[논문리뷰] Video-CoE: Reinforcing Video Event Prediction via Chain of Events
링크: 논문 PDF로 바로 열기
저자: Qile Su, Jing Tang, Rui Chen, Lei Sun, Xiangxiang Chu
1. Key Terms & Definitions (핵심 용어 및 정의)
- Video Event Prediction (VEP) : 관찰된 비디오로부터 미래 이벤트를 예측하는 태스크로, 비디오에 대한 fine-grained temporal modeling과 미래 이벤트 간의 logical relationship 구축을 요구합니다.
- Multimodal Large Language Models (MLLMs) : 비디오와 텍스트 정보를 모두 처리하고 이해하여 다양한 vision task를 수행할 수 있는 대규모 언어 모델입니다.
- Chain of Events (CoE) Paradigm : 입력 비디오에서 fine-grained temporal event chain을 구축하여 MLLM이 visual content와 미래 이벤트 간의 logical connection에 집중하도록 강제하는 제안된 패러다임입니다.
- CoE-SFT (Supervised Fine-Tuning) : CoE 훈련의 첫 번째 단계로, supervised learning을 통해 모델이 과거 비디오 증거와 미래 이벤트 간의 logical connection을 확립하도록 fine-tuning합니다.
- CoE-GRPO (Group Relative Policy Optimization) : CoE 훈련의 두 번째 단계로, reinforcement learning을 사용하여 fine-grained temporal event chain을 구성하고 temporal localization 및 video understanding 능력을 강화합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
비디오 태스크에 대한 MLLM 애플리케이션의 발전에도 불구하고, VEP 는 상대적으로 미개척 상태로 남아있습니다. 기존 MLLM 은 비디오에 대한 fine-grained temporal modeling과 미래 이벤트 간의 logical relationship 구축에 어려움을 겪고 있으며, 이는 VEP 의 정확도 저하로 이어집니다. 저자들은 현재 MLLM 의 주요 한계점으로 미래 이벤트 예측을 위한 Logical Reasoning Ability 부족 과 Visual Information의 불충분한 활용 을 지적합니다. MLLM 은 종종 비디오 증거에 기반한 예측보다는 텍스트 기반 답변 옵션에 의존하여, 관찰된 내용과 미래 사이의 약한 연결성을 보이고 [Figure 1a], 시각적 토큰에 대한 attention 할당이 현저히 낮아 텍스트 중심의 modality bias를 보입니다 [Figure 1b]. 또한, VEP 는 본질적으로 open-set problem이며, 기존 SFT 데이터는 옵션 분석에 중점을 두어 논리적 추론 과정을 직접적으로 다루지 못했습니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 이러한 문제를 해결하기 위해 Chain of Events (CoE) 패러다임과 두 단계 훈련 접근 방식인 CoE-SFT 및 CoE-GRPO 를 제안합니다. CoE 패러다임은 입력 비디오를 fine-grained temporal event chain ( EC )으로 분할하여 강력한 visual grounding을 촉진하고, 관찰된 비디오와 구성된 이벤트 체인에 대해 공동으로 추론하여 미래 이벤트를 예측합니다. 첫 번째 단계인 CoE-SFT 는 Qwen2.5-VL-72B 모델을 사용하여 비디오 내용에서 미래 이벤트를 도출하는 논리적 추론 과정을 생성하도록 학습시키며 [Figure 2], 두 번째 단계인 CoE-GRPO 는 모델의 temporal localization 및 video understanding 능력을 강화합니다
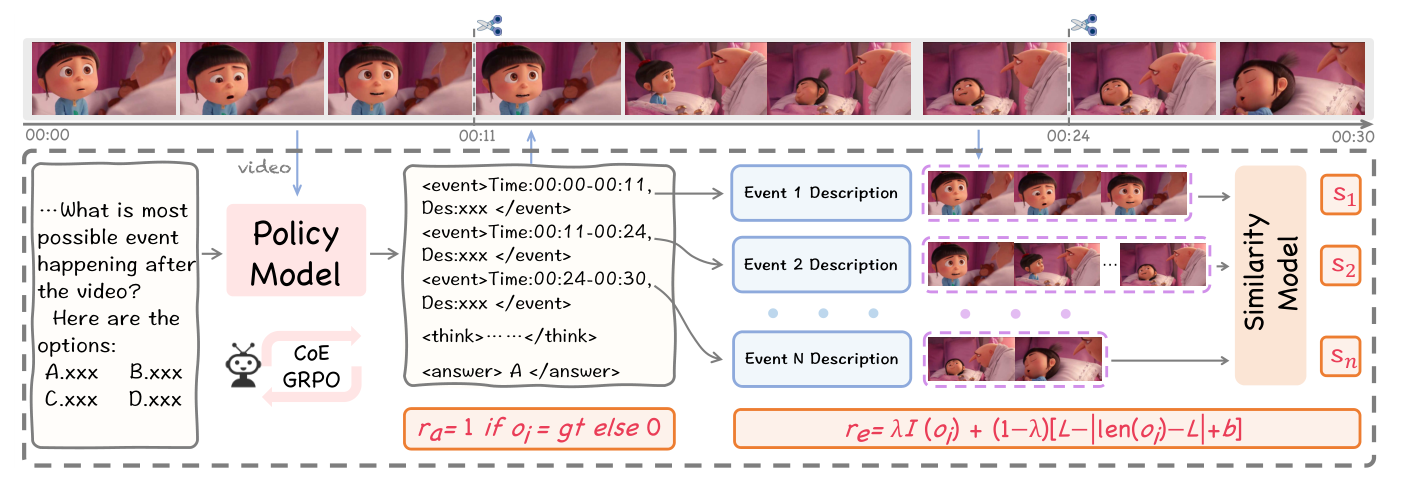 Figure 3: An illustration of our proposed CoE-GRPO method. The overall supervision signal consists of three components: rc encourages the model to follow the CoE reasoning paradigm and constrains the CoE length; rs supervises the alignment between event timestamps and textual descriptions while preventing reward hacking; and ra provides verifiable reward signals. The scissor icon indicates the temporal segmentation of video clips based on timestamps.
