[논문리뷰] Unified Spatio-Temporal Token Scoring for Efficient Video VLMs
링크: 논문 PDF로 바로 열기
저자: Jianrui Zhang, Yue Yang, et al.
1. Key Terms & Definitions
- STTS (Spatio-Temporal Token Scoring) : ViT와 LLM 전반에 걸쳐 Vision Token을 효율적으로 Pruning하기 위해 제안된 경량 모듈로, Text Conditioning이나 Token Merging 없이 End-to-End Training이 가능합니다.
- VLM (Vision-Language Model) : 비디오와 텍스트 입력을 처리하여 복잡한 추론 작업을 수행하는 모델로, 비디오 이해 및 질의응답과 같은 멀티모달 태스크에 사용됩니다.
- Token Pruning : 계산 효율성을 높이기 위해 정보가 적거나 중복되는 Visual Token을 선별적으로 제거하는 과정입니다.
- Packing Algorithm : Pruning으로 인해 생성된 Sparse하고 가변 길이의 Token 시퀀스를 Compact한 Dense Tensor로 변환하여 ViT 내에서 효과적인 Batched Matrix Multiplications을 가능하게 하는 기법입니다.
- Test-Time Scaling (TTS) : 추론 시 Pruned 모델의 프레임 수를 비례적으로 늘려 Baseline과 동일한 Visual Token Usage를 유지하면서 더 풍부한 Temporal Context를 처리할 수 있게 하는 전략입니다.
2. Motivation & Problem Statement
Video VLM은 방대한 수의 프레임을 인코딩하고, 각 프레임이 Vision Transformer (ViT)에 의해 수백 개의 Patch Token으로 분해되면서 막대한 계산 비용을 발생시킵니다. 이는 Attention Mechanism 하에서 제곱으로 증가하는 비용으로 이어져 높은 메모리 사용량, 훈련 처리량 감소, 추론 Latency 증가를 초래합니다. 특히 긴 Visual Token 시퀀스는 ViT 인코더뿐만 아니라 그 출력을 소비하는 Large Language Model (LLM)에도 상당한 계산 부담을 줍니다.
기존 Pruning 방법론은 이러한 문제의 일부만 다루고 있습니다. Pre-ViT 및 In-ViT 접근 방식은 주로 Action Recognition이나 Object Segmentation과 같은 Unimodal Perception Task의 Spatial Redundancy를 줄이는 데 초점을 맞추며, Multimodal VLM 목표나 비디오 입력의 Cross-Frame Temporal Redundancy를 고려하지 않습니다. 반면 Post-ViT 접근 방식은 ViT에서 LLM으로 전달되는 Token을 Pruning하지만, ViT 인코더 자체는 건드리지 않아 비디오 입력의 주요 계산 병목 현상을 해결하지 못합니다. 또한, 많은 기존 방법은 복잡한 Merging Algorithm이나 Text-Conditioned Token Selection Mechanism에 의존하여 시스템에 복잡성을 더합니다. 따라서, ViT와 LLM 모두에서 End-to-End 효율성을 달성하는 통합적이고 간단한 Vision Token Pruning 솔루션이 필요합니다.
3. Method & Key Results
본 논문은 Vision Token의 End-to-End Pruning을 위한 경량 모듈인 Spatio-Temporal Token Scoring (STTS) 를 제안합니다. STTS는 ViT layer l=3 이후에 삽입되며, Scorer는 Token Pooler와 3-Layer MLP로 구성됩니다. 이 Scorer는 멀티모달 하류 태스크 objective를 통해 Spatial Saliency를 암묵적으로 학습하고, Auxiliary Loss를 통해 Inter-Frame Temporal Redundancy를 명시적으로 학습하는 Dual-Axis Scoring Mechanism 을 사용합니다. Scorer가 예측한 Score는 다음 ViT Layer l+1 의 Attention Matrix에 Bias로 주입되어 End-to-End Trainable하게 작동합니다. Token Pruning 후, First-Fit Descending Algorithm 을 사용하여 Sparse한 Token 시퀀스를 Dense Tensor로 Packing 하며, 이는 실제 계산 절감으로 이어집니다. Temporal Scoring을 위한 Auxiliary Loss는 Neighboring-Frame Cosine Similarity를 사용하여 인접 프레임 간의 유사도에 기반해 불필요한 Temporal Redundancy를 명시적으로 식별하도록 Scorer를 guide합니다.
