[논문리뷰] Rethinking RL for LLM Reasoning: It's Sparse Policy Selection, Not Capability Learning
링크: 논문 PDF로 바로 열기
메타데이터
저자: Ömer Faruk Akgül, Rajgopal Kannan, Willie Neiswanger, Viktor Prasanna, et al.
1. Key Terms & Definitions (핵심 용어 및 정의)
- RLVR (Reinforcement Learning with Verifiable Rewards): 모델이 생성한 추론 과정의 결과가 정답과 일치하는지를 기준으로 보상을 부여하여 학습하는 표준적인 강화학습 기법입니다.
- Decision Points: 모델의 생성 과정 중, 특정 토큰 위치에서 여러 추론 경로(reasoning branch)를 선택할 수 있는 불확실성이 높은 지점으로, 본 논문에서는 높은 Token-Level Entropy를 가진 위치로 정의합니다.
- Sparse Policy Selection: 강화학습이 새로운 추론 전략을 학습하는 것이 아니라, 베이스 모델이 이미 가지고 있는 여러 경로 중 최적의 경로를 선택(selection)하도록 미세한 수정을 가하는 과정입니다.
- ReasonMaxxer: 강화학습 없이 베이스 모델의 자체 엔트로피를 이용해 Decision Points를 식별하고, 해당 지점에만 Advantage-Weighted Contrastive Loss를 적용하여 학습하는 경량화된 방법론입니다.
2. Motivation & Problem Statement (연구 배경 및 문제 정의)
본 논문은 LLM 추론 능력 향상에 필수적이라고 여겨지는 RL이 실제로 새로운 전략을 학습하는 것이 아니라, 베이스 모델 내에 이미 존재하는 솔루션들의 확률 분포를 재조정하는 것임을 밝힙니다. 기존의 RLVR은 전체 토큰에 대해 비효율적으로 경사 하강법을 수행하지만, 실제 추론 성능 개선은 극히 일부 지점에서 발생합니다. 따라서 저자들은 복잡한 RL 파이프라인 없이도 이러한 sparse한 수정만을 통해 동일한 성능을 달성할 수 있는지, 그리고 RL의 RL optimization loop 자체가 불필요한지를 검증하고자 합니다 [Figure 1].
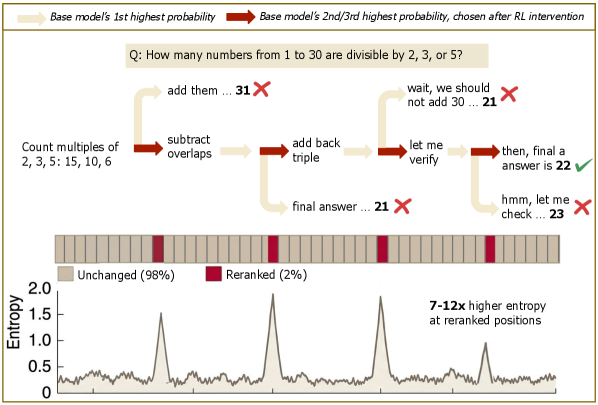
Figure 1 — RL 수정의 희소성과 결정 지점
3. Method & Key Results (제안 방법론 및 핵심 결과)
본 논문은 RL의 핵심적인 학습 효과가 모델의 Decision Points에 집중되어 있다는 점을 식별하고, 이를 바탕으로 ReasonMaxxer를 제안합니다. 제안된 방법론은 강화학습의 전체 루프를 배제하고, 베이스 모델의 Token-Level Entropy를 활용하여 학습이 필요한 중요 지점을 식별합니다. 이후, 학습 데이터 내에서 성공한 rollout과 실패한 rollout 간의 대비를 통해 Advantage-Weighted Contrastive Loss를 해당 지점에만 적용하며, 나머지 위치는 베이스 모델의 분포를 유지하도록 KL-anchor를 사용합니다 [Figure 2]. 주요 실험 결과, ReasonMaxxer는 3개 모델 패밀리와 6개 벤치마크에서 기존 GRPO 또는 PPO 기반의 풀 RL 모델과 대등하거나 능가하는 성능을 보였습니다. 특히, 학습 데이터 규모를 2개 이상의 order of magnitude로 줄였으며, 학습 비용은 RL 대비 약 1/1000 수준으로 감소시켰습니다 [Table 3]. 또한, 학습된 수정 사항이 매우 낮은 차원의 파라미터만으로도 재현 가능함을 LoRA distilled 모델을 통해 입증하였습니다 [Figure 3].
