[논문리뷰] End-to-End Autoregressive Image Generation with 1D Semantic Tokenizer
링크: 논문 PDF로 바로 열기
메타데이터
저자: Wenda Chu, Bingliang Zhang, Jiaqin Han, Yizhuo Li, Linjie Yang, Yisong Yue, Qiushan Guo, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- 1D Vision Tokenizer: 2D 공간 구조를 강제하지 않고 이미지를 일차원 시퀀스 형태로 압축하는 토크나이저로, AR 모델의 인과적(causal) 생성 방식에 적합함.
- APR (Autoregressive Prediction Reconstruction) loss: AR 모델의 Teacher-forcing 예측값을 디코더를 통해 다시 픽셀 공간으로 복원하여, 생성 품질에 직접적인 피드백을 제공하는 손실 함수.
- IBQ (Improved Block Quantizer): 잠재 표현을 이산적인 코드로 양자화하는 모듈로, Straight-through estimation 기법을 사용하여 미분 불가능한 양자화 과정에서도 기울기 역전파를 가능하게 함.
- Implicit Alignment: 잠재 토큰 자체를 정렬하지 않고, 인코더의 은닉층(hidden patch embeddings)을 VFM의 의미적 특징(semantic features)과 정렬함으로써 공간 구조 왜곡 없이 의미 정보를 주입하는 방식.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 기존의 2단계 학습 방식이 토크나이저와 생성 모델 간의 비정렬 문제를 야기하여 최종 생성 품질을 제한한다는 점을 해결하고자 한다. 기존 패러다임은 토크나이저를 단순히 재구성(reconstruction) 과제로만 학습시키고 동결시킨 뒤, 이후 고정된 토큰 시퀀스에 대해 생성 모델을 학습시키는데, 이 과정에서 토크나이저가 생성 과제에 최적화되지 못하는 한계가 있다 [Figure 1]. 또한, 기존 2D 토크나이저는 공간적 종속성을 가지므로 1D 인과적 생성과 구조적 불일치가 발생한다. 이를 위해 저자들은 재구성과 생성을 동시에 최적화하는 단일 단계의 End-to-End 학습 프레임워크를 제안한다 [Figure 2].
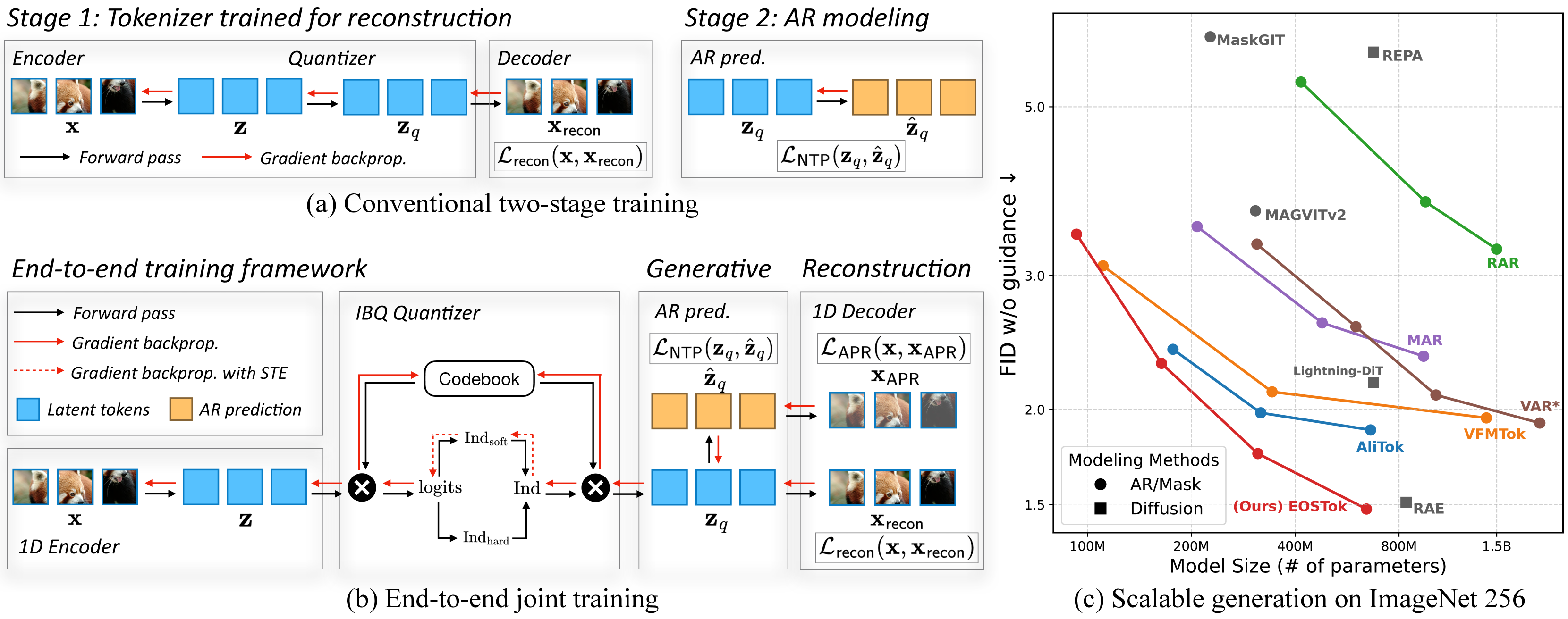
Figure 1 — 기존 학습법 vs 제안 모델
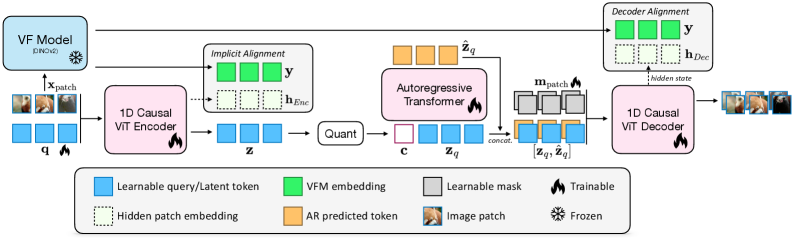
Figure 2 — EOSTok 전체 아키텍처