실험 결과, STTS는 Vision Token의 50% 를 Pruning하면서도 13개의 Short 및 Long Video QA 태스크에서 평균 성능 하락이 단 0.7% 에 불과하며, 훈련 및 추론 효율성에서 62% 의 향상을 달성했습니다. 특히, 128-frame 설정에서 50% Pruning 시 훈련 시 1.62x , 추론 시 1.61x 의 Speedup을 보였고, 256-frame 설정에서는 각각 2.25x 및 2.22x 의 훨씬 더 큰 Speedup을 보여 Sequence Length가 길어질수록 효율성 이득이 증가함을 확인했습니다 [Figure 5, Table 6, Table 7]. 30% Pruning 시에는 NextQA 및 VideoMME와 같은 일부 벤치마크에서 Baseline 성능을 유지하거나 심지어 능가하는 결과도 보여, Scorer가 'Task-Essential' Token을 효과적으로 식별하고 불필요한 Background 정보를 제거함을 입증했습니다
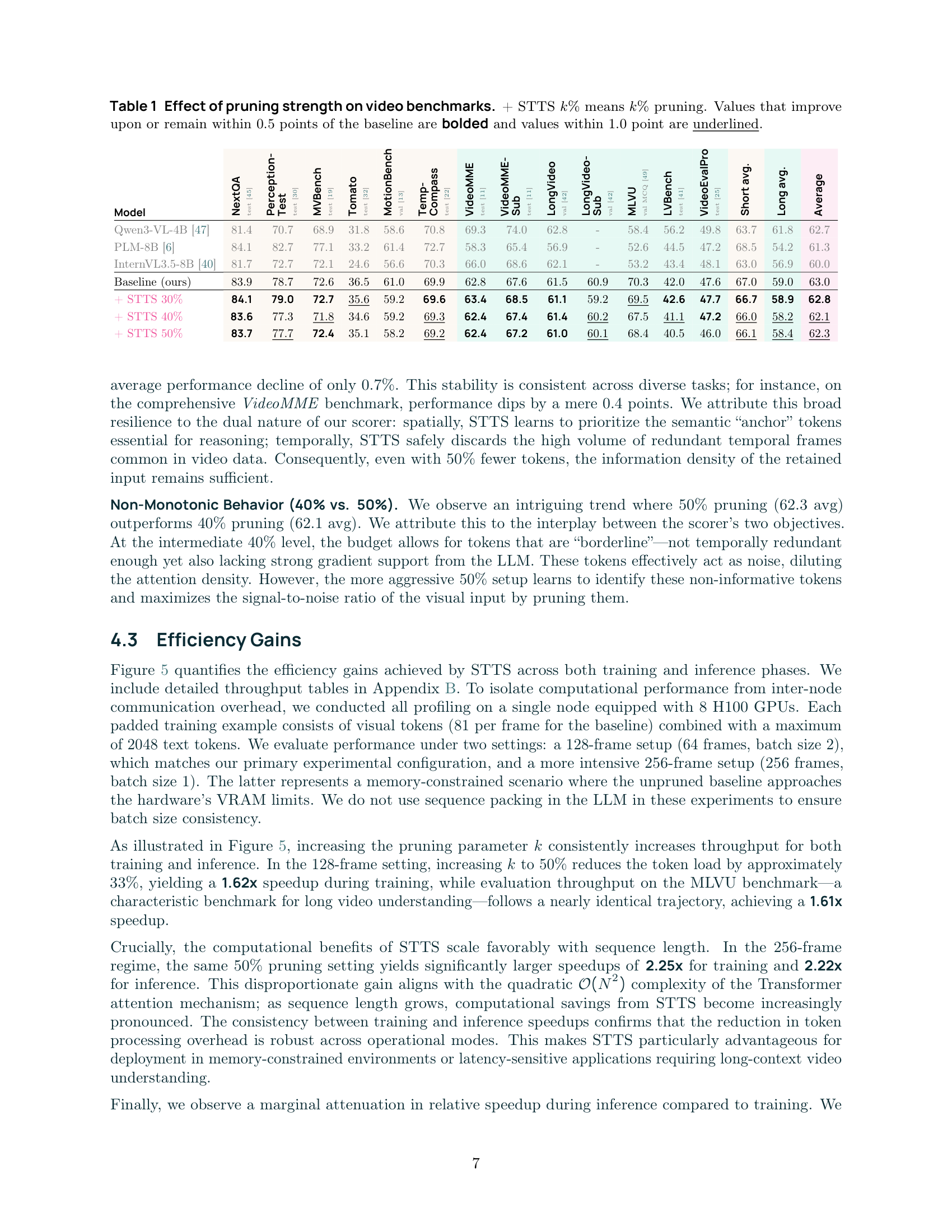 Table 1: Effect of pruning strength on video benchmarks
Table 1: Effect of pruning strength on video benchmarks
. 또한, Test-Time Scaling (TTS) 을 Long Video QA에 적용하여 Baseline 대비 0.5-1% 의 성능 향상을 추가로 달성하여, 동일한 계산 예산 내에서 더 긴 Temporal Context를 처리할 수 있는 Scalability를 보여주었습니다 [Table 3]. STTS는 Inference-Only Baselines (Heuristic, ToMe) 및 Fully Trained ToMe 모델보다도 우수한 성능을 보여, Video Context에서 Spatial 및 Temporal 중요성을 효과적으로 포착하는 능력을 입증했습니다 [Table 5, Table 8].
4. Conclusion & Impact
본 논문은 Spatio-Temporal Token Scoring (STTS)을 제안하며, 이는 Vision Encoder와 LLM 전반에 걸쳐 Token Pruning을 통합하는 End-to-End Trainable Framework입니다. STTS는 하류 태스크 Gradient와 Auxiliary Temporal Loss를 활용하여 Redundant Background Noise를 효과적으로 필터링하고 Critical Semantic Foreground를 보존함으로써 복잡한 Text-Conditioned Merging의 필요성을 없앱니다. 