방법과 보고된 인간 수준 성능인 80.0% 를 뛰어넘는 결과입니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 모바일 GUI Agent 훈련에서 나타나는 실패 궤적으로부터의 비효율적인 학습과 희소한 보상에 따른 모호한 Credit Assignment라는 두 가지 중요한 과제를 다루었습니다. 저자들은 Rejection Fine-Tuning (RFT) 과 Group Relative Self-Distillation (GRSD) 으로 구성된 2단계 자가 진화 프레임워크인 UI-Voyager 를 제안했습니다. RFT는 데이터와 모델의 자동적인 공동 진화를 가능하게 하며, GRSD는 "fork point" 감지(detection)를 활용하여 성공적인 궤적에서 조밀한 단계별 감독(dense step-level supervision)을 제공합니다.
AndroidWorld 벤치마크의 116개 태스크에 대한 실험 결과, UI-Voyager 의 4B 모델은 81.0% 의 Pass@1 성공률을 달성하며 모든 기준선 모델(더 큰 모델 포함)과 인간 수준 성능을 능가했습니다. 이러한 결과는 UI-Voyager가 효율적이고 자가 진화하며 고성능의 모바일 GUI 자동화를 향한 중요한 진전을 이루었음을 보여줍니다. 이 연구는 고비용의 수동 데이터 어노테이션(manual data annotation) 없이도 강력하고 효율적인 GUI Agent 개발의 가능성을 제시하며, 향후 다른 GUI 태스크로의 확장 및 적응형 추론(adaptive reasoning)과 자가 교정 메커니즘(self-correction mechanisms) 연구에 중요한 시사점을 제공합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Xiaomi-GUI-0 Technical Report
- [논문리뷰] UI-KOBE: Knowledge-Oriented Behavior Exploration for Lightweight Graph-Guided GUI Agents
- [논문리뷰] Hindsight Credit Assignment for Long-Horizon LLM Agents
- [논문리뷰] Alleviating Sparse Rewards by Modeling Step-Wise and Long-Term Sampling Effects in Flow-Based GRPO
- [논문리뷰] UI-MOPD: Multi-Platform On-Policy Distillation for Continual GUI Agent Learning
Review 의 다른글
- 이전글 [논문리뷰] Toward Physically Consistent Driving Video World Models under Challenging Trajectories
- 현재글 : [논문리뷰] UI-Voyager: A Self-Evolving GUI Agent Learning via Failed Experience
- 다음글 [논문리뷰] Unleashing Spatial Reasoning in Multimodal Large Language Models via Textual Representation Guided Reasoning
댓글