Figure 3: An illustration of our proposed CoE-GRPO method. The overall supervision signal consists of three components: rc encourages the model to follow the CoE reasoning paradigm and constrains the CoE length; rs supervises the alignment between event timestamps and textual descriptions while preventing reward hacking; and ra provides verifiable reward signals. The scissor icon indicates the temporal segmentation of video clips based on timestamps.
. CoE-GRPO 는 이벤트의 시작 및 끝 타임스탬프와 세부 설명을 포함하는 특별한 <event>...</event> 태그를 도입하고, 정확성, 이벤트 체인 길이 제어, 그리고 이벤트 설명과 비디오 내용 간의 일관성을 보장하는 similarity reward (rs) 를 포함하는 복합적인 CoE reward (rc) 를 사용합니다.
실험 결과, 제안된 방법은 FutureBench 및 AVEP 벤치마크에서 기존 MLLM 들을 일관되게 능가하며 state-of-the-art 성능을 달성했습니다. FutureBench 에서 CoE-GRPO (Ours) 는 Qwen2.5-VL-7B 기반으로 AVG 정확도 75.00% 를 기록하여 Vanilla SFT (64.39%) 및 Vanilla GRPO (67.28%) 를 크게 상회했습니다
![Table 1: Evaluation results of open-source/commercial MLLMs and our proposed CoE on FutureBench [43].](/paper-images/2026-03-19/2603.14935/table_1.png) Table 1: Evaluation results of open-source/commercial MLLMs and our proposed CoE on FutureBench [43].
Table 1: Evaluation results of open-source/commercial MLLMs and our proposed CoE on FutureBench [43].
. AVEP 벤치마크에서는 Verb 정확도 12.24/18.75 , Noun F1-Score 65.16/64.03 , Action F1-Score 8.29/9.88 를 달성하여 우수성을 입증했습니다 [Table 2]. 또한, CoE-GRPO 는 시각적 토큰에 대한 attention을 +15.11% 크게 증가시켜 시각 정보 활용도를 높였음을 보여줍니다 [Table 3, Figure 4].
4. Conclusion & Impact (결론 및 시사점)
본 연구는 CoE 패러다임을 통해 VEP 에서 MLLM 이 직면한 논리적 추론 능력 부족과 시각 정보 활용 미흡이라는 주요 한계를 효과적으로 해결했습니다. 제안된 방법론은 MLLM 이 temporal event chain을 구성하고 관찰된 비디오에 대해 논리적으로 추론하여 미래 이벤트를 예측할 수 있도록 합니다. 이는 VEP 태스크에 대한 포괄적인 baseline을 구축하여 향후 연구의 견고한 기반을 제공합니다. 또한, 본 연구는 VEP 의 실질적인 가치를 입증하고, 효율적인 접근 방식을 통해 대규모 주석이나 광범위한 재훈련 없이 MLLM 의 비디오 이벤트 예측 능력을 강화하는 방향을 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] Robust-R1: Degradation-Aware Reasoning for Robust Visual Understanding
- [논문리뷰] Unlocking Data Value in Finance: A Study on Distillation and Difficulty-Aware Training
- [논문리뷰] Controllable Memory Usage: Balancing Anchoring and Innovation in Long-Term Human-Agent Interaction
- [논문리뷰] Entropy-Adaptive Fine-Tuning: Resolving Confident Conflicts to Mitigate Forgetting
- [논문리뷰] Falcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
Review 의 다른글
- 이전글 [논문리뷰] Unified Spatio-Temporal Token Scoring for Efficient Video VLMs
- 현재글 : [논문리뷰] Video-CoE: Reinforcing Video Event Prediction via Chain of Events
- 다음글 [논문리뷰] VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
댓글