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 End-to-End 학습을 통해 토크나이저와 AR 생성 모델을 공동으로 최적화하는 EOSTok을 제안한다. 핵심 방법론은 NTP(Next Token Prediction) 손실의 간극을 메우기 위해 APR loss를 도입하여 생성 결과물로부터 직접적인 기울기 피드백을 토크나이저로 전달하는 것이다 [Figure 3]. 또한, DINOv2와 같은 VFM의 의미적 정보를 Implicit Alignment를 통해 주입하여 1D 잠재 공간의 품질을 향상시킨다 [Figure 4]. 실험 결과, 제안 모델은 ImageNet 256×256 환경에서 별도의 Classifier guidance 없이 1.48의 최첨단(SOTA) FID 점수를 기록하였다. 또한, 모델 규모(S, B, L, H)를 확장함에 따라 성능이 체계적으로 개선되는 스케일링 능력을 확인하였으며, 특히 EOSTok-H 모델은 기존 모델 대비 최대 100배 빠른 생성 속도를 보인다 [Table 3].
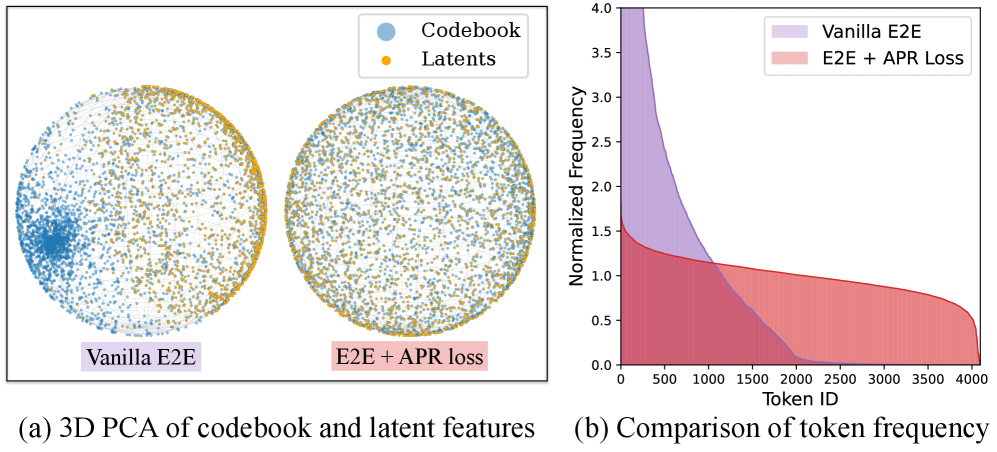
Figure 3 — APR 손실의 역할
4. Conclusion & Impact (결론 및 시사점)
본 논문은 1D 시맨틱 토크나이저를 기반으로 재구성, 생성, 의미 정렬을 통합하는 효율적인 End-to-End 학습 파이프라인을 성공적으로 구현하였다. 본 연구는 차세대 생성 모델의 핵심인 토크나이저 설계에 있어 공간 구조 왜곡 없이 의미 정보를 보존하는 것이 중요함을 입증했다. 이 연구 결과는 향후 대규모 이미지 생성 모델의 학습 효율성을 극대화하고, 더욱 정교한 시각적 합성(visual synthesis)이 필요한 산업계 응용 분야에 큰 기여를 할 것으로 기대된다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] RaysUp: Ultra-light Universal Feature Upsampling via Geometry-Aware Ray Representation
- [논문리뷰] IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
- [논문리뷰] End-to-End Context Compression at Scale
- [논문리뷰] SOCO: Benchmarking Semantic Object Correspondence in Vision Foundation Models
- [논문리뷰] DecQ: Detail-Condensing Queries for Enhanced Reconstruction and Generation in Representation Autoencoders
Review 의 다른글
- 이전글 [논문리뷰] AnalogRetriever: Learning Cross-Modal Representations for Analog Circuit Retrieval
- 현재글 : [논문리뷰] End-to-End Autoregressive Image Generation with 1D Semantic Tokenizer
- 다음글 [논문리뷰] From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills
댓글