[논문리뷰] VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
링크: 논문 PDF로 바로 열기
저자: Mohamed Eltahir, Ali Habibullah, et al.
키워: Long-Form Video Understanding, Hierarchical Grid, Recursive Language Models, Master-Worker Agents, Logarithmic Compute, Visual Navigation, Video-RLM
1. Key Terms & Definitions (핵심 용어 및 정의)
- VideoAtlas : 비디오를 계층적 그리드(hierarchical grid)로 표현하는 태스크-불가지론적(task-agnostic) 환경으로, 손실 없이(lossless) 탐색 가능하며(navigable), 확장성 있는(scalable) 비디오 이해를 목표로 합니다.
- Video-RLM : VideoAtlas 환경 내에서 작동하는 병렬 Master-Worker 에이전트 아키텍처로, Recursive Language Models (RLMs)를 비디오 도메인으로 확장합니다.
- Hierarchical Grid : VideoAtlas의 핵심 구조로, 재귀적인 KxK 이미지 그리드를 의미합니다. 각 셀은 연속적인 시간 간격(temporal interval)을 나타내며, 비디오 길이에 대해 로그 스케일(logarithmic scale) 로 접근 깊이(access depth)를 제공합니다.
- Recursive Language Models (RLMs) : 재귀적인 서브-에이전트 호출을 통해 임의로 긴 컨텍스트에 쿼리하고 손실 없는 심볼릭 변수를 축적하는 모델로, 본 논문에서는 시각적 도메인으로 확장되었습니다.
- Visual Scratchpad (M+) : VideoAtlas 내의 손실 없는 멀티모달 메모리로, 에이전트가 탐색 라운드 전반에 걸쳐 수집한 증거(evidence) 튜플(이미지, 자막, 타임스탬프, 설명)을 저장합니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
장편 비디오(long-form video)를 이해하는 것은 방대한 시간적 공간 내에서 희소하고 태스크 관련 증거(task-relevant evidence)를 찾아내는 어려운 문제입니다. 기존의 비디오-언어 모델(VLM) 접근 방식은 두 가지 주요 도전 과제에 직면합니다. 첫째, Representation 측면에서, Uniform Sampling 이나 Composite Grids 와 같은 손실 있는(lossy) 근사 방식은 심각한 Temporal Sparsity 를 유발하여 짧은 이벤트나 세밀한 시각적 디테일을 놓치기 쉽습니다. 둘째, Long-Context 처리에서, Caption-based 또는 Agentic-based 파이프라인은 비디오를 텍스트로 변환하여 시각적 충실도(visual fidelity)를 상실합니다. 이러한 방식은 또한 수백 GB의 RAM을 소모하는 Offline Preprocessing 비용이나 비디오 길이에 비례하여 증가하는 캡션 생성 비용과 같은 심각한 확장성 병목 현상(scalability bottlenecks)을 야기합니다. 결과적으로, 기존 연구들은 Lossless , Navigable , Scalable , Caption-free , Preprocessing-free 비디오 표현이라는 핵심 요구사항을 동시에 만족시키지 못합니다.
3. Method & Key Results (제안 방법론 및 핵심 결과)
저자들은 비디오를 계층적인 그리드(hierarchical grid)로 표현하는 태스크-불가지론적 환경인 VideoAtlas 를 제안합니다. 이 환경에서 에이전트는 EXPAND 액션을 통해 선택된 셀(cell)의 하위 그리드(sub-grid)로 재귀적으로 확대(zoom in)하여, O(log T) 스텝 내에 Sub-second Temporal Precision 을 달성합니다. VideoAtlas 는 비디오, 중간 조사(intermediate investigations), 에이전트의 메모리를 모두 동일한 시각적 표현으로 렌더링하여 종단간(end-to-end) 손실 있는 텍스트 변환을 제거합니다.