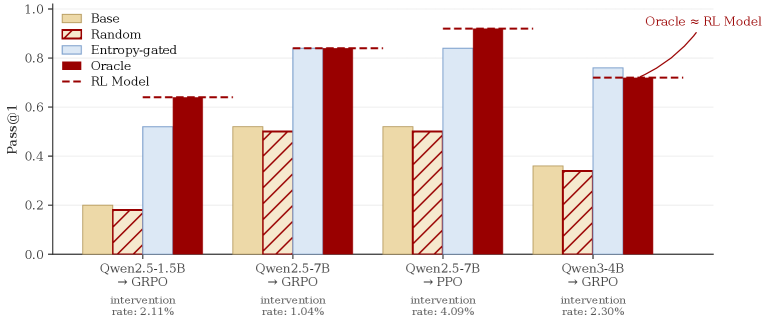
Figure 2 — oracle 및 엔트로피 기반 교정 결과
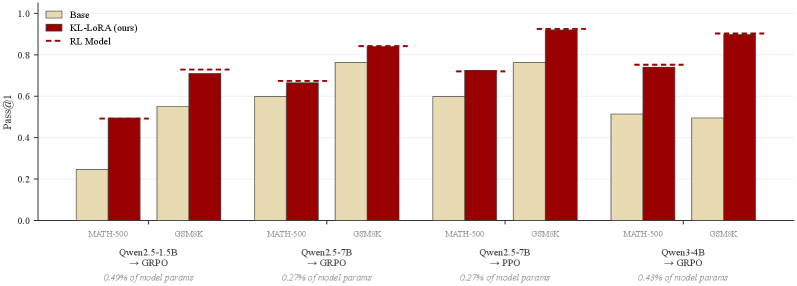
Figure 3 — RL 교정의 저차원성 확인
4. Conclusion & Impact (결론 및 시사점)
본 연구는 LLM의 추론 성능 향상을 위한 강화학습이 본질적으로 복잡한 역량 학습(capability acquisition)이 아닌, Sparse Policy Selection 문제임을 규명하였습니다. 제안된 ReasonMaxxer의 성공은 대규모 강화학습 인프라가 추론 성능 개선의 필수 조건이 아님을 시사합니다. 이러한 결과는 학계 및 산업계에서 보다 효율적이고 경제적인 post-training 방법론을 채택할 수 있는 중요한 기술적 근거를 제시합니다.
⚠️ 알림: 이 리뷰는 AI로 작성되었습니다.
관련 포스트
- [논문리뷰] ESPO: Early-Stopping Proximal Policy Optimization
- [논문리뷰] Learning to Hint for Reinforcement Learning
- [논문리뷰] ThinkTwice: Jointly Optimizing Large Language Models for Reasoning and Self-Refinement
- [논문리뷰] Think Anywhere in Code Generation
- [논문리뷰] Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge
Review 의 다른글
- 이전글 [논문리뷰] R^3-SQL: Ranking Reward and Resampling for Text-to-SQL
- 현재글 : [논문리뷰] Rethinking RL for LLM Reasoning: It's Sparse Policy Selection, Not Capability Learning
- 다음글 [논문리뷰] Rethinking State Tracking in Recurrent Models Through Error Control Dynamics
댓글