실험을 통해 STTS가 Vision Token 수를 안전하게 50% 까지 줄이면서도 60% 이상의 훈련 및 추론 속도 향상을 달성하며, 13개 Video QA 벤치마크에서 미미한 성능 저하만을 보였음을 입증했습니다. 또한, STTS는 Test-Time Scaling과 자연스럽게 결합하여 엄격한 계산 제약 하에서도 훨씬 더 긴 Temporal Context를 처리할 수 있는 능력을 unlock합니다.
궁극적으로 STTS는 VLM 효율성 병목 현상에 대한 novel하고 단순하며 해석 가능한 해결책을 제시하며, 더욱 Accessible하고 Scalable한 Video Understanding 시스템을 위한 길을 열었습니다. 이는 메모리 제약이 있는 환경이나 Latency에 민감한 애플리케이션에서 Long-Context Video 이해를 가능하게 하는 데 특히 중요한 영향을 미칠 것입니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Variable-Width Transformers
- [논문리뷰] Skip a Layer or Loop It? Learning Program-of-Layers in LLMs
- [논문리뷰] End-to-End Context Compression at Scale
- [논문리뷰] A Multi-AI-agent Framework Enabling End-to-end Finite Element Analysis for Solid Mechanics Problems
- [논문리뷰] Swift Sampling: Selecting Temporal Surprises via Taylor Series
Review 의 다른글
- 이전글 [논문리뷰] Temporal Gains, Spatial Costs: Revisiting Video Fine-Tuning in Multimodal Large Language Models
- 현재글 : [논문리뷰] Unified Spatio-Temporal Token Scoring for Efficient Video VLMs
- 다음글 [논문리뷰] Video-CoE: Reinforcing Video Event Prediction via Chain of Events
댓글