이 환경에서 Master-Worker Agents (Video-RLM) 아키텍처가 작동합니다. 마스터(Master) 에이전트는 전역 탐색(global exploration)을 조율하고, 워커(Worker) 에이전트들은 할당된 영역을 병렬로 탐색하며 손실 없는 시각적 증거(visual evidence)를 Visual Scratchpad (M+) 에 축적합니다
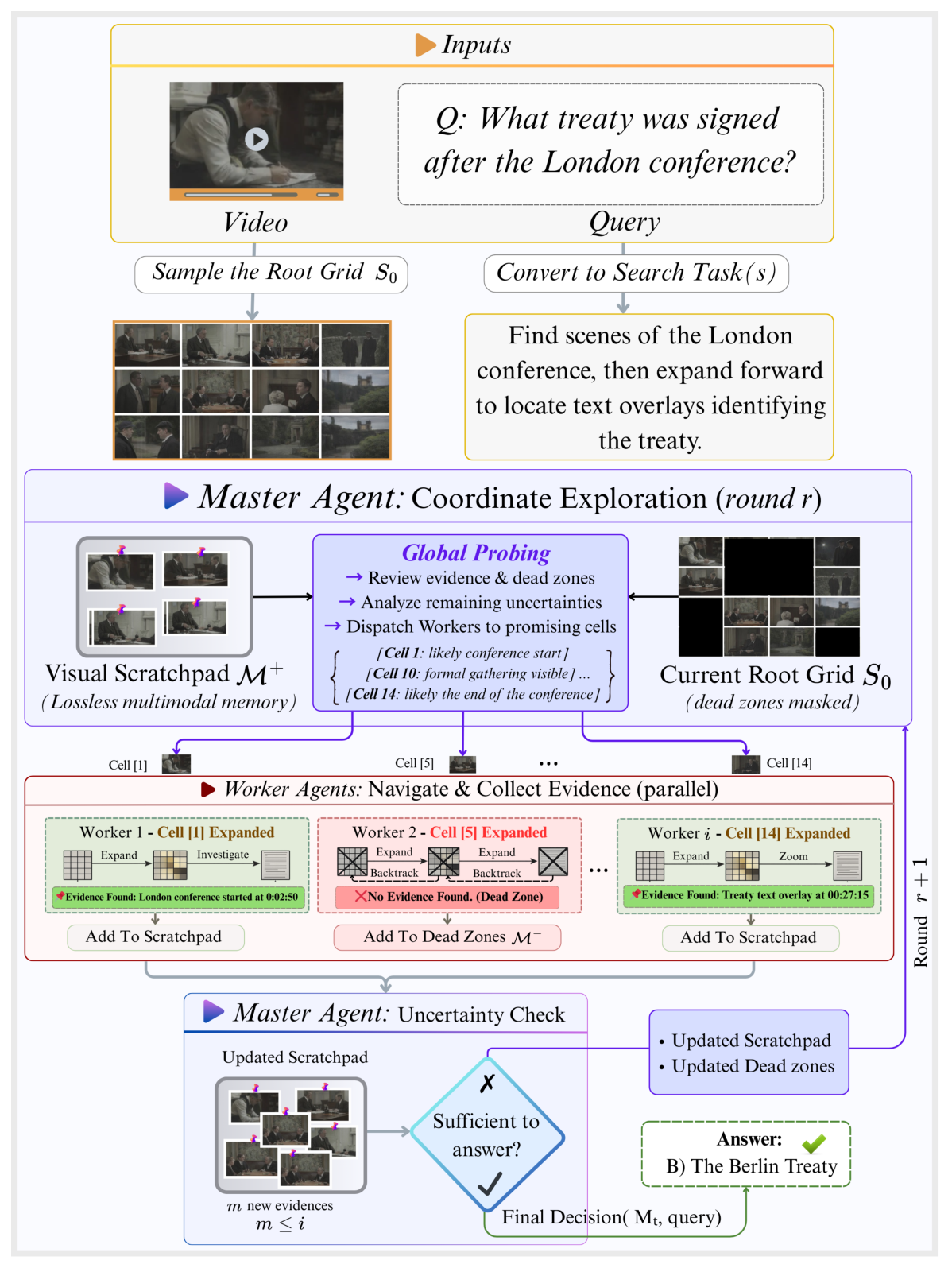 Figure 3: Video-RLM overview. The query is converted into a search task. In each round r, the Master examines the root grid S0 (with dead zones masked) and the scratchpad M+, then assigns promising cells to Workers. Each Worker autonomously explores its assigned region via navigation, perception, and commit actions. After all Workers return, M+ and M¯ are updated. The Master performs an uncertainty analysis: if evidence is sufficient, the final answer is produced. Otherwise, a new round begins.
Figure 3: Video-RLM overview. The query is converted into a search task. In each round r, the Master examines the root grid S0 (with dead zones masked) and the scratchpad M+, then assigns promising cells to Workers. Each Worker autonomously explores its assigned region via navigation, perception, and commit actions. After all Workers return, M+ and M¯ are updated. The Master performs an uncertainty analysis: if evidence is sufficient, the final answer is produced. Otherwise, a new round begins.
. 환경 예산 책정(Environment Budgeting) 을 통해 최대 탐색 깊이(exploration depth d)를 제한하여 Temporal Resolution 과 Compute 를 직접 제어하며, 이는 Compute-Accuracy 의 균형을 맞추는 principled hyperparameter 를 제공합니다 [Figure 4(a)].
핵심 결과는 다음과 같습니다.
- Logarithmic Compute Scaling : Video-RLM 은 비디오 길이에 따라 컴퓨트(compute) 비용이 로그 스케일 로 증가함을 입증합니다
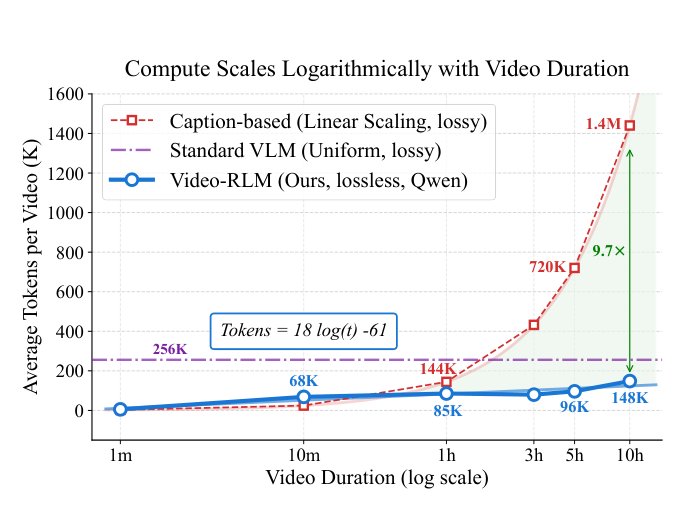 Figure 1: Logarithmic compute scaling with video duration. Video-RLM's hierarchical grid grows sub-linearly (O(log T)), re- quiring up to 9.7× fewer tokens than linear-scaling baselines. A uniform VLM maxes out its 256K context trading off sampled frame count with resolution.
Figure 1: Logarithmic compute scaling with video duration. Video-RLM's hierarchical grid grows sub-linearly (O(log T)), re- quiring up to 9.7× fewer tokens than linear-scaling baselines. A uniform VLM maxes out its 256K context trading off sampled frame count with resolution.
. 10시간 비디오 벤치마크에서 선형 스케일링(linear-scaling) 베이스라인 대비 최대 9.7배 더 적은 토큰 을 필요로 합니다. 2. Duration Robustness : 1시간에서 10시간 벤치마크로 확장할 때, Video-RLM 은 최소한의 정확도 저하를 보이며 가장 견고한(duration-robust) 성능을 유지합니다. 예를 들어, Qwen 백본을 사용한 Video-RLM 은 VMME-10hr에서 -0.7% 의 정확도 저하를 보인 반면, Uniform Sampling 은 -13.2% , LLM over Captions 는 -28.2% (자막 없는 VMME-10hr)의 급격한 성능 저하를 보였습니다
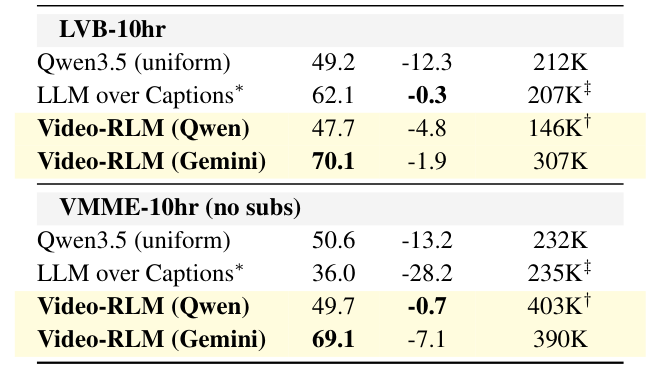 Table 3: 10-hour variant: accuracy (%) and average tokens per question. Δ: accuracy drop from standard benchmarks (Tab. 2).
Table 3: 10-hour variant: accuracy (%) and average tokens per question. Δ: accuracy drop from standard benchmarks (Tab. 2).
. 3. Adaptive Compute Allocation : 시스템은 질의 세분성(question granularity)에 따라 컴퓨트를 적응적으로 할당합니다 [Figure 4(b)]. 예를 들어, 분산된 답변(scattered answers)은 국소화된 답변(localized answers) 대비 40% 더 많은 토큰 을 소비합니다 ( 322K 토큰 vs. 230K 토큰 ). 4. Multimodal Cache Hit Rate : 계층적 그리드의 구조적 재사용(structural reuse)은 30-60% 의 Multimodal Cache Hit Rate 를 달성하여 GPU 컴퓨트 효율성을 더욱 향상시킵니다.
4. Conclusion & Impact (결론 및 시사점)
본 논문은 Long-Form Video Understanding 을 정형화된(formally defined) 계층적 환경 내에서의 시각적 탐색(visual navigation)으로 재구성하는 VideoAtlas 를 제시합니다. 이 환경에서 작동하는 병렬 Master-Worker 에이전트인 Video-RLM 은 비디오 길이에 대한 Logarithmic Compute Growth , 깊이 제어를 통한 Principled Environment Budgeting , 그리고 질의 세분성에 따른 Emergent Adaptive Compute Allocation 이라는 세 가지 핵심 특성을 보여주었습니다. 이 프레임워크는 Lossless , Navigable , Scalable , Caption-free , Preprocessing-free 비디오 이해 패러다임을 제공하며, 기존 VLM 의 확장성 및 충실도(fidelity) 문제를 해결합니다. 나아가, 이는 강화 학습(Reinforcement Learning) 기반의 비디오 이해 연구에 직접적인 경로를 제공하고, 미래 VLM 기술 발전의 강력한 기반을 마련한다는 점에서 학계 및 산업계에 중요한 시사점을 가집니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] LLMs4All: A Review on Large Language Models for Research and Applications in Academic Disciplines
- [논문리뷰] WildCity: A Real-World City-Scale Testbed for Rendering, Simulation, and Spatial Intelligence
- [논문리뷰] Wake up for Touch! Mask-isolated Tactile Alignment Learning in MLLMs
- [논문리뷰] Teaching LLMs a Low-Resource Language: Enhancing Code Completion in Pharo
- [논문리뷰] Sparse Delta Memory: Scaling the State of Linear RNNs through Sparsity
Review 의 다른글
- 이전글 [논문리뷰] Video-CoE: Reinforcing Video Event Prediction via Chain of Events
- 현재글 : [논문리뷰] VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
- 다음글 [논문리뷰] When AI Navigates the Fog of War
댓글